









This section describes the upgrades and maintenance required for individual components making up software-defined architecture. Hardware requires physical interaction, while the software-definition layer and applications must be capable of upgrades or patching remotely.
Hardware
Beginning with the hardware, the upgrading or addition of individual parts might not be common unless additional system storage or memory is necessary. The adding or replacing of hard disks or RAM requires turning off the individual server to be worked on, and therefore it is a best practice to proactively turn off and migrate (as required) VMs installed on the host and to place it in maintenance mode before shutting it down. As discussed in the Redundancy and Failover Mechanism section, it should not present a problem for active-active or active-standby architecture.
The ultimate capacity of a server to accept upgrades depends on the make and model, and users must consult the manufacturer for proper installation guidance. Special consideration must be made when replacing a hard disk which is part of a vSAN datastore (see specific guidance at docs.vmware.com, searching for Managing Storage Devices). After upgrading, the hypervisor recognizes the new devices. Changes to CPU, memory, or hard disk storage size allocation for VMs must typically be performed while it is powered off. However, network devices can be updated, or new devices added (such as additional hard disk apportionment).
Server hardware is recommended to be inspected and cleaned on regular intervals, especially those with forced cooling. Manufacturers have specific schedules defined for media (for example, filters) which can be cleaned or replaced, and each end user organization has to determine best methods for implementing. The monitoring of hardware parameters (as discussed in the Supervisory Monitoring section) helps to provide system feedback (for example, increasing fan speed/operation time or system temperatures) which can be used to adjust preventative maintenance. Some cleaning may be able to be accomplished without turning off the server.
Alternatively, additional maintenance can be scheduled to coincide with physical server interaction (software patching, firmware upgrades, or replacement of other physical consumables such as the system battery) to reduce downtime. The process of powering down a server must be regularly practiced by the end user, if it is expected to be required.
Hardware may require firmware or driver updates for the system or for individual components. If the components are on VMware’s Hardware Compatibility List (HCL) then these might be available through associated update tools. System-level updates (BIOS) requires power cycling the host.
Testing, or functional system verification, following a required parts replacement, cleaning, or otherwise interacting directly with the hardware, can likely be limited to reviewing the system parameters within BIOS or software to ensure changes are correctly reflected there. Additional review of system event logs for any errors is also prudent. For firmware or driver updates, more thorough testing is recommended, similar to verification performed after software patching. See Firmware/Software Testing for a detailed list of steps.
Software-Definition Layer
There are several types of updates and maintenance procedures which can be performed on the hypervisor and centralized management layers (vSphere) of the vPAC infrastructure.
Hypervisor (ESXi) update/rollup/patch.
Hardware drivers (referred to as host extensions, for example, NICs and communications ports, drives).
Management VM update/patch (for example, vCSA, Aria, other system-wide tools)
VM resource allocation changes (for example, CPU, memory, storage, networking)
There are multiple methods by which the hypervisor can be patched. The first is through the vSphere Client GUI of vCSA, where Lifecycle Manager resides. This can be used to create baselines and baseline groups which help define which upgrades and patches are applied. All hosts can be updated at one time, with options to apply sequentially or in parallel (if multiple hosts are in maintenance).
If a single image is applied (which is possible when all hosts are the same make and are stateful) then it becomes even easier to apply grouped changes across all servers within a cluster and can be customized with vendor addons and component firmware or drivers. This tool can also schedule compliance checks and alert for issues or problems that are encountered during the update or remediation period (see VSphere Update Menu).
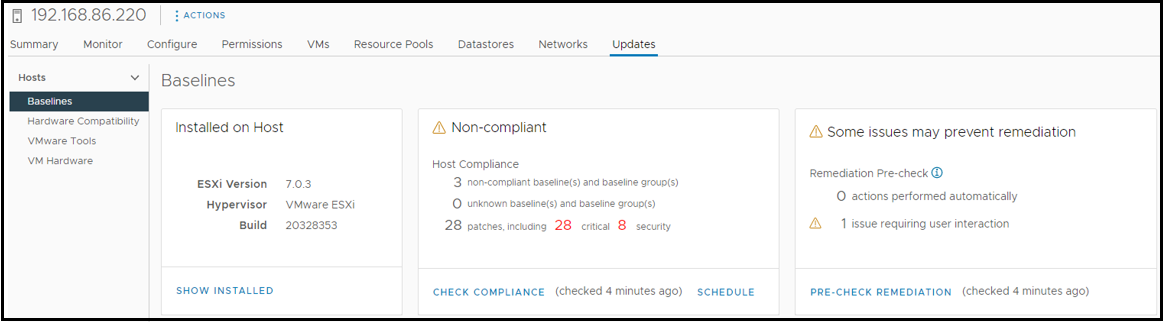
Updates must follow a more manual process when access to the internet is not available (air-gapped environment). Tools such as vSphere Lifecycle Manager can still be utilized, but updates must be downloaded from another workstation with access to the VMware online depot and then imported into the environment for updating.
