









Tanzu Service Mesh provides an actionable SLO feature that you can use to influence service autoscaling decisions.
Example of Use Case 4
To illustrate this use case, let’s use the Acme application example.
Deploy the acme application to the acme namespace in your clusters.
Create an actionable SLO policy .
Then create an associated GNS -Scoped autoscaling policy.
For more information about configuring an SLO, see Configure an SLO Through the User Interface in the Service Level Objectives with Tanzu Service Mesh documentation.
Once the policies are created, you can view the actionable SLO and autoscaling in action for the service on the Performance tab for the service.
For example, if you configure (A) an actionable SLO, (B) with p99 latency SLI set to 120 ms, and (C) with an Error Rate SLI set to 1% targeting the order service.
The following screenshot illustrates an SLO-linked autoscaling scenario for the order service where an SLI in an SLO is violated, and the autoscaling metric is below the scale-down threshold.
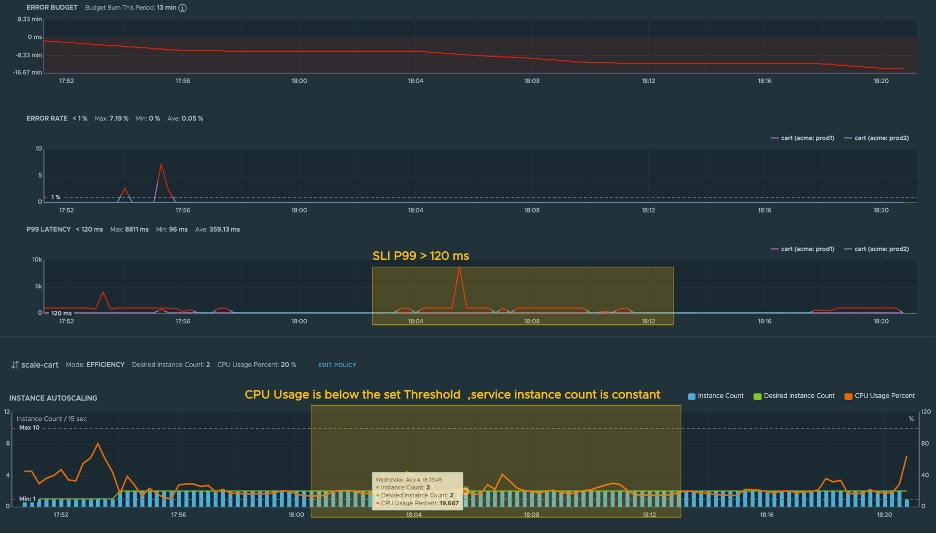
To illustrate this scenario, let’s consider this example:
The SLI P99 latency is greater than 120 ms, which means that the response time for 90% of requests received by the order service is greater than 120 milliseconds. This is above the SLI set for the order service.
The Autoscaling metric CPU Usage Percent for the order service is less than 20%, which is below the scale-down threshold.
In this scenario, even though the autoscaler metric value is below the scale-down threshold, Tanzu Service Mesh Autoscaler will not scale down the order service because the SLO has been violated according to one of the SLIs (P99).
The Example Resiliency Configurations and Autoscaler Outcomes section below describes various resiliency configurations and notes the autoscaler outcomes. The Scenarios in SLO-Linked Autoscaler section lists various scenarios in an SLO-linked autoscaler and notes the autoscaler outcomes.
Example Resiliency Configurations and Autoscaler Outcomes
Configuration Scenario |
Autoscaler Outcome |
|---|---|
|
"cart_v1" will be autoscaled based on monitoring the CPU metric. |
|
No autoscaling of "cart_v1" because there is no autoscaling configuration associated with it. |
|
“cart_v1” will be automatically scaled up based on monitoring CPU. However, when the scale-down condition is based on a CPU value, the autoscaler will additionally check if the p90_latency SLI metric is healthy before scaling down. If the p90_latency is unhealthy, the autoscaler will not scale down even though the CPU value is below the configured scale-down threshold. |
Scenarios in SLO-Linked Autoscaler
An actionable SLO is configured with SLI p90_latency set at 500 ms for the cart service:
An autoscaling policy is configured for cart_v1.
Autoscaling mode -Efficiency.
Autoscaling Metric – CPU Usage averaged over 120 seconds.
Scale Up Condition – 80%.
Scale Down Condition -40%.
Condition |
Autoscaler Outcome |
|---|---|
|
Since it is a scale-up condition, cart_v1 will be scaled up. |
|
Since it is a scale-up condition, cart_v1 will be scaled up. |
|
No scaling actions. |
|
No scaling actions because the autoscaler metric is within the threshold. |
|
Since it is a scale-down condition, cart_v1 will be scaled down. |
|
Even though it is a scale-down condition, cart_v1 will not be scaled down because the SLI is violated. |
