









Ein Cluster ist eine Sammlung von ESXi-Hosts und verknüpften virtuellen Maschinen mit gemeinsam genutzten Ressourcen und einer gemeinsamen Verwaltungsoberfläche. Sie müssen einen Cluster erstellen und DRS aktivieren, um die Vorteile der Ressourcenverwaltung auf Clusterebene ausnutzen zu können.
Je nachdem, ob Enhanced vMotion Compatibility (EVC) aktiviert ist, verhält sich DRS anders, wenn Sie virtuelle vSphere Fault Tolerance (vSphere FT)-Maschinen im Cluster verwenden.
| EVC | DRS (Lastausgleich) | DRS (anfängliche Platzierung) |
|---|---|---|
| Aktiviert | Aktiviert (primäre und sekundäre virtuelle Maschinen) | Aktiviert (primäre und sekundäre virtuelle Maschinen) |
| Deaktiviert | Deaktiviert (primäre und sekundäre virtuelle Maschinen) | Deaktiviert (primäre virtuelle Maschine) Vollautomatisiert (sekundäre virtuelle Maschinen) |
Zugangssteuerung und anfängliche Platzierung
Wenn Sie versuchen, eine einzelne virtuelle Maschine oder eine Gruppe von virtuellen Maschinen in einem DRS-aktivierten Cluster einzuschalten, führt vCenter Server die Zugangssteuerung durch. Dabei wird geprüft, ob der Cluster über ausreichende Ressourcen für die virtuelle(n) Maschine(n) verfügt.
Sollten die Ressourcen im Cluster zum Einschalten einer einzigen virtuellen Maschine oder einer der virtuellen Maschine in einer Gruppe nicht ausreichen, wird eine Meldung angezeigt. Anderenfalls empfiehlt DRS für jede virtuelle Maschine einen Host zum Ausführen der virtuellen Maschine und unternimmt eine der folgenden Aktionen:
- Führt die Platzierungsempfehlung automatisch aus.
- Zeigt die Platzierungsempfehlung an, sodass der Benutzer auswählen kann, ob er sie annehmen oder überschreiben möchte.
Hinweis: Es werden keine Empfehlungen zur anfänglichen Platzierung für virtuelle Maschinen auf eigenständigen Hosts oder in Nicht-DRS-Clustern ausgegeben. Beim Einschalten werden diese auf dem Host platziert, auf dem sie sich derzeit befinden.
- DRS berücksichtigt die Netzwerkbandbreite. Durch die Berechnung der Netzwerksättigung ist DRS in der Lage, bessere Entscheidungen bei der Platzierung zu treffen. Ein umfangreicheres Verständnis der Umgebung kann helfen, Leistungsbeeinträchtigungen von virtuellen Maschinen zu vermeiden.
Einschalten einer einzelnen virtuellen Maschine
In einem DRS-Cluster können Sie eine einzelne virtuelle Maschine einschalten und Empfehlungen für die anfängliche Platzierung erhalten.
Wenn Sie eine einzelne virtuelle Maschine einschalten, gibt es zwei Arten von Empfehlungen zur anfänglichen Platzierung:
-
Es wird eine einzelne virtuelle Maschine eingeschaltet, es sind keine vorbereitenden Schritte erforderlich.
Dem Benutzer wird eine Liste sich gegenseitig ausschließender Platzierungsempfehlungen für die virtuelle Maschine angezeigt. Sie können nur eine Empfehlung auswählen.
-
Es wird eine einzelne virtuelle Maschine eingeschaltet, es sind jedoch vorbereitende Schritte erforderlich.
Zu diesen Schritten gehören das Versetzen eines Hosts in den Standby-Modus oder das Migrieren anderer virtueller Maschinen zwischen Hosts. In diesem Fall haben die Empfehlungen mehrere Zeilen, die jede der vorausgesetzten Aktionen aufführen. Der Benutzer kann entweder die gesamte Empfehlung akzeptieren oder das Einschalten der virtuellen Maschine abbrechen.
Gruppeneinschaltung
Sie können versuchen, mehrere virtuelle Maschinen gleichzeitig einzuschalten (Gruppeneinschaltung).
Die für einen Gruppeneinschaltvorgang ausgewählten virtuellen Maschinen müssen sich nicht im selben DRS-Cluster befinden. Sie können aus verschiedenen Clustern ausgewählt werden, müssen sich aber im selben Datencenter befinden. Es können auch virtuelle Maschinen in Nicht-DRS-Clustern oder auf eigenständigen Hosts eingeschaltet werden. Diese virtuellen Maschinen werden automatisch eingeschaltet und es wird keine Empfehlung zur anfänglichen Platzierung ausgegeben.