A second option to update hosts is manually through the vSphere Client GUI. This can be desirable when precise control is necessary for each server to be updated and the associated timing. Obviously, this is a more resource intensive process from a personnel standpoint, as each host must be placed in maintenance mode (after facilitating the moving or stopping of each VM) and then rebooted.
A third option is to update from command line, which is how standalone ESXi instances (or ESXi installations hosting vCSA which is not configured for HA or could otherwise be moved) must be patched. This can be done with or without access to the Internet. For an air-gapped environment, the necessary files must be downloaded from the product patches website and uploaded to a datastore which is accessible to the host. Verification of the file integrity is recommended (by hash checking) before installation.
Further guidance is provided in Appendix A: Security Capabilities again, which walks through an overview of the tools mentioned above and lists out the best practices encouraged for patching VMware infrastructure. In the context of CIP-010 compliance, these built-in tools can aid in the change management and appropriate documentation of changes made related to security. Anyone is eligible to sign up for VMware Security Advisories, which provides the latest remediation patches, their associated severity level, and the products that are applicable. Certainly, not all patches have to be applied, but must be reviewed by an organization to determine if and when the fix should be implemented.
Some of these updates can be implemented with the aforementioned vSphere tools (listed as Component updates within Lifecycle Manager), which means they can be applied simultaneously. Or these may be able to apply directly when a separate GUI or management service is offered by the component (NIC).
With administrative VMs, such as vCSA, the update can be performed within its management interface (accessed from port 5480). As noted within the VMware patching best practices, the updates performed does not affect any managed VMs/workloads. This process is similar for other centralized tools which are installed as separate appliances (for example, the Aria suite of products).
Finally, updates to VM resources allocated can be performed manually, and are relatively straight forward. Powering down for changes to CPU, memory, or storage simply requires powering back on and verifying the new assignments and their associated functions. Again, many types of network changes (adding a network connection) can be applied hot, or while the VM is in-service.
Applications/Workloads
There are several types of updates which can be performed on applications or VMs, including:
Patching of OS
Application upgrades
Settings/configuration changes
Similar to the updates and patches required for a hypervisor, a VM has its own operating system (for example, Windows, Linux-based) which requires the same type of changes. However, a Windows-based VM likely receives a significantly higher frequency of patches compared to a dedicated protection and control appliance, built upon a custom Linux kernel, for instance. The Linux kernel is still provided with updates for bug fixes, feature enhancements, or vulnerability reduction.
Application upgrades might apply to software running inside of a VM, or to the entire appliance. The former would likely be a simpler update, whereas the latter may be issued as a firmware update for a VM that was originally developed as a dedicated hardware-based device. In either case, the update requires planning and testing.
Internal settings or configuration changes to the virtual device that is performing protection, automation, control, or other grid functions, is a process that a utility is already familiar with. Holistic databases and management of configurations are also commonly tied into other areas of their business (for example, providing static information for ADMS or for short circuit studies). And these practices can continue as they begin supporting virtualized infrastructure. The testing of settings updates should follow similar procedures as for a physical device, verifying any net new or updated logical elements and adjacent systems affected. Special isolation considerations are discussed in Isolation Options.
Firmware/Software Testing
There are two considerations for testing changes made to the system firmware/drivers, software-definition layer, individual VM operating system, or virtual appliance upgrades performed within the vPAC architecture.
Create pre-deployment patching/update plans which are appropriate specifically for an organization, based on their internal standards and typical practices. These plans should be used to:
Determine if the patch/update is relevant and necessary (especially considering the uniqueness of their environment).
Understand the interdependencies of the changes to be applied.
Before beginning, identify options to rollback an update, in case there is a problem. This includes having a backup of the environmental data.
Strategize on the scaled production deployment, which might be a standard process, but can differ depending upon the changes being made.
Communicate with departments that could be affected, before and after the production changes have been made.
Determine the tests required for each type of update/patch. This might be on a case-by-case basis, but can generally be defined for different types (for example, hypervisor security patch against the upgrading of a VM’s assigned storage capacity).
