









The capacity of both the hardware and software of the vPAC architecture to continuously operate is a key factor in the organizational choices made on how to implement this technology. Particularly in a utility OT environment, it is expected that components can either survive, or quickly recover from, unexpected events occurring on or within critical services.
Resiliency During/After Break-In
It is first recommended for the system as a whole to be operated at full expected capacity for an extended period, after initial setup and configuration. All required components, along with the highest levels of process and station bus traffic expected, must be implemented and run at steady state, uninterrupted for at least 1000 hours of burn-in time. During this time, the system must be observed for the aforementioned monitoring aspects, alarms and events.
Following the break-in period, typical functional checks must be run to ensure that the platform continues to produce appropriate results. This includes accessing GUIs, communications with external systems, and the continued ability to act on simulated system events (in the case of a vPR or vAC application) within a timely manner, as tested in the System Monitoring section.
Architecture must be capable of meeting the 99.999% availability requirement as listed in the Design Objectives.
Baselining Normal Operation
Determining a baseline for normal system operation can help responsible personnel to understand recovery time for possible worst-case scenarios and spotting irregular behavior or failures early on. Aspects of this includes time to boot into a production-operable state from a:
Server powered-off state (which might include VMs configured for auto-start).
System reboot (which might include VMs configured for auto-start).
VM restart (or manual power off - power on).
Deployment of templated VM.
VM copy or migration (if applicable), which can also be for HA or FT.
VM snapshot restoration (if applicable).
Recording the time difference for these event types is a manual process, but the vSphere Client recent tasks window provides time stamped (based on host synchronization method, NTP or PTP) events. Repeating each type of event and recording the average introduces a Mean Time To Recovery (MTTR).
Remediation for Hardware and Software Failures
It is important to understand how each component, whether hardware or software, affects the system during a failure. Beginning with the hardware, we can examine how to initiate failures, test the effect on the system, and discuss best options for remediation.
Power Supplies: (Item #15 in Example of Traditional Server Parts - Breakout Diagram)
The consequences for a power supply failure are clear, as the server cannot function without at least one healthy supply. There is redundancy here, and some manufacturers might offer diversity (AC and DC options).
The simulation of a power supply failure simply involves removing the input voltage or, in the case of hot swappable capabilities, careful removal of the module. Verification that the server continues operation, uninterrupted on the backup supply, must be adequate. It is prudent to verify the return of the primary supply also does not adversely affect operations, and that it regains status as primary or establishes new status as backup (as applicable).
Cooling System: (Active components are Item #5 in Example of Traditional Server Parts - Breakout Diagram)
There are different cooling mechanisms used across different manufacturers’ servers. These range from passive (such as heat sinks, pipes) to active (fans, pumps). With passively cooled systems, it is less likely for failures to occur within the lifetime of the host. Monitoring must be performed for temperature and core component performance in case of overheating due to performance overload or rare mechanical, stress, or other material fatigue or corrosion failure types.
Testing for active component failure must be straight forward and can be performed by removing power from or otherwise restricting or blocking an incremental amount of fans, for instance. This can simulate dust accumulation, the physical blocking of adequate airflow, or full stoppage of a fan. The effects of partial cooling system failures take time to become evident. Some manufacturers offer (n-1) resilience in meeting their published specifications, or the ability to hot-swap fans on a live system. This can be appealing for convenience to correct a cooling system alarm without having to take the system offline for maintenance. This capability should be tested where it is available.
Central Processing Units: (Item #8 in Example of Traditional Server Parts - Breakout Diagram)

CPU failures are likely to be detrimental for the entire system, especially for single socket servers (common). Early warning signs of a failing CPU may be inconsistent booting, inadvertent restarts, audible noises (for example, more beeping than usual), or freezing/hangup during operation. Once failed, it is common for a normal boot to become impossible. Auxiliary systems might run (fans), but this system must be repaired or replaced. Recovery for this type of failure relies on the backup methodology that is implemented. Active-active systems continue to operate on adjacent hardware, and HA or FT workloads automatically fail over. Critical data from this host should have been replicated externally or off-site.