Die Empfehlungen zur anfänglichen Platzierung für Gruppeneinschaltvorgänge werden auf Clusterbasis gegeben. Wenn alle platzierungsbezogenen Schritte für einen Gruppeneinschaltvorgang im automatischen Modus ablaufen, werden die virtuellen Maschinen ohne Empfehlung zur anfänglichen Platzierung eingeschaltet. Wenn platzierungsbezogene Schritte für alle virtuellen Maschinen im manuellen Modus ablaufen, werden alle virtuellen Maschinen (einschließlich der virtuellen Maschinen, die sich im automatischen Modus befinden) manuell eingeschaltet. Diese Aktionen werden in einer Empfehlung zur anfänglichen Platzierung erläutert.
Für jeden DRS-Cluster, dem die einzuschaltenden virtuellen Maschinen angehören, gibt es eine individuelle Einzelempfehlung, die alle vorbereitenden Schritte umfasst (oder keine Empfehlung). Sämtliche dieser clusterspezifischen Empfehlungen werden zusammen auf der Registerkarte Empfehlungen zum Einschalten angezeigt.
Wenn ein nicht automatischer Gruppeneinschaltversuch unternommen wird und virtuelle Maschinen beteiligt sind, für die keine Empfehlung zur anfänglichen Platzierung ausgegeben wurde (d. h. die virtuellen Maschinen auf eigenständigen Hosts oder in Nicht-DRS-Clustern), versucht vCenter Server, diese automatisch einzuschalten. Falls der Einschaltvorgang erfolgreich ist, werden die virtuellen Maschinen auf der Registerkarte Erfolgreiche Einschaltvorgänge angezeigt. Alle virtuellen Maschinen, bei denen das Einschalten fehlschlägt, werden auf der Registerkarte Fehlgeschlagene Einschaltvorgänge angezeigt.
Gruppeneinschaltung
Der Benutzer wählt drei virtuelle Maschinen aus demselben Datencenter für einen Gruppeneinschaltvorgang aus. Die ersten beiden virtuellen Maschinen (VM1 und VM2) befinden sich im selben DRS-Cluster (Cluster1), während die dritte virtuelle Maschine (VM3) ein eigenständiger Host ist. VM1 befindet sich im automatischen und VM2 im manuellen Modus. In diesem Szenario wird dem Benutzer eine Empfehlung zur anfänglichen Platzierung für Cluster1 angezeigt (auf der Registerkarte Empfehlungen zu Einschaltvorgängen), die Aktionen zum Einschalten von VM1 und VM2 umfasst. Es wird versucht, VM3 automatisch einzuschalten. Ist dies erfolgreich, wird VM3 auf der Registerkarte Erfolgreiche Einschaltvorgänge aufgeführt. Schlägt der Versuch fehl, wird die virtuelle Maschine auf der Registerkarte Fehlgeschlagene Einschaltversuche aufgelistet.
Migrieren von virtuellen Maschinen
Obwohl DRS anfängliche Platzierungen vornimmt, sodass die Last im Cluster gleichmäßig verteilt ist, können Änderungen an der Last der virtuellen Maschine und der Verfügbarkeit von Ressourcen zu einer ungleichmäßigen Lastverteilung führen. DRS generiert Migrationsempfehlungen, um eine ungleichmäßige Lastverteilung auszugleichen.
Wenn DRS auf dem Cluster aktiviert wird, kann die Last gleichmäßiger verteilt werden, um das Ungleichgewicht zu reduzieren. Beispielsweise sind die drei Hosts auf der linken Seite der folgenden Abbildung unausgewogen. Angenommen, Host 1, Host 2 und und 3 verfügen über identische Kapazitäten und alle virtuellen Maschinen über dieselbe Konfiguration und Last (dazu gehört die Reservierung, sofern festgelegt). Trotzdem sind die Ressourcen von Host 1 überansprucht, da sechs virtuelle Maschinen vorhanden sind, während auf Host 2 und Host 3 ausreichend Ressourcen zur Verfügung stehen. DRS migriert deshalb virtuelle Maschinen von Host 1 auf Host 2 und Host 3 (bzw. empfiehlt diese Migration). Rechts in der Abbildung erscheint das Ergebnis der ordnungsgemäßen Lastausgleichskonfiguration der Hosts.
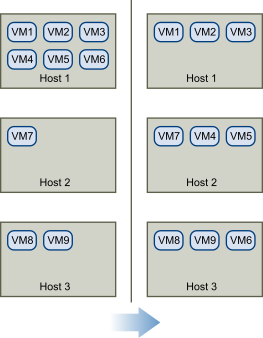
Im Falle eines Ungleichgewichts bei einem Cluster gibt DRS – je nach Automatisierungsebene – Empfehlungen aus oder migriert die virtuellen Maschinen:
- Wenn es sich um einen manuellen oder teilautomatisierten Cluster handelt, führt vCenter Server keine automatischen Aktionen zum Ausgleich der Ressourcen durch. Vielmehr wird auf der Seite „Übersicht“ darauf hingewiesen, dass Migrationsempfehlungen verfügbar sind. Auf der Seite „DRS-Empfehlungen“ werden die Änderungsempfehlungen angezeigt, die zur effizientesten Ressourcennutzung innerhalb des Clusters führen.