Implement changes within a test environment, which has been set up as closely to production/field equipment as possible. Monitor the system post-update and continuously observe or regularly review system event logs for any errors.
Execute baseline:
Performance testing
Compatibility checks
Cybersecurity scans
Isolation Options
In the context of this document, isolation refers to the environmental separation of a virtual device (or devices) from production communications/signals, for the purpose of performing testing during commissioning or maintenance. Traditionally, test switches and cutouts have been used by utilities to electrically and visibly isolate portions of a physical scheme. And this method is still viable where merging units or other digital translating equipment connects to high voltage apparatus (example of isolation for currents and potential circuits, Figure 115).
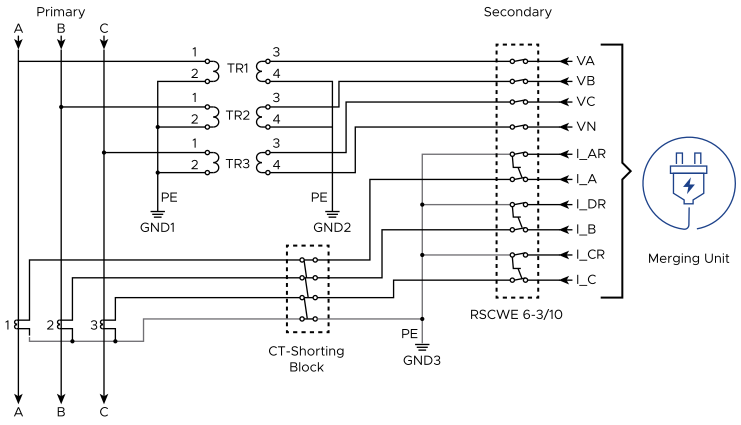
Beyond this remaining physical, hard-wired layer of equipment, digital signals are transmitted and received by I/O translation devices into the software-defined architecture. Within these digitalized and virtualized layers, there are two main categories of testing or simulation methods. The first is based on the use of communications to update applications logically or through standards protocol behavioral modes. And the second is to leverage the segregation capabilities of the virtual networking to create isolated sub-environments.
Mode/Behavior Control through Communications
It is already common practice for utilities (as well as other industries) to leverage logical isolation methods to create blocking and alerting means for protection, automation, and control schemes which incorporate communications. Examples of this may include programming logic elements (latches, timers) which assert based on user interaction (for example, pushbutton “test mode”) or communications health to supervise outputs and messaging, events, alerts, and alarms. While these methods are agnostic to the specific communications protocols being used, it can be labor-intensive and prone to personnel error (during implementation or in practice).
IEC 61850 communications protocol, which makes up a significant portion of the protection and control traffic of the vPAC infrastructure, has been developed to incorporate mode control and behavior. There are differences in how Editions 1 and 2 function, where the latter has been improved to include increased standardization in message processing, thereby increasing its reliability for testing. Therefore, Edition 1 is not be discussed here.
Edition 2 offers both test and simulation modes (described here briefly for informative purposes). Test mode was intended to offer a digital, flexible means for isolation, taking the place of the aforementioned test/cutout switches, and the five defined modes include:
ON – The IEC 61850 logical node (application) is in-service.
ON/BLOCKED – Logical node in-service, but output data is blocked.
TEST – Logical node is in the test mode and will receive updates, but will only interact with other logical nodes also in test.
TEST/BLOCKED – Logical node is in the test mode and will receive updates, but will not output data.
OFF – Logical node is out of service.
As an example the test/blocked mode can be used to simulate a device to receive data and logically operate but without taking output action. This is similar to previous cases where a traditional device was provided with the proper signals to initiate a trip but a cutout blade was opened on the equipment side of the output to stop the actual operation.
Simulation mode was intended to replace a traditional test set that is used to inject values (both analog and binary/digital) into devices. A simulation flag (‘S’ bit) is set within GOOSE and SV messages to alert the subscribing device to receive simulation messages instead of normal traffic, which it continues to do until the bit is set to FALSE. Other subscriptions not in ‘S’ mode can be simultaneously received and processed normally, within the same device. Depending upon the device- or vendor-specific implementation of simulation mode within an application, its output data may be published as normal, so care must be taken to put them in test, if needed, to avoid inadvertently operating subscribers of GOOSE messages from devices being provided with simulated values.
