









Pour permettre aux développeurs de déployer des charges de travail AI/ML sur des clusters TKGS, en tant qu'administrateur de cluster, vous configurez l'environnement vSphere with Tanzu pour prendre en charge le matériel NVIDIA vGPU.
Workflow de l'administrateur vSphere pour le déploiement de charges de travail AI/ML sur des clusters TKGS
| Étape | Action | Lier |
|---|---|---|
| 0 | Vérifiez la configuration système requise. |
Reportez-vous à la section Étape 0 pour l'administrateur : Vérification de la configuration système requise. |
| 1 | Installez le périphérique NVIDIA GPU pris en charge sur les hôtes ESXi. |
Reportez-vous à la section Étape 1 pour l'administrateur : Installation du périphérique NVIDIA GPU pris en charge sur les hôtes ESXi. |
| 2 | Configurez les paramètres graphiques du périphérique ESXi pour les opérations du vGPU. |
Reportez-vous à la section Étape 2 pour l'administrateur : Configuration de chaque hôte ESXi pour les opérations vGPU. |
| 3 | Installez NVIDIA vGPU Manager (VIB) sur chaque hôte ESXi. |
Reportez-vous à la section Étape 3 pour l'administrateur : Installation du pilote du gestionnaire d'hôte NVIDIA sur chaque hôte ESXi. |
| 4 | Vérifiez le fonctionnement du pilote NVIDIA et le mode de virtualisation du GPU. |
Reportez-vous à la section Étape 4 pour l'administrateur : Vérifier que les hôtes ESXi sont prêts pour les opérations NVIDIA vGPU. |
| 5 | Activez la gestion de la charge de travail sur le cluster configuré pour GPU. Il en résulte un cluster superviseur qui s'exécute sur des hôtes ESXi compatibles avec vGPU. |
Reportez-vous à la section Étape 5 pour l'administrateur : Activation de la gestion de la charge de travail sur le cluster vCenter configuré par vGPU. |
| 6 | Créez* ou mettez à jour une bibliothèque de contenu pour les versions de Tanzu Kubernetes et remplissez la bibliothèque avec le fichier OVA Ubuntu pris en charge qui est requis pour les charges de travail vGPU. |
Reportez-vous à la section
Étape 6 pour l'administrateur : Création ou mise à jour d'une bibliothèque de contenu avec la version Tanzu Kubernetes Ubuntu.
Note : * Si nécessaire. Si vous disposez déjà d'une bibliothèque de contenu pour les images Photon des clusters TKGS, ne créez pas de bibliothèque de contenu pour les images Ubuntu.
|
| 7 | Créez une classe de machine virtuelle personnalisée avec un certain profil vGPU sélectionné. |
Reportez-vous à la section Étape 7 pour l'administrateur : Création d'une classe de machine virtuelle personnalisée avec le profil vGPU. |
| 8 | Créez et configurez un espace de noms vSphere pour les clusters TKGS GPU : ajoutez un utilisateur disposant d'autorisations de modification et un stockage pour les volumes persistants. |
Reportez-vous à la section Étape 8 pour l'administrateur : Création et configuration d'un espace de noms vSphere pour le cluster GPU TKGS. |
| 9 | Associez la bibliothèque de contenu au fichier OVA Ubuntu et à la classe de machine virtuelle personnalisée pour vGPU à l'espace de noms vSphere que vous avez créé pour TGKS. |
Reportez-vous à la section Étape 9 pour l'administrateur : Association de la bibliothèque de contenu et de la classe de machine virtuelle à l'espace de noms vSphere. |
| 10 | Assurez-vous que le cluster superviseur est provisionné et accessible pour l'opérateur de cluster. |
Reportez-vous à la section Étape 10 pour l'administrateur : Vérification de l'accessibilité du cluster superviseur. |
Étape 0 pour l'administrateur : Vérification de la configuration système requise
| Serveur | Description |
|---|---|
| infrastructure vSphere |
vSphere 7 Update 3 Correctif mensuel 1 ESXi build vCenter Server build |
| Gestion de la charge de travail |
Version de l'espace de noms vSphere
|
| Cluster superviseur |
Version de Cluster superviseur
|
| Fichier OVA TKR Ubuntu | Version de Tanzu Kubernetes Ubuntu
|
| Pilote d'hôte NVIDIA vGPU |
Téléchargez le VIB à partir du site Web NGC. Pour plus d'informations, reportez-vous à la documentation relative au pilote logiciel de vGPU. Par exemple :
|
| License Server NVIDIA pour vGPU |
Nom de domaine complet fourni par votre organisation |
Étape 1 pour l'administrateur : Installation du périphérique NVIDIA GPU pris en charge sur les hôtes ESXi
Pour déployer des charges de travail AI/ML sur TKGS, installez un ou plusieurs périphériques NVIDIA GPU pris en charge sur chaque hôte ESXi comprenant le cluster vCenter où la gestion de la charge de travai sera activée.