-
Wenn es sich um einen Cluster und virtuelle Maschinen handelt, die vollautomatisiert sind, migriert vCenter Server ausgeführte virtuelle Maschinen bei Bedarf zwischen den Hosts, um eine effiziente Nutzung der Clusterressourcen sicherzustellen.
Hinweis: Auch bei der Einrichtung einer automatischen Migration können Benutzer einzelne virtuelle Maschinen explizit migrieren, allerdings könnte vCenter Server diese virtuellen Maschinen bei der Optimierung von Clusterressourcen auf andere Hosts verschieben.
Standardmäßig wird die Automatisierungsebene für den gesamten Cluster festgelegt. Für einzelne virtuelle Maschinen kann auch eine benutzerdefinierte Automatisierungsebene festgelegt werden.
DRS-Migrationsschwellenwert
Der DRS-Migrationsschwellenwert ermöglicht Ihnen das Festlegen der Empfehlungen, die erzeugt und dann angewendet werden (wenn die virtuellen Maschinen, die von der Empfehlung betroffen sind, sich im vollautomatisierten Modus befinden) oder angezeigt werden (im manuellen Modus). Dieser Schwellenwert gilt als Maß für die Aggressivität, mit der DRS Migrationen zur Verbesserung der VM-Zufriedenheit empfiehlt.
Sie können den Schwellenwert-Schieberegler verschieben, um eine von fünf Einstellungen zu verwenden, von „Konservativ“ bis „Aggressiv“. Je höher die Einstellung für die Aggressivität, desto häufiger empfiehlt DRS Migrationen zur Verbesserung der VM-Zufriedenheit. Die Einstellung „Konservativ“ erzeugt nur Empfehlungen mit Priorität 1 (obligatorische Empfehlungen).
Nachdem eine Empfehlung eine Prioritätsebene erhält, wird diese Ebene mit dem von Ihnen festgelegten Migrationsschwellenwert verglichen. Wenn die Prioritätsebene niedriger oder gleich der Einstellung des Schwellenwerts ist, wird die Empfehlung entweder angewendet (wenn die relevanten virtuellen Maschinen sich im vollautomatisierten Modus befinden) oder dem Benutzer zur Bestätigung angezeigt (im manuellen oder teilautomatisierten Modus).
DRS-Punktzahl
Jede Migrationsempfehlung wird unter Verwendung der VM-Zufriedenheitsmetrik berechnet, die die Ausführungseffizienz misst. Diese Metrik wird als DRS-Punktzahl auf der Registerkarte „Übersicht“ des Clusters im vSphere Client angezeigt. Mit Empfehlungen zum DRS-Lastausgleich wird versucht, die DRS-Punktzahl einer VM zu verbessern. Bei der DRS-Punktzahl des Clusters handelt es sich um einen gewichteten Durchschnitt der DRS-Punktzahlen aller eingeschalteten VMs im Cluster. Die DRS-Punktzahl des Clusters steht in der Messanzeige zur Verfügung. Die Farbe des ausgefüllten Abschnitts ändert sich je nach dem Wert, der mit dem entsprechenden Balken im Histogramm „DRS-Punktzahl der VM“ übereinstimmt. Die Balken im Histogramm zeigen den Prozentsatz der VMs an, die über eine DRS-Punktzahl in diesem Bereich verfügen. Sie können die Liste mit serverseitiger Sortierung und Filterung anzeigen, indem Sie die Registerkarte „Überwachen“ des Clusters und vSphere DRS auswählen, um eine Liste der VMs im Cluster zu erhalten, die nach DRS-Punktzahl in aufsteigender Reihenfolge sortiert sind.
Migrationsempfehlungen
Bei der Erstellung eines Clusters im standardmäßigen manuellen oder teilautomatisierten Modus zeigt vCenter Server auf der Seite „DRS-Empfehlungen“ Migrationsempfehlungen an.
Das System liefert so viele Empfehlungen, wie für die Durchsetzung von Regeln und dem Ressourcenausgleich des Clusters erforderlich sind. Jede Empfehlung enthält die zu verschiebende virtuelle Maschine, den aktuellen Host (Quellhost) und den Zielhost sowie einen Grund für die Empfehlung. Folgende Gründe sind möglich:
- Ausgleichen der durchschnittlichen CPU-Lasten oder -Reservierungen.
- Ausgleichen der durchschnittlichen Arbeitsspeicherlasten oder -reservierungen.
- Anwenden von Ressourcenpoolreservierungen.
- Eine Affinitätsregel anwenden.
- Der Host wechselt in den Wartungs- oder Standby-Modus.
DRS-Cluster-Anforderungen
Zu einem DRS-Cluster hinzugefügte Hosts müssen bestimmte Voraussetzungen erfüllen, damit Clusterfunktionen erfolgreich verwendet werden können.