Dual CPU servers may offer some protection from singular failures. However, this is manufacturer-dependent upon programmed behavior. Some server types may not permit operation with only one CPU while the other is failed/absent. And, even when it is possible, CPU affinity must be manually set up in vSphere for each VM to ensure they are associated with specific, separate CPUs, as desired. Searching for assign a virtual machine to a specific processor in docs.vmware.com offer more information on how to setup.
In terms of individual cores (and by association vCPUs), it is unlikely a processor as a whole operates for a partial failure. If it is still operable, its performance can be degraded (and must be recognized by monitoring metrics), and this server can be an immediate candidate for remediation.
Simulating the failure of a CPU may prove to be difficult. However, instantiating a workload to run stress test tooling (stress-ng) can offer ways to push the CPU to its limits and otherwise consume select resources. For dual socket cases, it may be possible to disconnect or otherwise prevent operation of a single processor.
Memory: (Item #17 in Example of Traditional Server Parts - Breakout Diagram)
Errors within Read Access Memory (RAM) can lead to improper processing by the operating system or application, data corruption, or even complete system failure (<insert color> screen of death). Before Error-Correcting Code (ECC) memory, these errors were more difficult to detect.
The types of errors can be categorized as hard or soft.
Hard errors are a result of physical damage (such as occurring in the manufacturing process) and are typically detected during boot.
Soft errors are a result of temporary disturbances (such as transient during read operation) and may be correctable by a system employing ECC.
Testing for memory errors might require specialized equipment, such as interface modules (for those interested in performing). ECC memory must offer benefits using self-correction of single-bit errors, and the detection of these and other error types. Typically, both the host and the hypervisor provide an alarm for this type of event. The recommended remediation is to remove or replace failed memory either after repeat offenses (correctable error types) or immediately (permanent failure types).
Hard Disk Drives: (Items #1 and #9 in Example of Traditional Server Parts - Breakout Diagram)
Hard drives come in several different commonly used forms, including Hard Disk Drive (HDD) featuring spinning platters, Solid State Disk (SSD) featuring non-volatile flash memory, and Non-Volatile Memory (NVMe) express acting as an SSD attached to a PCIe slot on the main board).
The HDDs are nearly obsolete now and is not discussed here. SSDs are fast and have no moving parts, which increases their durability. Given their common availability and high performance, these drive types are exclusively considered here.
The health of a disk is typically monitored in multiple locations, including the server and the hypervisor. This monitoring may additionally be extended into the guest operating system. Beginning with the Intelligent Platform Management Interface (IPMI), the hardware platform often has built-in metrics for tracking basic health aspects, such as failure prediction and remaining rated write endurance, which can typically be made available through SNMP. There are methods for redundancy of physical disks at the hardware level if a supported, physical RAID controller has been installed. This can offer resilience in the form of disk failures which can be tolerated (one or more, depending upon system configuration). However, there is often a single point of failure in the RAID controller itself.
At the hypervisor level, vSphere actively monitors various aspects of the hard drive performance in the form of:
Sum – data I/O rate (KBps) rate across all Logical Unit Numbers (LUNs) of each host.
Rate – read and write rates (KBps) for each disk.
Requests – read and write commands completed for each LUN.
Latency – kernel + device latency = time used to process SCSI commands from guest OS to VM.
Storage capacity – used space against the available capacity.
Events and alarms can be configured for receipt using SNMP or Syslog. There are methods for redundancy of virtual disks at the software level, if vSAN is utilized. Similar to the hardware RAID mentioned previously, vSAN can offer higher levels of failure tolerance for disks, along with increased, shared storage for the local cluster. With the remote witness, there is no single point of failure locally at the system level.