Pour afficher les périphériques NVIDIA GPU compatibles, reportez-vous au Guide de compatibilité VMware.
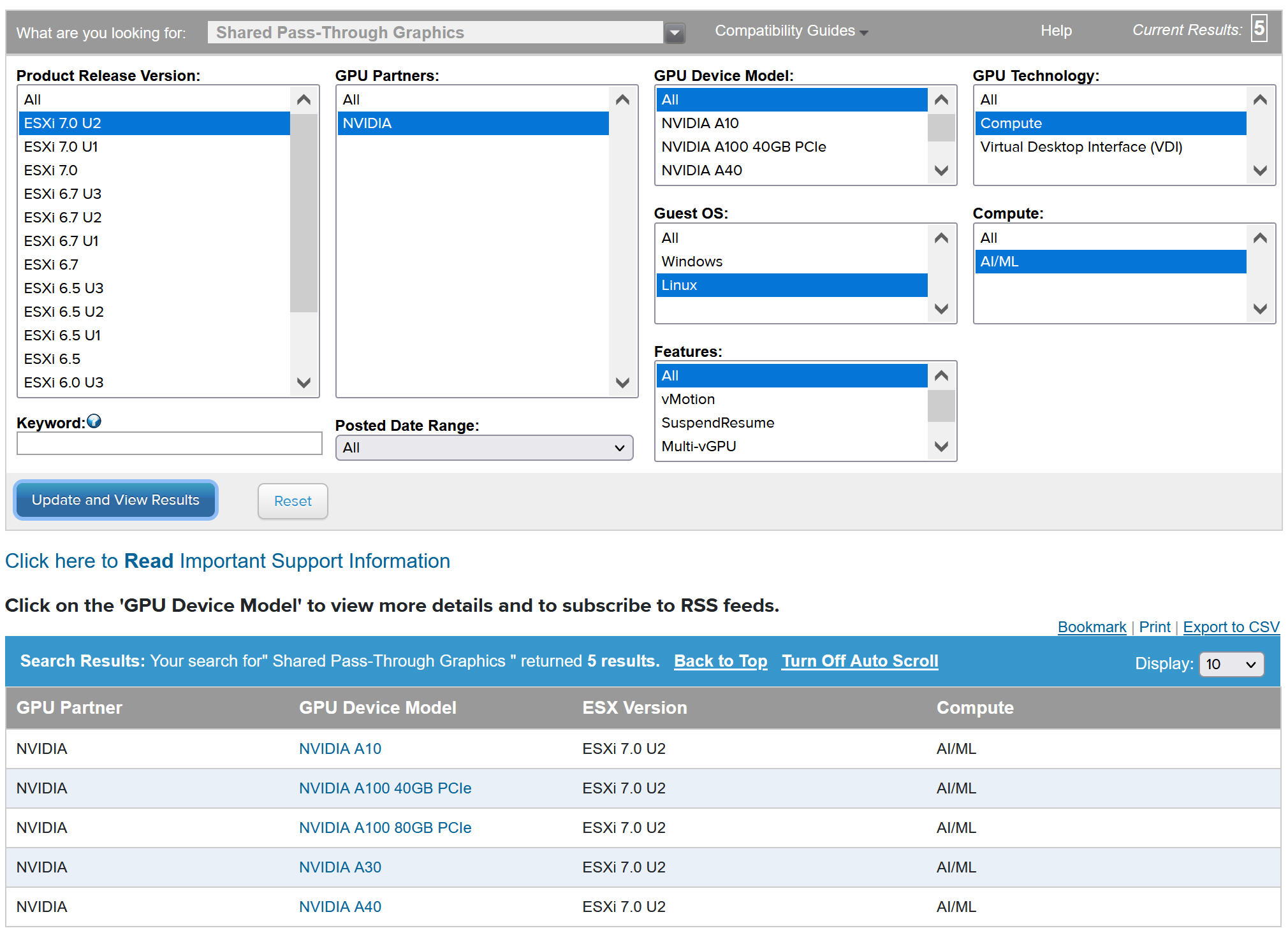
Le périphérique NVIDA GPU doit prendre en charge les derniers profils vGPU de NVIDIA AI Enterprise (NVAIE). Reportez-vous à la documentation sur les GPU pris en charge par le logiciel NVIDIA Virtual GPU pour obtenir des instructions.
Par exemple, deux périphériques NVIDIA GPU A100 sont installés sur l'hôte ESXi suivant.

Étape 2 pour l'administrateur : Configuration de chaque hôte ESXi pour les opérations vGPU
Configurez chaque hôte ESXi pour vGPU en activant Partagés en direct et SR-IOV.
Activer Partagés en direct sur chaque hôte ESXi
Pour déverrouiller la fonctionnalité NVIDIA vGPU, activez le mode Partagés en direct sur chaque hôte ESXi comprenant le cluster vCenter où la Gestion de la charge de travail sera activée.
- Connectez-vous à vCenter Server à l'aide du vSphere Client.
- Sélectionnez un hôte ESXi dans le cluster vCenter.
- Sélectionnez .
- Sélectionnez le périphérique accélérateur NVIDIA GPU.
- Modifiez les paramètres des périphériques graphiques.
- Sélectionnez Partagés en direct.
- Sélectionner Redémarrer le serveur X.Org.
- Cliquez sur OK pour enregistrer la configuration.
- Cliquez avec le bouton droit sur l'hôte ESXi et mettez-le en mode maintenance.
- Redémarrez l'hôte.
- Lorsque l'hôte s'exécute à nouveau, faites-le sortir du mode maintenance.
- Répétez ce processus pour chaque hôte ESXi dans le cluster vCenter où la Gestion de la charge de travail sera activée.