Gemeinsam genutzter Speicher, Anforderungen
Für einen DRS-Cluster gelten bestimmte Anforderungen hinsichtlich des gemeinsam genutzten Speichers.
Stellen Sie sicher, dass die verwalteten Hosts einen gemeinsamen Speicher nutzen. Gemeinsam genutzter Speicher befindet sich im Allgemeinen in einem SAN, er kann jedoch auch über gemeinsam genutzte NAS-Speicher implementiert werden.
Siehe die Dokumentation zu vSphere-Speicher für Informationen zu anderen gemeinsam genutzten Speichern.
Anforderungen an gemeinsam genutzte VMFS-Volumes
Für einen DRS-Cluster gelten bestimmte Anforderungen hinsichtlich des gemeinsam genutzten VMFS-Volumes.
Konfigurieren Sie für die Verwendung gemeinsam genutzter VMFS-Volumes alle verwalteten Hosts.
- Platzieren Sie die Festplatten aller virtuellen Maschinen auf VMFS-Volumes, auf die Quell- und Zielhosts zugreifen können.
- Stellen Sie sicher, dass das VMFS-Volume groß genug ist, um alle virtuellen Festplatten der virtuellen Maschinen zu speichern.
- Stellen Sie sicher, dass die VMFS-Volumes auf den Quell- und Zielhosts Volume-Namen verwenden und diese durch alle virtuellen Maschinen beim Festlegen der virtuellen Festplatten verwendet werden.
.vmdk). Diese Anforderung gilt nicht, wenn alle Quell- und Zielhosts über ESX Server 3.5 oder höher verfügen und die lokale Auslagerung auf einem Host verwenden. In diesem Fall wird vMotion mit Auslagerungsdateien auf einem nicht gemeinsam genutzten Speicher unterstützt. Die Auslagerungsdateien werden standardmäßig auf einem VMFS-Volume abgelegt. Möglicherweise wurde dieser Dateispeicherort jedoch durch den Administrator mithilfe erweiterter Konfigurationsoptionen für virtuelle Maschinen überschrieben.
Anforderungen an die Prozessorkompatibilität
Für DRS-Cluster gelten bestimmte Anforderungen hinsichtlich der Prozessorkompatibilität.
Sie müssen die Kompatibilität der Prozessoren von Quell- und Zielhosts im Cluster maximieren, damit die Funktionen von DRS nicht eingeschränkt werden.
vMotion überträgt den laufenden architektonischen Zustand einer virtuellen Maschine zwischen zugrunde liegenden ESXi-Hosts. vMotion-Kompatibilität bedeutet folglich, dass die Prozessoren des Zielhosts in der Lage sein müssen, die Ausführung anhand gleichwertiger Anweisungen an der Stelle fortzusetzen, an der die Prozessoren des Quellhosts angehalten wurden. Die Taktfrequenzen der Prozessoren sowie die Cachegrößen können zwar unterschiedlich sein, allerdings müssen die Prozessoren derselben Herstellerkategorie (Intel oder AMD) und derselben Prozessorfamilie entsprechen, um für die Migration mit vMotion kompatibel zu sein.
Prozessorfamilien werden von den Prozessoranbietern definiert. Sie können verschiedene Prozessorversionen aus derselben Familie unterscheiden, indem Sie Prozessormodell, Stepping-Level und erweiterte Funktionen vergleichen.
Manchmal wurden durch die Prozessorhersteller innerhalb derselben Prozessorfamilie signifikante Änderungen an der Architektur eingeführt (wie z. B. 64-Bit-Erweiterungen und SSE3). VMware identifiziert solche Ausnahmen, falls eine erfolgreiche Migration mit vMotion nicht garantiert werden kann.
vCenter Server bietet Funktionen um sicherzustellen, dass die mit vMotion migrierten virtuellen Maschinen die Anforderungen an die Prozessorkompatibilität erfüllen. Zu diesen Funktionen zählen:
- Enhanced vMotion Compatibility (EVC) – Mithilfe der EVC-Funktion können Sie vMotion-Kompatibilität für die Hosts in einem Cluster sicherstellen. EVC stellt sicher, dass alle Hosts in einem Cluster denselben CPU-Funktionssatz gegenüber der virtuellen Maschine offenlegen – selbst dann, wenn die tatsächlichen CPUs auf den Hosts abweichen. Auf diese Weise wird verhindert, dass mit vMotion durchgeführte Migrationen aufgrund nicht kompatibler CPUs fehlschlagen.
Konfigurieren Sie EVC über das Dialogfeld mit den Clustereigenschaften. Die Hosts müssen innerhalb des Clusters bestimmte Anforderungen erfüllen, damit der Cluster EVC verwenden kann. Weitere Informationen zu EVC und EVC-Anforderungen finden Sie unter vCenter Server und Hostverwaltung.