Testing for disk failures can be achieved with special tools or by brute force. Some servers allow for hot swapping of hard disk drives, which allows the brute force method of simply unplugging a drive to see the effects and proper automated remediation (if applied). VMware also offers built-in and special tools (such vSAN Disk Fault Injection script) for testing.
Peripheral Component Interconnect (PCI): (Items #11 and #12 in Example of Traditional Server Parts - Breakout Diagram)
PCIe cards are found in nearly all servers and are used to customize and augment the base functionality. These have various capabilities, and may take the following typical (in the context of this document) forms:
Network Interface Cards (NICs)
NVMe SSD
Redundant Array of Independent Disks (RAID)
Graphics Processing Unit (GPU)
In implementation, the PCI card becomes an additional compute resource which is added to the existing pool (for example, a NIC adds several physical network ports to the existing on-board server ports) or adds new functionality (for example, GPU, where on-board graphics processing was not available). This means that the monitoring of a PCI card depends on its functionality, where NICs are included in communications failures, NVMe drives in disk drives, and RAID cards at the server-level (external to the software infrastructure).
GPU cards are not specifically discussed in this guide but can be used for utility use cases such as physical security and asset management. Redundancy can be applied across VMs by assigning multiple partial or complete virtual GPU (vGPU) allocations to the same appliances.
Communications:
The resiliency of both the physical and software networking is reliant on its redundant architecture, as discussed in Redundancy and Failover Mechanism. Standard protocols and best practices, such as PRP, LACP/LAGs, and assigning failover ports in networking provide robust paths.
One technology that is not mentioned yet is Software Defined Networking (SDN). Software overlay networks can add features such as authentication or authorization, high availability, dynamic path optimization, multitenancy, and security. This can be implemented as SD-LAN (often simply called SDN) or SD-WAN. Software Defined-Wide Area Networking (SD-WAN) can offer the functionality described.
Physical connections can be unplugged, and virtual ports can be disabled to ensure that redundancy and failover mechanisms are working as expected, in real-time and without loss of information.
Hypervisor:
The hypervisor acts as the underlying operating system for an entire sever while its stability relies on the supporting CPU, memory, and storage. Commercial releases are designed and tested to be durable within production environments. The failure of this system component can cause the host to stop responding and display an error screen.
System parameters continue to be recorded up to the point of failure, and diagnostic information is provided visually (through GUI) and recorded in a core dump file locally (in addition to any automatic event/log collection methods that have been setup, such as SNMP traps and Syslog). This information can be reported to VMware and any organizational teams responsible for the systems.
Testing the failure of a host (the entire server) is common and demonstrates the benefits of having active-active or active-standby architecture. This can be a simple reboot, entry into maintenance mode, or even leveraging the built-in verification tools (such as vSAN Cluster health manager). Simulating an irregular state of the hypervisor is less practical, especially for modes not involving an external catalyst (such as hardware failure).
Applications:
The applications, or workloads, operate on top of the vPAC system, and therefore it is unlikely their own failure to affect the lower levels discussed in the preceding parts of this section. Additionally, the flexibility with which applications are deployed and managed is at the heart of the justification for industry transformation.
In the Redundancy in Virtual Applications section, two topologies are discussed with VMware capabilities to automate the remediation of applications which have characteristics tolerant of short failover durations (example, vAC). These capabilities include HA and FT, and the pre-requisites for each recovery method are presented here:
High Availability requirements:
Licensing for HA.
A cluster with two or more hosts.
Static (or otherwise persistent) IP addresses assigned per host.
At least one common management network (where it is also recommended to incorporate redundancy).
All hosts have access to the same VM networks and datastores and located on shared (not local) storage.
If performing VM monitoring, VMware tools must be installed in the VM.
Fault Tolerance requirements:
Licensing for fault tolerance.
Fault tolerance logging and vMotion networking configured.
vSphere HA cluster created and enabled.
Hosts must use supported processors and be certified for fault tolerance (see http://www.vmware.com/resources/compatibility/search.php, search for Fault Tolerant Compatible Sets).