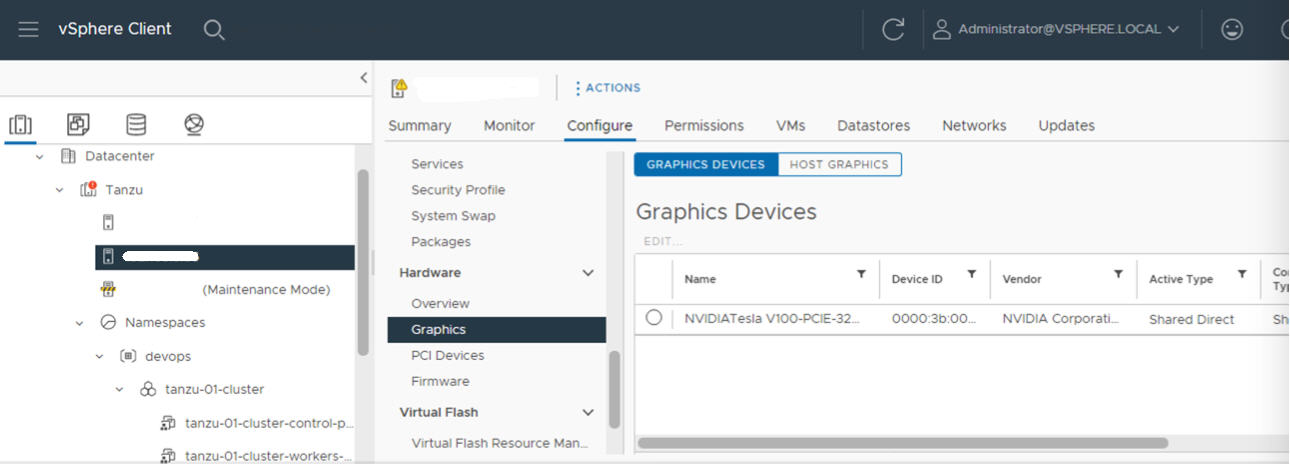
Activer le BIOS SR-IOV pour les périphériques NVIDIA GPU A30 et A100
Si vous utilisez les périphériques NVIDIA GPU A30 ou A100, qui sont requis pour le GPU à plusieurs instances (mode MIG), vous devez activer SR-IOV sur l'hôte ESXi. Si SR-IOV n'est pas activé, les machines virtuelles du nœud de cluster Tanzu Kubernetes ne peuvent pas démarrer. Si cela se produit, le message d'erreur suivant s'affiche dans le volet Tâches récentes du vCenter Server où la Gestion de la charge de travail est activée.
Could not initialize plugin libnvidia-vgx.so for vGPU nvidia_aXXX-xx. Failed to start the virtual machine. Module DevicePowerOn power on failed.
Pour activer SR-IOV, connectez-vous à l'hôte ESXi à l'aide de la console Web. Sélectionnez . Sélectionnez le périphérique NVIDIA GPU et cliquez sur Configurer SR-IOV. À partir de là, vous pouvez activer SR-IOV. Pour obtenir des instructions supplémentaires, reportez-vous à la section Single Root I/O Virtualization (SR-IOV) de la documentation vSphere.
Étape 3 pour l'administrateur : Installation du pilote du gestionnaire d'hôte NVIDIA sur chaque hôte ESXi
Pour exécuter des machines virtuelles de nœud de cluster Tanzu Kubernetes avec l'accélération graphique NVIDIA vGPU, installez le pilote du gestionnaire d'hôte NVIDIA sur chaque hôte ESXi comprenant le cluster vCenter où la Gestion de la charge de travail sera activée.
Les composants du pilote du gestionnaire d'hôte NVIDIA vGPU sont regroupés dans un bundle d'installation de vSphere (VIB). Le VIB NVAIE vous est fourni par votre organisation via son programme d'attribution de licences NVIDIA GRID. VMware ne fournit pas de VIB NVAIE ou ne les rend pas disponibles au téléchargement. Dans le cadre du programme d'attribution de licences NVIDIA, votre organisation configure un serveur d'attribution de licences. Pour plus d'informations, reportez-vous au Guide de démarrage rapide du logiciel NVIDIA Virtual GPU.
esxcli system maintenanceMode set --enable true esxcli software vib install -v ftp://server.domain.example.com/nvidia/signed/NVIDIA_bootbank_NVIDIA-VMware_ESXi_7.0_Host_Driver_460.73.02-1OEM.700.0.0.15525992.vib esxcli system maintenanceMode set --enable false /etc/init.d/xorg restart
Étape 4 pour l'administrateur : Vérifier que les hôtes ESXi sont prêts pour les opérations NVIDIA vGPU
- Utilisez le SSH pour vous connecter à l'hôte ESXi, entrez en mode interpréteur de commandes et exécutez la commande
nvidia-smi. L'interface de gestion du système NVIDIA est un utilitaire de ligne de commande fourni par le gestionnaire d'hôte NVIDA vGPU. L'exécution de cette commande renvoie les GPU et les pilotes sur l'hôte. - Exécutez la commande suivante pour vérifier que le pilote NVIDIA est correctement installé :
esxcli software vib list | grep NVIDA. - Vérifiez que l'hôte est configuré avec le mode Partagés en direct pour le GPU et que le SR-IOV est activé (si vous utilisez des périphériques NVIDIA A30 ou A100).