- CPU-Kompatibilitätsmasken – vCenter Server vergleicht die für eine virtuelle Maschine verfügbaren CPU-Funktionen mit den CPU-Funktionen des Zielhosts, um zu ermitteln, ob Migrationen mit vMotion zulässig sind oder nicht. Durch die Anwendung von CPU-Kompatibilitätsmasken auf einzelne virtuelle Maschinen können bestimmte CPU-Funktionen für die virtuelle Maschine ausgeblendet werden, um das potenzielle Fehlschlagen von Migrationen mit vMotion aufgrund von nicht kompatiblen CPUs zu verhindern.
vMotion-Anforderungen für DRS-Cluster
Ein DRS-Cluster hat bestimmte vMotion-Anforderungen.
Die Hosts in Ihrem Cluster müssen Teil eines vMotion-Netzwerks sein, damit die Verwendung der DRS-Migrationsempfehlungen aktiviert werden kann. Falls die Hosts zu keinem vMotion-Netzwerk gehören, kann DRS dennoch Empfehlungen zur anfänglichen Platzierung ausgeben.
Jeder Host des Clusters muss im Hinblick auf die vMotion-Konfiguration folgende Anforderungen erfüllen:
- vMotion unterstützt keine Raw-Festplatten oder die Migration von Anwendungen, die über Microsoft Cluster Service (MSCS) geclustert wurden.
- vMotion benötigt ein privates Gigabit-Ethernet-Migrationsnetzwerk zwischen allen vMotion-fähigen, verwalteten Hosts. Wenn vMotion auf einem verwalteten Host aktiviert ist, konfigurieren Sie ein eindeutiges Netzwerkkennungsobjekt für den verwalteten Host und verbinden Sie ihn mit dem privaten Migrationsnetzwerk.
Konfigurieren von DRS mit virtuellem Flash
DRS kann virtuelle Maschinen mit Reservierungen für virtuelles Flash verwalten.
Die vFlash-Kapazität wird als Statistik angezeigt, die der Host regelmäßig an den vSphere Client meldet. Bei jeder Ausführung von DRS wird der zuletzt gemeldete Kapazitätswert verwendet.
Sie können eine vFlash-Ressource pro Host konfigurieren. Dies bedeutet, dass DRS beim Einschalten der virtuellen Maschine keine Auswahl zwischen verschiedenen vFlash-Ressourcen auf einem bestimmten Host treffen muss.
DRS wählt einen Host, dessen verfügbare vFlash-Kapazität ausreichend ist, um die virtuelle Maschine zu starten. Wenn DRS die vFlash-Reservierung einer virtuellen Maschine nicht erfüllen kann, kann sie nicht eingeschaltet werden. DRS geht bei einer eingeschalteten virtuellen Maschine mit vFlash-Reservierung davon aus, dass diese eine weiche Affinität mit ihrem aktuellen Host besitzt. DRS empfiehlt eine solche virtuelle Maschine nicht für vMotion, es sei denn, es liegt ein obligatorischer Grund vor, beispielsweise wenn ein Host in den Wartungsmodus versetzt werden muss oder wenn die Last eines überlasteten Hosts verringert werden muss.
Erstellen eines Clusters
Ein Cluster ist eine Gruppe von Hosts. Wenn Sie einem Cluster einen Host hinzufügen, werden die Ressourcen des Hosts zu den Ressourcen des Clusters hinzugefügt. Der Cluster verwaltet die Ressourcen aller zugehörigen Hosts.
Voraussetzungen
- Stellen Sie sicher, dass Sie über ausreichende Berechtigungen zum Erstellen eines Clusterobjekts verfügen.
- Stellen Sie sicher, dass in der Bestandsliste ein Datencenter vorhanden ist.
- Wenn Sie vSAN verwenden möchten, muss es aktiviert werden, bevor Sie vSphere HA konfigurieren.
Prozedur
Ergebnisse
Der Cluster wird zur Bestandsliste hinzugefügt.
Nächste Maßnahme
Bearbeiten von Clustereinstellungen
Wenn Sie einen Host zu einem DRS-Cluster hinzufügen, werden die Ressourcen des Hosts zu den Ressourcen des Clusters hinzugefügt. Zusätzlich zu dieser Ressourcenansammlung können Sie mithilfe eines DRS-Clusters clusterweite Ressourcenpools unterstützen und Ressourcenzuteilungsrichtlinien auf Clusterebene festlegen.
Die folgenden Ressourcenverwaltungsfunktionen auf Clusterebene sind ebenfalls verfügbar.
- Lastausgleich
- Die Verteilung und Verwendung von CPU- und Arbeitsspeicherressourcen für alle Hosts und virtuelle Maschinen im Cluster werden kontinuierlich überwacht. DRS vergleicht diese Metriken mit einer idealen Ressourcennutzung, die sich aus den Attributen der Ressourcenpools und der virtuellen Maschinen des Clusters, des aktuellen Bedarfs sowie aus Ziel des Ungleichgewichts ergibt. DRS stellt dann Empfehlungen bereit oder führt entsprechende Migrationen für virtuelle Maschinen aus. Weitere Informationen hierzu finden Sie unter Migrieren von virtuellen Maschinen. Wird eine virtuelle Maschine im Cluster eingeschaltet, versucht DRS, einen ordnungsgemäßen Lastausgleich aufrechtzuerhalten, indem er entweder eine geeignete Platzierung der virtuellen Maschine vornimmt oder eine entsprechende Empfehlung ausgibt. Weitere Informationen hierzu finden Sie unter Zugangssteuerung und anfängliche Platzierung.