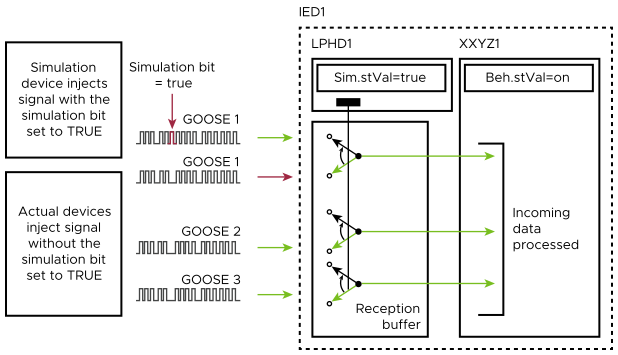
Changing the mode and behavior of a logical node was intended to be performed by an MMS client. Test devices or software can also often simulate this control, or the device vendor may have also implemented alternative logical/configuration methods to achieve the desired state. Monitoring the state of test and simulation modes can be performed with network packet analysis tools (for example, Wireshark, 61850 test sets, or by an MMS client).
Additional information about testing with 61850 protocols can be found within sections of the IEC standards (61850-6, -7, -8-1, and -9-2). It is recommended for organizations to test the capabilities and appropriate behavior for both normal and test/simulation modes during initial commissioning. Verifying that devices (virtual or physical) do not operate when performing maintenance on them under test, blocked, or simulated conditions is critical to prevent disruption of production equipment. Therefore, clear documentation and training should additionally be developed and provided to personnel.
Virtual Network Segregation
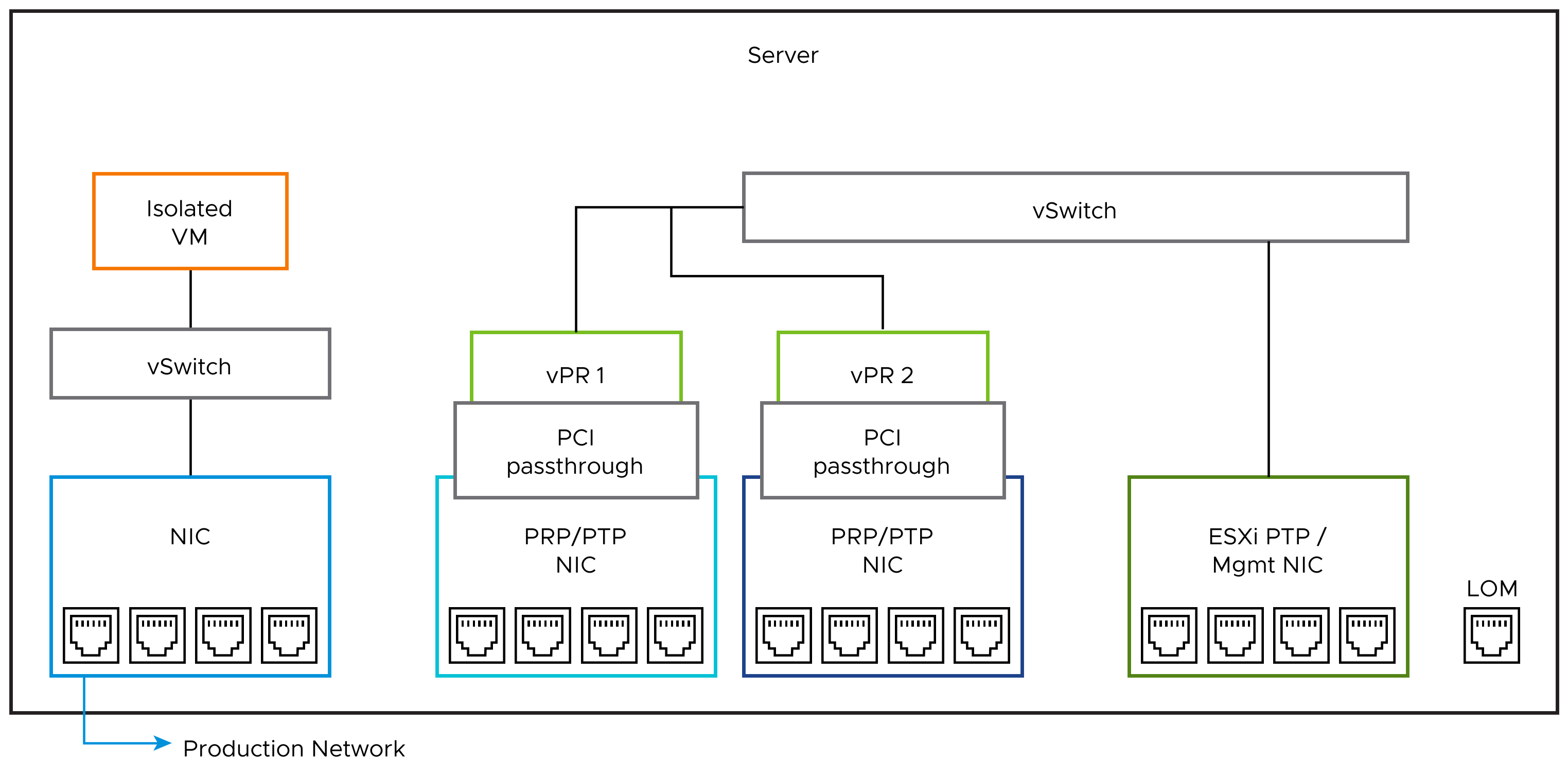
A virtualized environment (where there are sufficient overhead compute resources) offers the ability to create workloads connected to an isolated network. This can be architected from physical communications ports to virtual switches, connecting them together with one or more VMs. This allows external traffic to interface with the VMs. Alternatively, virtual networks can be constructed to only tie VMs together internally (within software). Both options can offer testing methods that do not affect adjacent virtual devices.