- À l'aide du vSphere Client, sur l'hôte ESXi configuré pour le GPU, créez une machine virtuelle avec un périphérique PCI inclus. Le profil NVIDIA vGPU doit s'afficher et être sélectionnable.
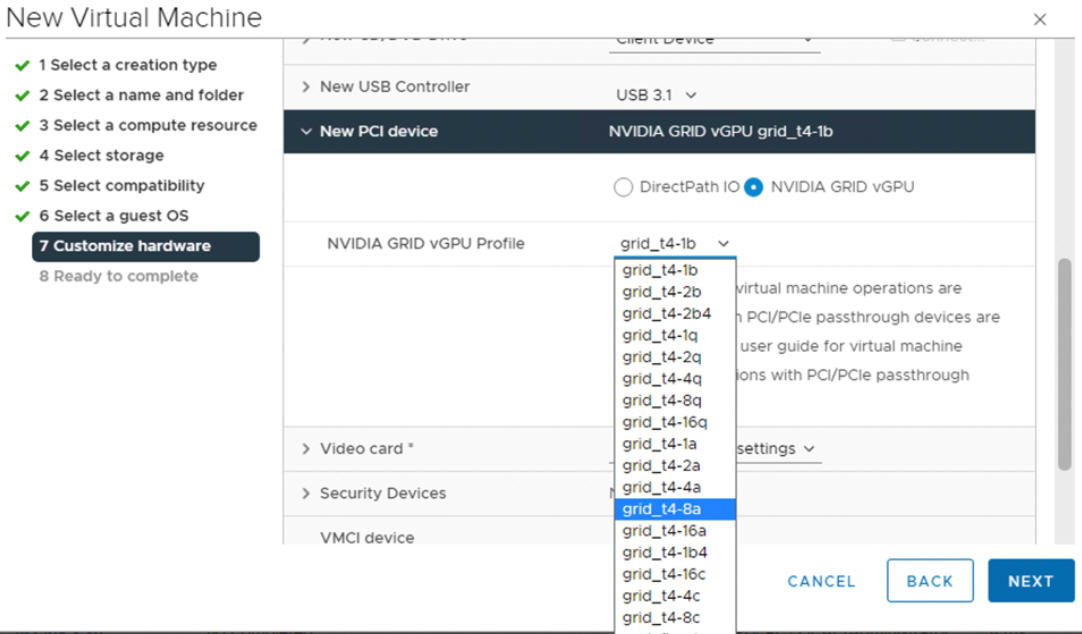
Étape 5 pour l'administrateur : Activation de la gestion de la charge de travail sur le cluster vCenter configuré par vGPU
Maintenant que les hôtes ESXi sont configurés pour prendre en charge NVIDIA vGPU, créez un cluster vCenter comprenant ces hôtes. Pour prendre en charge la Gestion de la charge de travail, le cluster vCenter doit répondre à des exigences spécifiques, notamment un stockage partagé, une haute disponibilité et un DRS entièrement automatisé.
L'activation de la Gestion de la charge de travail nécessite également de sélectionner une pile de mise en réseau, qu'il s'agisse d'une mise en réseau vSphere vDS native ou d'une mise en réseau NSX-T Data Center. Si vous utilisez la mise en réseau vDS, vous devez installer un équilibrage de charge, NSX Advanced ou HAProxy.