- Energieverwaltung
- Wenn die Funktion vSphere Distributed Power Management (DPM) aktiviert ist, vergleicht DRS die Kapazitäten auf Cluster- und Hostebene mit dem Bedarf der virtuellen Maschinen im Cluster. Hierbei wird auch der Bedarfsverlauf der letzten Zeit berücksichtigt. DRS empfiehlt Ihnen anschließend, Hosts in den Standby-Modus zu versetzen. Wenn Überkapazitäten vorhanden sind, werden die Hosts automatisch in den Standby-Modus versetzt. DRS schaltet Hosts ein, wenn mehr Kapazität benötigt wird. Je nach Empfehlungen für den Hostenergiestatus müssen virtuelle Maschinen möglicherweise auf einen Host migriert oder von diesem verschoben werden. Weitere Informationen hierzu finden Sie unter Verwalten von Energieressourcen.
- Affinitätsregeln
- Durch die Verwendung von Affinitätsregeln können Sie die Platzierung von virtuellen Maschinen auf Hosts innerhalb eines Clusters steuern. Weitere Informationen hierzu finden Sie unter Verwenden von Affinitätsregeln mit vSphere DRS.
Voraussetzungen
Prozedur
Nächste Maßnahme
Sie können die Arbeitsspeichernutzung für DRS im vSphere Client anzeigen. Weitere Informationen finden Sie unter:
Festlegen einer benutzerdefinierten Automatisierungsebene für eine virtuelle Maschine
Nachdem Sie einen DRS-Cluster erstellt haben, können Sie die Automatisierungsebene für einzelne virtuelle Maschinen anpassen, um den standardmäßigen Automatisierungsmodus des Clusters außer Kraft zu setzen.
So können Sie zum Beispiel für bestimmte virtuelle Maschinen in einem vollautomatisierten Cluster Manuell oder für bestimmte virtuelle Maschinen in einem manuellen Cluster Teilautomatisiert auswählen.
Wenn eine virtuelle Maschine auf Deaktiviert gesetzt ist, führt vCenter Server keine Migration dieser virtuellen Maschine durch bzw. bietet keine entsprechenden Migrationsempfehlungen an.
Prozedur
Ergebnisse
Andere VMware-Produkte oder Funktionen, z. B. vSphere vApp und vSphere Fault Tolerance, können die Automatisierungsebenen von virtuellen Maschinen in einem DRS-Cluster möglicherweise außer Kraft setzen. Weitere Informationen finden Sie in der produktspezifischen Dokumentation.
Deaktivieren von DRS
Sie können DRS für ein Cluster deaktivieren.
Wenn DRS deaktiviert ist:
- DRS-Affinitätsregeln werden nicht entfernt, sondern erst angewendet, wenn DRS erneut aktiviert wird.
- Host- und VM-Gruppen werden nicht entfernt, sondern erst angewendet, wenn DRS erneut aktiviert wird.
- Ressourcenpools werden dauerhaft aus dem Cluster entfernt. Damit Sie die Ressourcenpools nicht verlieren, speichern Sie einen Snapshot der Ressourcenpoolstruktur auf Ihrem lokalen Computer. Sie können mithilfe des Snapshots den Ressourcenpool wiederherstellen, wenn Sie DRS aktivieren.
Prozedur
- Navigieren Sie zum Cluster im vSphere Client.
- Klicken Sie auf die Registerkarte Konfigurieren und anschließend auf Dienste.
- Klicken Sie unter vSphere DRS auf Bearbeiten.
- Heben Sie die Aktivierung des Kontrollkästchens vSphere DRS einschalten auf.
- Klicken Sie auf OK, um DRS zu deaktivieren.
- (Optional) Wählen Sie eine Option, um den Ressourcenpool zu speichern.
- Klicken Sie auf Ja, um den Snapshot der Ressourcenpoolstruktur auf einem lokalen Computer zu speichern.
- Klicken Sie auf Nein, um DRS zu deaktivieren, ohne dass dabei der Snapshot der Ressourcenpoolstruktur gespeichert wird.
Ergebnisse
Wiederherstellen einer Ressourcenpoolstruktur
Sie können einen zuvor gespeicherten Snapshot einer Ressourcenpoolstruktur wiederherstellen.
Voraussetzungen
- vSphere DRS muss eingeschaltet sein.
- Sie können einen Snapshot nur in demselben Cluster wiederherstellen, in dem er erstellt wurde.
