









Para permitir que los desarrolladores implementen cargas de trabajo de AI/ML en clústeres TKG, como administrador de vSphere, configure el entorno de Supervisor para que admita el hardware de NVIDIA GPU.
Paso 1 del administrador: revisar los requisitos del sistema
| Requisito | Descripción |
|---|---|
| infraestructura de vSphere 8 |
vCenter Server y hosts ESXi |
| Licencia de administración de cargas de trabajo |
Espacios de nombres de vSphere y Supervisor |
| OVA de TKR Ubuntu | |
| Controlador de host NVIDIA vGPU |
Descargue el VIB del sitio web de NGC. Si desea más información, consulte la documentación del controlador del software vGPU. |
| Servidor de licencias NVIDIA para vGPU |
FQDN proporcionado por la organización |
Paso 2 del administrador: instalar un dispositivo NVIDIA GPU compatible en hosts ESXi
Para implementar cargas de trabajo de AI/ML en TKG, instale uno o varios dispositivos NVIDIA GPU compatibles en cada host ESXi que contenga el clúster de vCenter en el que se habilitará Administración de cargas de trabajo.
Para ver los dispositivos NVIDIA GPU compatibles, consulte la guía de compatibilidad de VMware.

El dispositivo NVIDIA GPU debe admitir los perfiles de vGPU NVIDIA AI Enterprise (NVAIE) más recientes. Consulte la documentación de GPU compatibles con el software NVIDIA Virtual GPU para obtener instrucciones.
Por ejemplo, el siguiente host ESXi tiene dos dispositivos NVIDIA GPU A100 instalados.
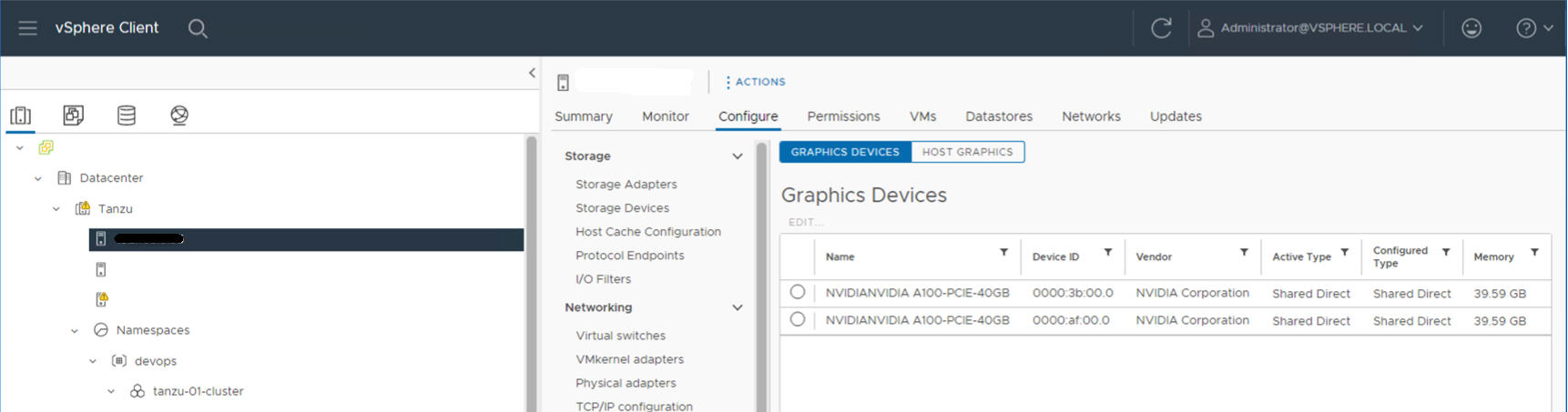
Paso 3 del administrador: configurar cada host ESXi para operaciones de vGPU
Para cada host ESXi que contenga el clúster de vCenter en el que esté habilitada la Administración de cargas de trabajo, configure el host para NVIDIA vGPU habilitando Compartidos directos y SR-IOV.
Habilitar Compartidos directos en cada host ESXi
Para aprovechar la funcionalidad NVIDIA vGPU, habilite el modo Compartidos directos en cada host ESXi que contenga el clúster de vCenter en el que esté habilitada la Administración de cargas de trabajo.
- Inicie sesión en vCenter Server mediante vSphere Client.
- Seleccione un host ESXi en el clúster de vCenter.
- Seleccione .
- Seleccione el dispositivo acelerador de NVIDIA GPU.
- Edite la configuración de dispositivos de gráficos.
- Seleccione Compartidos directos.