| Tâche | Instructions |
|---|---|
| Créez un cluster vCenter qui répond aux conditions requises pour activer la Gestion de la charge de travail | Conditions préalables à la configuration de vSphere with Tanzu sur un cluster vSphere |
| Configurez la mise en réseau du Cluster superviseur, NSX-T ou vDS avec équilibrage de charge. | Configuration de NSX-T Data Center pour vSphere with Tanzu. Configuration de la mise en réseau vSphere et de NSX Advanced Load Balancer pour vSphere with Tanzu. |
| Activer la Gestion de la charge de travail |
Activer la gestion de la charge de travail avec la mise en réseau NSX-T Data Center. Activer la gestion de la charge de travail avec la mise en réseau vSphere. |
Étape 6 pour l'administrateur : Création ou mise à jour d'une bibliothèque de contenu avec la version Tanzu Kubernetes Ubuntu
NVIDIA vGPU requiert le système d'exploitation Ubuntu. VMware fournit un fichier OVA Ubuntu à ces fins. Vous ne pouvez pas utiliser la version Tanzu Kubernetes photonOS pour les clusters vGPU.
| Type de bibliothèque de contenu | Description |
|---|---|
| Créez une bibliothèque de contenu abonnée et synchronisez automatiquement le fichier OVA Ubuntu avec votre environnement. | Créer, sécurisez et synchronisez une bibliothèque de contenu abonnée pour Versions de Tanzu Kubernetes |
| Créez une bibliothèque de contenu locale et téléchargez manuellement le fichier OVA Ubuntu dans votre environnement. | Créer, sécuriser et synchroniser une bibliothèque de contenu locale pour Versions de Tanzu Kubernetes |