- Es befinden sich keine anderen Ressourcenpools im Cluster.
- Sicherung und Wiederherstellung müssen immer auf derselben Version von vCenter und ESXi durchgeführt werden.
Prozedur
- Navigieren Sie zum Cluster im vSphere Client.
- Klicken Sie mit der rechten Maustaste auf das Cluster und wählen Sie Ressourcenpoolstruktur wiederherstellen.
- Klicken Sie auf Durchsuchen und navigieren Sie zur Snapshot-Datei auf Ihrer lokalen Maschine.
- Klicken Sie auf Öffnen.
- Klicken Sie auf OK, um die Ressourcenpoolstruktur wiederherzustellen.
DRS-Awareness vSAN Stretched Cluster
DRS Awareness vSAN Stretched Cluster ist auf Stretched Clustern mit aktivierter DRS verfügbar. Ein vSAN Stretched Cluster hat Leselokalität, wobei die VM Daten von einer lokalen Site liest. Durch das Abrufen von Lesezugriffen von einer Remote-Site kann die VM-Leistung beeinträchtigt werden. Mit DRS Awareness of vSAN Stretched Cluster kennt DRS jetzt die VM-Lese-Lokalität vollständig und platziert somit die VM auf einer Site, auf der die Lese-Lokalität in vollem Umfang vorhanden ist. Dies geschieht automatisch, es gibt keine konfigurierbaren Optionen. DRS Awareness vSAN Stretched Cluster funktioniert mit den vorhandenen Affinitätsregeln. Dies funktioniert auch mit VMware Cloud on AWS.
vSAN Stretched Cluster mit vSphere HA und vSphere DRS bieten Ausfallsicherheit, indem für den Fall von Fehlern zwei Kopien der Daten über zwei Fehlerdomänen und einen Zeugenknoten in einer dritten Fehlerdomäne verteilt sind. Die beiden aktiven Fehlerdomänen ermöglichen die Replizierung von Daten, sodass beide Fehlerdomänen über eine aktuelle Kopie der Daten verfügen.
vSAN Stretched Cluster bietet eine automatisierte Methode zum Verschieben von Arbeitslasten innerhalb der beiden Fehlerdomänen. Bei vollständigen Site-Ausfällen werden VMs von vSphere HA auf der sekundären Site neu gestartet. Dadurch ist sichergestellt, dass es keine Ausfallzeiten für kritische Produktionsarbeitslasten gibt. Sobald die primäre Site wieder online ist, gleicht DRS die VMs mit sanften Affinitätshosts sofort wieder mit der primäre Site ab. Dieser Vorgang führt dazu, dass die VM von der sekundären Site liest und schreibt, während die VM-Datenkomponenten noch neu erstellt werden, wodurch die VM-Leistung beeinträchtigt werden kann.
In Versionen vor vSphere 7.0 U2 wird empfohlen, DRS vom vollautomatisierten in den teilautomatisierten Modus wechseln zu lassen, um zu vermeiden, dass VMs migriert werden, während eine Neusynchronisierung auf die primäre Site ausgeführt wird. Legen Sie DRS erst nach Abschluss der Neusynchronisierung auf „vollautomatisiert“ fest.
DRS Awareness of vSAN Stretched Cluster führt eine vollständig automatisierte Lese-Lokalitätslösung zur Wiederherstellung nach Ausfällen in einem vSAN Stretched Cluster ein. Die Informationen zur Lese-Lokalität verweisen auf die Hosts, auf die die VM voll zugreifen kann, und DRS verwendet diese Informationen, wenn eine VM auf einem Host auf vSAN Stretched Clustern platziert wird. DRS verhindert, dass VMs auf die primäre Site zurückfallen, während die vSAN-Neusynchronisierung in der Site-Wiederherstellungsphase noch läuft. DRS migriert eine VM automatisch zurück zur primären affinen Site, wenn ihre Datenkomponenten die vollständige Lese-Lokalität erreicht haben. Auf diese Weise können Sie DRS im vollautomatischen Modus betreiben, falls eine vollständige Site ausfallen sollte.
Bei partiellen Site-Ausfällen identifiziert vSphere DRS die VMs, die eine sehr hohe Lesebandbreite belegen und versucht, sie wieder mit der sekundären Site abzugleichen, wenn die VM die Lese-Lokalität aufgrund eines Verlusts von Datenkomponenten größer als oder gleich ihrem Wert für „Zu tolerierende Fehler“ verliert. Dadurch ist sichergestellt, dass VMs mit einer hohen Lesearbeitslast bei partiellen Site-Ausfällen nicht beeinträchtigt werden. Sobald die primäre Site wieder online ist und die Datenkomponenten die Neusynchronisierung abgeschlossen haben, wird die VM wieder zurück zu der Site verschoben, zu der sie affin ist.
DRS-Platzierung von vGPUs
DRS verteilt vGPU-VMs auf die Hosts eines Clusters.