Use cases could vary for either layout:
External Network to Internally-Isolated VMs:
New application to ingest traffic from the production environment, using physical switches.
Installation of VMs using overlapping network functionality (for example, DHCP server) for orchestration.
Figure 4. Isolated App Ingesting External Production Traffic
Internally Isolated Network for VMs:
Internal testing workloads providing data (for example, test signals) exclusively to another appliance.
Updates or configuration changes to be applied to a copy of a production VM before mass deployment (where a mimic test environment is not available).
Figure 5. Isolated App Connection to Testing VM 
These are only a handful of examples which show the value added by this platform in creating a digital pool of signals and combining it with the flexibility of high-performance computing where applications can easily be installed, cloned, moved, and deleted.
There is nothing specific, regarding these capabilities, which must be tested within the vPAC reference architecture presented here. However, if there are known future use cases which could be implemented within a production environment, it is prudent to build these within test architecture first, for verification purposes and training opportunities.
Interoperability
End users desire solutions which are interoperable. This means they can exchange data using standard protocols (for example, IEC 61850), increase overall system efficiency by eliminating the need for a larger infrastructure footprint, and save costs by avoiding duplicate efforts in the types of tools, software, and interfaces they must support. Additionally, interoperability introduces greater flexibility and scalability, and promotes innovation amongst the interconnected components. This compatible interaction must take place on all layers of the platform, including the hardware, software definition layer, and the applications.
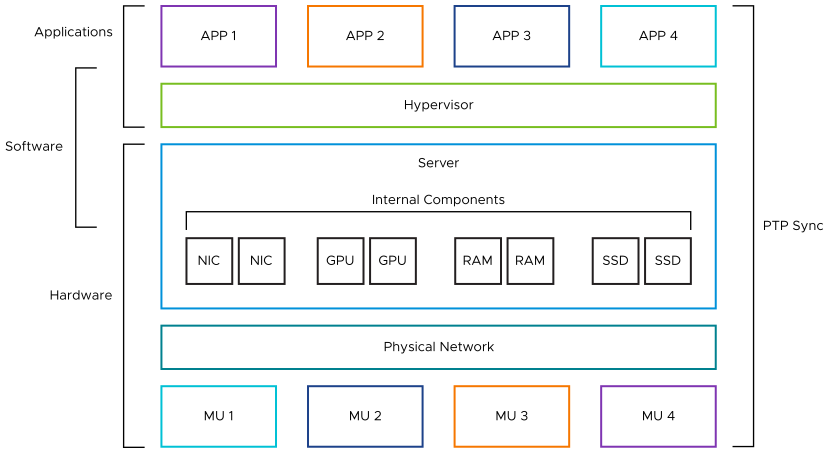
Hardware
The hardware layer is made up of both the I/O translation devices and the high-powered computing platform. At the I/O level, the interoperability between various manufacturers is defined by the communications between systems. And there are standard protocols which are supported by commercially available merging units (and other digitalization interfaces), including IEC 61850, DNP, MODBUS, PTP. Therefore, at this level, compatibility depends upon how similarly protocols have been interpreted amongst vendors, or the ability for third-party tools to integrate devices or applications.
Testing the interoperability between the I/O and the applications happens through creating, applying, and verifying configurations as they are applied at each end of the stack.