Étape 7 pour l'administrateur : Création d'une classe de machine virtuelle personnalisée avec le profil vGPU
L'étape suivante consiste à créer une classe de machine virtuelle personnalisée avec un profil vGPU. Le système utilisera cette définition de classe lorsqu'il créera les nœuds de cluster Tanzu Kubernetes.
- Connectez-vous au vCenter Server à l'aide de vSphere Client.
- Sélectionnez Gestion de la charge de travail.
- Sélectionnez Services.
- Sélectionnez Classes de VM.
- Cliquez sur Créer une classe de VM.
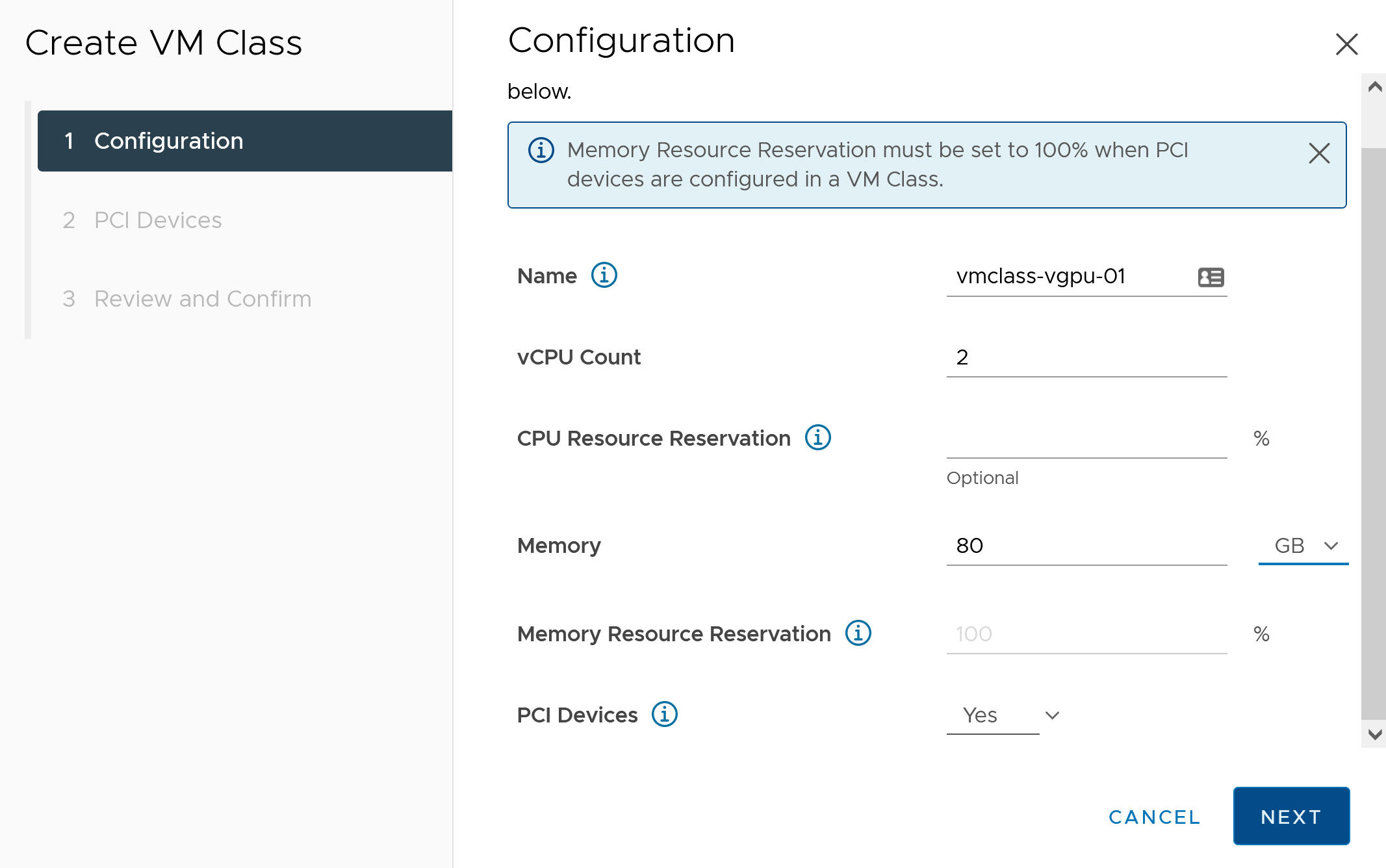
- Dans l'onglet Configuration, configurez la classe de machine virtuelle personnalisée.
Champ de configuration Description Nom Entrez un nom explicite pour la classe de machine virtuelle personnalisée, par exemple vmclass-vgpu-1. Nombre de vCPU 2 Réservation de ressource de CPU Facultatif ; ce champ peut être laissé vide Mémoire 80 Go, par exemple Réservation de ressource de mémoire 100 % (obligatoire lorsque des périphériques PCI sont configurés dans une classe de machine virtuelle) Périphériques PCI Oui Note : Si vous sélectionnez Oui pour les périphériques PCI, vous indiquez au système que vous utilisez un périphérique GPU. Cela modifie la configuration de la classe de machine virtuelle afin de prendre en charge la configuration du vGPU.Par exemple :
- Cliquez sur Suivant.
- Dans l'onglet Périphériques PCI, sélectionnez l'option .
- Configurez le modèle NVIDIA vGPU.