DRS verteilt vGPU-VMs auf eine prinzipiell breite Art und Weise auf die Hosts eines Clusters. Die fraktionierte vGPU-Profilzuteilung für eine VM unterliegt möglicherweise Regeln für den gegenseitigen Ausschluss homogener Profile.
- Migrieren Sie vGPU-VMs manuell auf einen gewünschten Host, um nicht verwendete physische GPU-Kapazität zu öffnen.
- Verwenden Sie dieselbe vGPU-Profilkonfiguration in allen vGPU-VMs in einem Cluster.
- Aktivieren Sie "GPU-Konsolidierung" des Hosts. Weitere Informationen finden Sie unter Konfigurieren von Host-Grafiken.
- Wenn DRS Automation aktiv ist, sollten Sie den Cluster oder die VM in den Modus Teilweise automatisiert versetzen. Weitere Informationen finden Sie unter Bearbeiten von Clustereinstellungen.
DRS Overhead-Speicherverwaltung für VMs
In vSphere 8.0 U3 verfügt DRS über eine verbesserte Overhead-Speicherverwaltung für VMs, die neu konfiguriert werden.
In VMware vSphere bezeichnet Overhead-Speicher den Arbeitsspeicher, der von ESXi für das Verwalten einer virtuellen Maschine (VM) verwendet wird. Dieser Arbeitsspeicher ist erforderlich, damit ESXi seine Funktionen ausführen kann und vom Gast-Speicher getrennt ist, der den VMs zugeteilt ist. Der Umfang des Overhead-Speichers hängt von mehreren Faktoren ab, wie der Anzahl der virtuellen CPUs (vCPUs), die Größe des der VM zugeteilten Arbeitsspeichers und der Konfiguration und Hardwareversion der VM. Mehr vCPUs und größere Arbeitsspeicherzuteilungen führen zu einem höheren Verbrauch an Overhead-Speicher. In vSphere arbeitet DRS mit der ESXi-Speicherverwaltung zusammen, um eine optimale Overhead-Speichernutzung der VM sicherzustellen. DRS verwaltet den Overhead-Speicher, indem ein Grenzwert für den VM-Overhead-Speicher festlegt wird. ESXi ist dann berechtigt, Overhead-Speicher im Rahmen dieses Grenzwerts zu verbrauchen.
Das Neukonfigurieren einer VM in VMware vSphere kann sich direkt auf den Overhead-Speicher auswirken, den ESXi für die Verwaltung einer VM benötigt. Wenn Sie die Konfiguration einer VM ändern, indem Sie z. B. die Anzahl der vCPUs, die Größe des zugewiesenen Arbeitsspeichers ändern oder virtuelle Hardware wie Netzwerkadapter oder Festplatten-Controller hinzufügen, können sich die Anforderungen an den Overhead-Speicher ändern. Beispielsweise erfordert die Neukonfiguration einer VM-Reservierung von einem Wert von 250 GB in 0 GB eine Overhead-Speichernutzung von rund 25 MB. Für die Verwaltung der Zuordnung der Seitentabellen zwischen virtuellen und physischen Seiten weist ESXi 25 MB zusätzlichen Overhead-Speicher zu. vSphere überwacht und verwaltet diese Änderungen. Ältere vSphere-Versionen wurden jedoch nicht angepasst, um diese Erhöhungen des Overhead-Speichers zu berücksichtigen. Wenn die neue Overhead-Speichererhöhung den Overhead-Grenzwert überschreitet, kann dies zu einem Fehler bei der Neukonfiguration führen.
In vSphere 8.0 U3 aktualisiert DRS den Grenzwert für den Overhead-Speicher der VM proaktiv vor jeder Neukonfiguration. DRS prüft verschiedene Faktoren, einschließlich der Ressourcenspezifikationen der VM, der E/A-Filter und weiterer Elemente, die sich auf den Overhead-Speicher auswirken. DRS stellt sicher, dass der neue Overhead-Grenzwert den nach der Neukonfiguration der VM-Spezifikationen erwarteten Anstieg des Overhead-Speichers berücksichtigt, was die Leistung und Stabilität der VM optimiert.
Die erweiterte Overhead-Speicherverwaltung von DRS kann dazu beitragen, Neukonfigurationsfehler zu vermeiden, indem Grenzwerte für Overhead-Speicher intelligent verwaltet werden, bevor eine VM neu konfiguriert wird. Dies reduziert wird das Risiko von Neukonfigurationsfehlern erheblich. Dieser proaktive Ansatz sorgt für eine zuverlässigere Erfahrung. Durch die Optimierung der Leistung und Stabilität einer VM können virtuelle Umgebungen effizient und unterbrechungsfrei ausgeführt werden. Dies gilt insbesondere für kritische Neukonfigurationsprozesse. Diese Verbesserung integriert sich nahtlos in Ihre vorhandene vSphere-Umgebung und steigert gleichzeitig die Leistung und die Zuverlässigkeit.