- Para la Directiva de asignación de GPU de acceso directo compartido, si desea obtener el mejor rendimiento, seleccione Máquinas virtuales extendidas entre las GPU
- Haga clic en Aceptar para guardar la configuración.
- Tenga en cuenta que la configuración se aplicará después de reiniciar el host.
- Haga clic con el botón secundario en el host ESXi y póngalo en el modo de mantenimiento.
- Reinicie el host.
- Cuando el host vuelva a ejecutarse, salga del modo de mantenimiento.
- Repita este proceso para cada host ESXi en el clúster de vSphere que admita la Administración de cargas de trabajo.
Activar el BIOS de SR-IOV para dispositivos NVIDIA GPU A30 y A100
Si utiliza los dispositivos GPU NVIDIA A30 o A100, los cuales son necesarios para GPU de varias instancias (modo MIG), debe habilitar SR-IOV en el host ESXi. Si SR-IOV no está habilitado, no se pueden iniciar las máquinas virtuales del nodo del clúster de Tanzu Kubernetes. Si esto ocurre, verá el siguiente mensaje de error en el panel Tareas recientes de vCenter Server en el que está habilitada Administración de cargas de trabajo.
Could not initialize plugin libnvidia-vgx.so for vGPU nvidia_aXXX-xx. Failed to start the virtual machine. Module DevicePowerOn power on failed.
Para habilitar SR-IOV, inicie sesión en el host ESXi mediante la consola web. Seleccione . Seleccione el dispositivo NVIDIA GPU y haga clic en Configurar SR-IOV. Desde ahí, puede activar SR-IOV. Para ver más instrucciones, consulte Single Root I/O Virtualization (SR-IOV) en la documentación de vSphere.
vGPU con Instancia dinámica de DirectPath I/O (Dispositivo habilitado para acceso directo)
- Inicie sesión en vCenter Server mediante vSphere Client.
- Seleccione el host ESXi de destino en el clúster de vCenter.
- Seleccione .
- Seleccione la pestaña Todos los dispositivos PCI.
- Seleccione el dispositivo acelerador de NVIDIA GPU de destino.
- Haga clic en Alternar acceso directo.
- Haga clic con el botón secundario en el host ESXi y póngalo en el modo de mantenimiento.
- Reinicie el host.
- Cuando el host vuelva a ejecutarse, salga del modo de mantenimiento.
Paso 4 del administrador: instalar el controlador del administrador de hosts de NVIDIA en cada host ESXi
Para ejecutar las máquinas virtuales del nodo del clúster de Tanzu Kubernetes con aceleración de gráficos NVIDIA vGPU, instale el controlador del administrador de hosts de NVIDIA en cada host ESXi que contenga el clúster de vCenter en el que se habilitará Administración de cargas de trabajo.
Los componentes del controlador del administrador de hosts NVIDIA vGPU se empaquetan en un paquete de instalación de vSphere (VIB). La organización le proporciona el VIB de NVAIE a través de su programa de licencias NVIDIA GRID. VMware no proporciona los VIB de NVAIE ni hace que estén disponibles para descargarlos. Como parte del programa de licencias NVIDIA, su organización configura un servidor de licencias. Consulte la Guía de inicio rápido del software de GPU virtual para obtener más información.
esxcli system maintenanceMode set --enable true esxcli software vib install -v ftp://server.domain.example.com/nvidia/signed/NVIDIA_bootbank_NVIDIA-VMware_ESXi_7.0_Host_Driver_460.73.02-1OEM.700.0.0.15525992.vib esxcli system maintenanceMode set --enable false /etc/init.d/xorg restart
Paso 5 del administrador: comprobar que los hosts ESXi estén listos para las operaciones de NVIDIA vGPU
- Acceda mediante SSH al host ESXi, entre en el modo de shell y ejecute el comando
nvidia-smi. La interfaz de administración del sistema NVIDIA es una utilidad de línea de comandos que proporciona el administrador de hosts de NVIDIA vGPU. Al ejecutar este comando, se devuelven los controladores y las GPU en el host. - Ejecute el siguiente comando para comprobar que el controlador de NVIDIA esté instalado correctamente:
esxcli software vib list | grep NVIDA. - Compruebe que el host esté configurado con Compartidos directos de GPU y que SR-IOV esté activado (si utiliza dispositivos NVIDIA A30 o A100).
- Con vSphere Client, en el host ESXi que está configurado para GPU, cree una nueva máquina virtual con un dispositivo PCI incluido. El perfil de NVIDIA vGPU debe aparecer y se debe poder seleccionar.