Hosts must have Hardware Virtualization (HV) enabled in BIOS.
VM files (except for the VMDK files) must be stored on shared storage (Fibre Channel, iSCSI, vSAN, NFS, or NAS).
vSphere tools allow for running profile compliance checks to verify the aforementioned capabilities have been appropriately enabled within an environment. Again, the failover time for HA may be from seconds to minutes, while FT is typically less than 1 ms (although FT is still not recommended for vPR or other critical, low latency workloads due to performance interference which may occur from host-to-host sync mechanisms).
Testing HA and FT can be performed either locally or remotely. It is recommended that realistic failure scenarios be used, when possible, to initiate VM failover. These include:
Disconnecting the HA or FT management network from the host, either physically or by remotely disabling the switch ports facilitating the traffic. This may include two or more physical ports. Keep in mind, when using vSAN, that HA management is facilitated within the same network.
Powering down the host either by removing the supply of power physically, or remotely powering down the host through vSphere or host management (for example, using IPMI).
Less realistic scenarios involve disabling the physical NIC driver module from the VMkernel (which can result in having to re-install the kernel module) or triggering a fault or failover test from within the vSphere management console. However, the latter may be very useful when Baselining Normal Operation.
Additional testing guidance and recommendations can be found at docs.vmware.com (search for vSphere Availability). vCenter Server Appliance can be implemented with High Availability as directed within, and further backup, restoration, and patching practices are provided.
Cyber Security Capabilities
Appendix A: Security Capabilities has been included within this VVS document for the purpose of expanding upon the background of VMs and modern applications and how software-defined architecture, and more specifically VMware products/solutions, can be leveraged to accomplish both basic and advanced security goals. The expected cybersecurity architecture must be implemented before running performance tests, especially those outlined in System Monitoring.
Beginning at the hardware level, a Trusted Platform Module (TPM) can be used with a Unified Extensible Firmware Interface (UEFI) by vSphere to attest the host’s identity using responses to authorization requests. Then, at the VM level, using either key provider capabilities native to vSphere or from a third-party, data encryption can be performed for the VM files, virtual disk files, and core dumps. If using vSAN, all data on the datastore can be encrypted both at rest and in-motion.
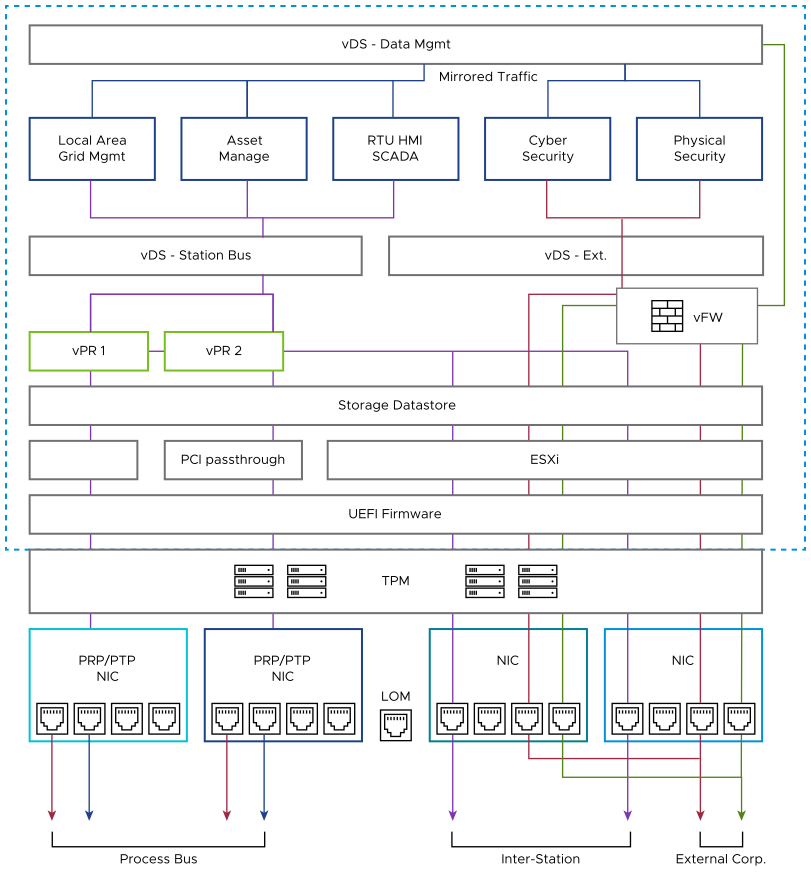
Software-defined networking can add logical isolation or security zones to enhance the protection between workloads. Hardware and Software Security Layers shows an example of how connections between virtual Distributed Switches (vDS) can provide the segmentation of different traffic types.