The server has specifications, which must be verified to fit within existing utility environments (as indicated in Hardware Considerations section). The variable components which can be installed (including the CPU, memory, storage, and network cards) must be compatible with both the server itself, as well as the hypervisor. vSphere requires specific makes/models to achieve the stability and performance required for vPAC Ready Infrastructure. The VMware HCL provides a means to quickly search for, and match software and hardware versions that work together. Then, there is no need to test for this level of compatibility, as it has already been verified.
Software Definition Layer
The hypervisor must be compatible with both the host (as discussed earlier) and applications. When a new VM is created on ESXi, there is a virtual machine compatibility setting, which determines the availability of the virtual hardware which can be allocated from the physical level. And there is also a guest OS selection which can determine firmware type used and settings ranges available per VM. A pre-packaged, commercial VM however, is delivered as an OVA or set of OVF files, which have most options pre-configured, and might offer additional initial configuration options (such as administrative usernames/passwords and networking parameters).
Testing the interoperability of the software definition layer is not necessary, unless the development is performed by the end user, or new components are installed, which are not pre-certified for use by VMware. If this situation should arise, support can be engaged by VMware or the relevant hardware manufacturers.
Applications
Regarding interoperability, there are two main aspects of an application to consider, including its compatibility with the hypervisor and the communication protocols and interfaces it supports, as mentioned above. ESXi supports a wide range of operating systems which can be used to build VMs or to host container engines. This means that the hypervisor already has a high level of interoperability built into it. And again, it is unlikely that this aspect of the compatibility between the software definition and application layers require testing or further development by the end user, unless it is to test multiple makes/models of hypervisors.
The communication protocols supported, and the underlying networking constructed between applications determine if they can successfully interact. API support between them (as well as with the hypervisor) may also be a consideration for developers but is outside of the scope of this document.
Testing that each application can be installed and managed by vSphere is inherently covered by previous sections. Verification that they can also interact with internal (other hosted VMs) and external (remote VMs, management systems, and databases) interfaces should be the focus. Recommended steps include:
Verifying that all production applications can be installed within the same environment while successfully performing their respective functions (as discussed within the Scalability section).
Proving that data can reliably be exchanged between applications, where required (for example, between vPR instances with overlapping zones of protection).
Measuring the performance of inter-application communications.
Ensuring secure integration with shared remote databases and management systems.
Assimilating vPAC architecture into an environment containing legacy devices (if required), to include data exchange with existing systems.
While interoperability among systems, as discussed here, is both desirable and necessary, system implementation by the end user should be carefully considered to include the same/similar components wherever possible. This practice can reduce labor costs, reduce human error in implementation and operation, reduce spare parts required to keep on-hand, and make testing, training, and maintenance activities simpler, thereby increasing overall reliability.
Application Functionality
Applications may be offered by VMware partners, third-parties, or designed/built in-house by an end user’s organization. The internal functionality (i.e. the capabilities it offers to perform on I/O) must be documented by the original developers. It is anticipated that the appropriate guidance for installation, testing, and maintenance of this top-level software is provided by them. Especially regarding functionality related to the internal settings and configuration (for example, setting the protection functions within a vPR application) is outside of the scope of this document. Certainly though, capabilities of the software (for example, specific communications protocol support, settings group switching, live troubleshooting tooling) must be investigated before acquisition and evaluated after installation.
There are additional surface-level aspects of the virtual appliance which should be verified. This can include the following tests:
Successful installation on all expected host and datastore types.
Verification that multiple instances of the application can be operated in an active-active or active-standby topology (as mentioned in previous sections).
Performance testing of the application, especially for any real-time requirements (see System Monitoring).
Ensuring the application is consistent in its operation (it should meet 99.999% availability requirements, see Resiliency During/After Break-In).
Proving the capability to update an in-service VM or its internal configuration without the need to restart. This could apply to a change in the virtual networking or the IEC 61850 configuration (SV addition/replacement), for example.
Demonstrating that individual VM maintenance or routine testing can be performed without disrupting other VMs.
Initializing the VM provides enough configuration parameters (such as static network addressing) to enable efficiency in orchestration.
Evaluation of the licensing methods to ensure a product license is easy to apply and is resilient to normal VM activities:
VM power cycling
Taking snapshots of the VM and reverting to a previous state
Deleting and reinstalling the VM
Moving the VM to another host
Replacement of hardware components such as network cards
Failures in any tests might require fixes or further development by the application developer or the software definition layer provider.