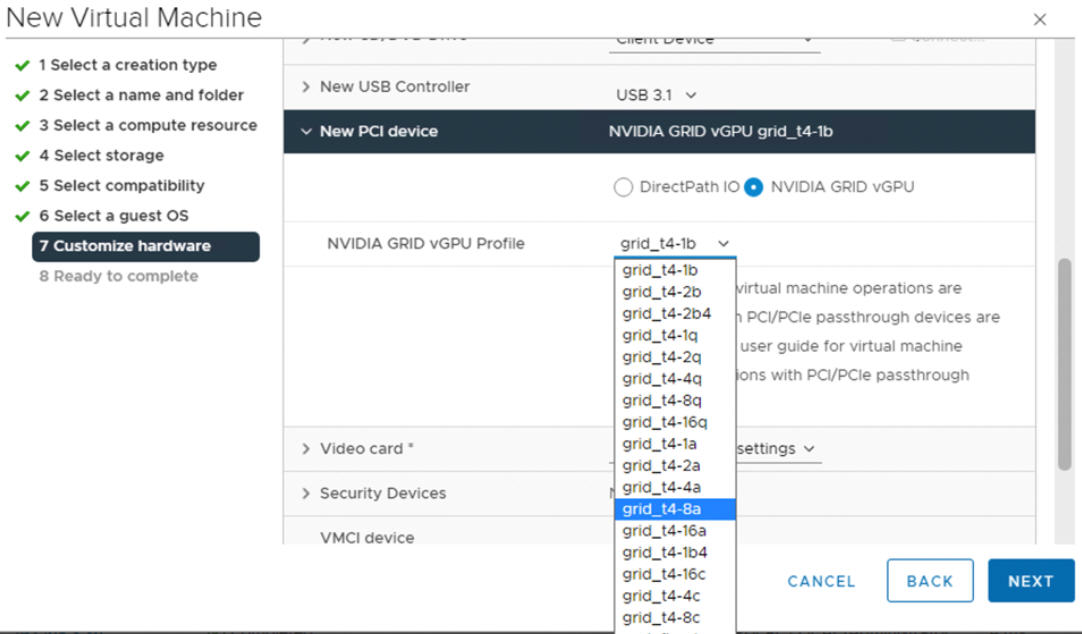
Paso 6 del administrador: habilitar administración de cargas de trabajo
Paso 7 del administrador: crear o actualizar una biblioteca de contenido con una TKR para Ubuntu
NVIDIA vGPU requiere el sistema operativo Ubuntu. No es posible utilizar la edición de PhotonOS de una versión de Tanzu Kubernetes para clústeres de vGPU.
VMware proporciona ediciones de Ubuntu de versiones de Tanzu Kubernetes. A partir de vSphere 8, la edición de Ubuntu se especifica mediante una anotación en el YAML del clúster.
Paso 8 del administrador: crear una clase de máquina virtual personalizada con el perfil de vGPU
Cree una clase de máquina virtual personalizada con un perfil de vGPU. A continuación, utilizará esta clase de máquina virtual en la especificación del clúster para crear los nodos del clúster de TKGS. Consulte las siguientes instrucciones: Crear una clase de máquina virtual personalizada para dispositivos vGPU de NVIDIA.
Paso 9 del administrador: Configurar el espacio de nombres de vSphere
Cree un espacio de nombres de vSphere para cada clúster de TKG vGPU que tenga previsto aprovisionar. Consulte Crear un espacio de nombres de vSphere para alojar clústeres de Servicio TKG.
Para configurar el espacio de nombres de vSphere, agregue usuarios o grupos de SSO de vSphere con permisos de edición y asocie una directiva de almacenamiento para volúmenes persistentes. Consulte Configurar un espacio de nombres de vSphere para clústeres de Servicio TKG.
Asocie la biblioteca de contenido de TKR en la que se almacena la imagen de Ubuntu deseada con el espacio de nombres de vSphere. Consulte Asociar la biblioteca de contenido de TKR al Servicio TKG.
- En el espacio de nombres de vSphere, seleccione el mosaico Servicios de máquina virtual y haga clic en Administrar clases de máquina virtual.
- Busque la clase de máquina virtual personalizada que creó en la lista de clases.
- Seleccione la clase y haga clic en Agregar.
Paso 10 del administrador: Comprobar que Supervisor esté listo
La última tarea de administración consiste en comprobar que Supervisor esté aprovisionado y disponible para que lo pueda utilizar el operador del clúster a fin de aprovisionar un clúster de TKG para cargas de trabajo de AI/ML.
Consulte Conectarse a clústeres de Servicio TKG mediante la autenticación de vCenter SSO.