This can include restrictive management access to vPRs through external corporate port connections (NIC > virtual firewall > data & management switch > asset management VM > station bus switch > VPR) along with other selective paths and blocking means (such as each vAC VM featuring its own firewall or similar access restriction measures, not shown).
Alongside this defensive architecture, an offensive posture can be established with threat detection and response, anti-virus, and other vulnerability sensing. There are both VMware and third-party applications which can perform these duties. Select a provider carefully, understanding where sensor analytics is performed (that is, on premises within an organization’s private cloud, or in the public cloud through provider hosting). With either structure, it can be advantageous to restrict the data flowing to the local sensors (for example, with port mirroring, as shown in Hardware and Software Security Layers).
Latency sensitive traffic, such as process bus or other inter-station signals, can be chosen for exclusion from this analysis when it is physically and logically isolated from other traffic types.
Testing system aspects related to cybersecurity might include functions that are only performed periodically along with those that are performed continuously. And any of the following tests migh be required by regulatory standards.
Periodic tests:
Network scanning – detection of open ports and services.
Vulnerability scanning – searching for missing security patches, weak passwords, or outdated software.
Penetration testing – manual exploitation of possible system weaknesses (such as password cracking, SQL injection, buffer overflows).
Continuous tests:
Intrusion detection – active network traffic captures used to analyze and identify potential security threats.
Anomaly detection – baselining normal traffic patterns as part of a feedback loop to actively analyze environmental activity for unusual or suspicious deviations (for example, malware or ransomware)
Anti-virus scanning – real-time system scans performed to detect software or network behavior or known code variants to identify threats to be quarantined or removed.
There are other types of problems or potential attacks that can occur within a network, such as broadcast storms. It is a large number of packets that push network capacities to their limits, which can make devices difficult or impossible to access, until the sources of traffic are removed. There are ways to detect this type of behavior within physical switches (such as Cisco storm control) and even within virtual networks (for example, alerts in third-party monitoring such as Auvik).
Additionally, there are types of attacks (for example, man-in-the-middle or MITM) which can be very difficult to detect. Therefore, it is important to utilize data encryption where possible (both for data in-motion and at rest), secure authentication, secure protocols (against common insecure protocols such as Telnet, DNP, Modbus), and network segmentation (VLANs).
Backup and Restoration Processes
Appendix A: Security Capabilities of this document introduces backup and restoration philosophies and recommendations. An organization must initially determine their Restore Point Objective (RPO) and Restore Time Objective (RTO) for each application.
Active-active configurations incorporate the lowest levels tolerated for data loss (RPO) and downtime (RTO), at zero for each. However, if one instance of a workload fails, it is still desirable to restore the device quickly and easily.
There are several common methods used to backup virtual machines:
Backup of the OS/data, the same as for a physical machine – this entails leveraging tools that are either built into the OS or other vendor-created management tools (for example, life-cycle management or external database). This can be an option chosen to provide a duplicate of just an application’s configuration and stored data (for example, power system event recordings). Overall, this might be a simple option, but only protects the internals/data of a VM and is not a means to fully restore the workload.
