









A pool group is a list of server pools, accompanied by logic to select a server pool from the list. Wherever a virtual service can refer to a server pool (directly, or through rules, DataScripts, or service port pool selector), the virtual service could instead refer to a pool group.
Pool selection is often referred to as pool switching.
The pool group is a powerful construct that can be used to implement the following:
Priority Pools/ Servers
Backup Pools
A/ B Pools
Blue/ Green Deployment
Canary Upgrades
This feature is not supported for IPv6.
What is a Pool Group?
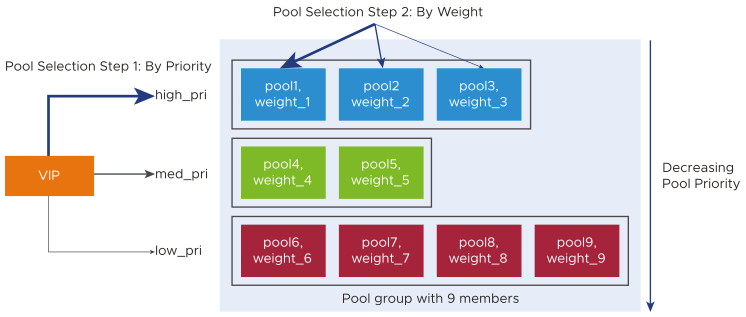
A pool group is a list of member (server) pools, combined with logic to select a member from the list. The PoolGroup object is represented as a list of 3-tuples { Priority, Pool, Ratio }, each tuple describing a member. For example, defining the pool group depicted below would require a PoolGroup object with nine 3-tuples.
How does a Pool Group work?
Considering the diagram from the above section, when a Service Engine responsible for a virtual service needs to identify a server to direct a particular client request, the following are the steps to be used:
Step 1: Identify the best pools within the group. This is governed by pool priority. This group of nine members defines three priorities, namely, high_pri, med_pri, and low_pri, but pool1, pool2, and pool3 are the preferred ones because they have all been assigned the highest priority. NSX Advanced Load Balancer will pick one of them.
Step 2: Identify one of the highest-priority pools. This choice will be governed by the weights assigned to the three pool members, weight_1, weight_2, and weight_3. The ratio implied by those weights governs the percentage of traffic directed to each of them.
Step 3: Identify one server with the chosen pool. Each of the 9 members can be configured with a different load-balancing algorithm. The algorithm associated with the chosen pool will govern which of its servers is selected.
The Effect of Persistence
As per the above algorithm, as it would be applied to client requests initially and thereafter, absent the effect of persistence. However, persistence will have an overriding effect for the 2nd through nth request from a given client, if persistence is configured, which it can be, on a per pool basis.
The algorithm explained in How does a Pool Group work? section is applied to the client requests initially and thereafter if persistence is not configured. Persistence, if configured, will override the algorithm from the second request onwards, from a given client. This can be on a per-pool basis.
To enable persistence in a pool, navigate to and select a persistence type from the Persistence Profile drop-down menu provided.
Pool or Pool Group?
Pools and pool groups can be interchangeably used on a virtual service. The benefit of using pool group is there will be no disruption to the existing traffic, even when the pool group membership changes. Connections to servers in an existing pool member are complete even if the pool member is removed from the pool group. Likewise, the pool group can be expanded dynamically.
If the functionality of a pool group is not anticipated, use a pool. It consumes less SE and Controller memory by avoiding the configuration of an additional full-fledged UUID object.
The list of pools eligible to be members of a pool group will exclude those associated with other virtual services.