File-based backup of VM files – each VM is made up of a number of files stored on the datastore which it resides upon (configuration, virtual disk, NVRAM settings, and log files). These can be automatically scheduled for backup (with third-party software) and used to restore an application manually. But it might result in a higher restoration time (RTO).
For vCSA, a file-based backup scheduler is available within the management GUI (accessed through port 5480), from which the platform can be manually restored when necessary.
Dedicated, complete solutions – managed options such as VMware’s vSphere Replication or other third-party disaster recovery options (such as Veeam, NAKIVO, Zerto). These offer backups as images which can fully restore working VMs, often from multiple restore points that have been saved.
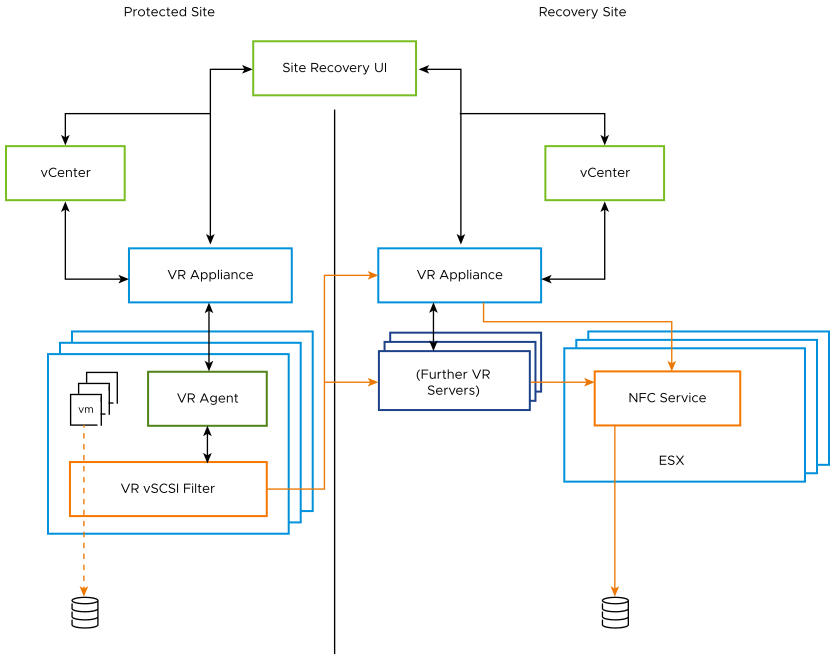
Regardless of the method chosen, the backup solution must be tested regularly to ensure RPO and RTO objectives can be met and met by service personnel in charge of the systems. As pointed out in Appendix A: Security Capabilities, this can help to meet CIP-009 regulatory requirements, where organizational plans also have already been established to identify roles and responsibilities. Best practices include both on-site and off-site storage solutions, in case a disaster should be widespread enough to affect a site in its entirety, and encryption of the backup/storage data. Note that VM snapshots are not recommended as a long-term backup solution, but rather to be leveraged when updating or patching VMs instead (and can be performed for VMs with PCI passthrough network resources, but only by first powering off the VM).
Testing the restoration of an application and its data is best performed within a non-production environment. Therefore, VMware recommends having the same (or more capable) hardware and software infrastructure layers installed with a safe zone , which can still be accessed from production networks. This offers a few advantages, providing the safe capability to verify the following:
Full functionality of restored applications (thereby verifying the backup methodology) to include the correct and up-to-date configuration and settings for the virtual device.
Timing necessary to reinstitute failed architecture (which can be used to establish an MTTR for each type of workload).
Personnel experience, as a training exercise.
Within the test environment used for disaster recover, there must be the capabilities for I/O generation, such as IEC 61850 communications. And special care should be taken with the networking for restored applications. If a VM was recovered into a site without the same network configuration, connections cannot be restored, and manual reconfiguration must then take place.