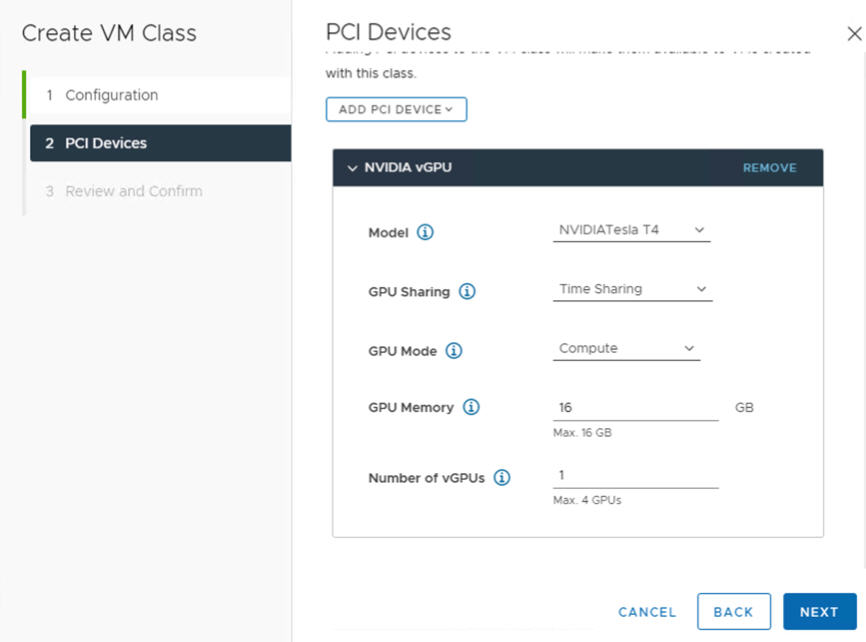
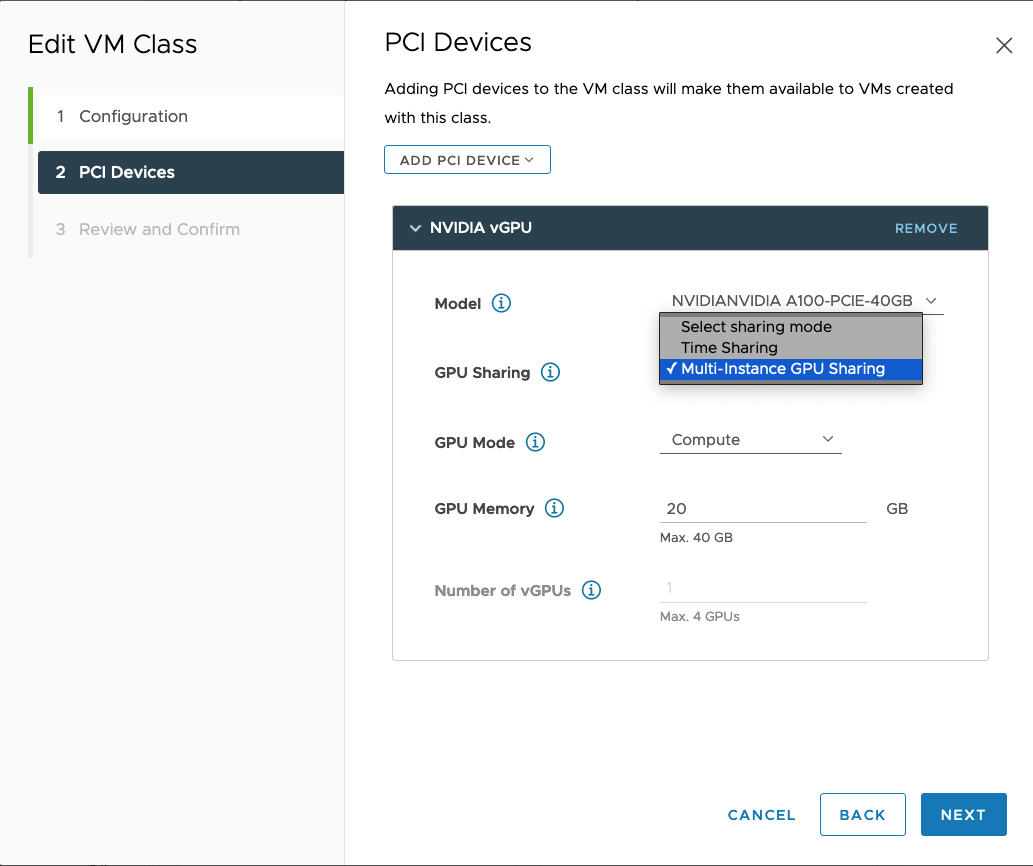
Champ NVIDIA vGPU Description Modèle Sélectionnez le modèle de périphérique matériel NVIDIA GPU parmi ceux disponibles dans le menu . Si le système n'affiche aucun profil, aucun des hôtes du cluster n'a de périphériques PCI pris en charge. Partage de GPU Ce paramètre définit la manière dont le périphérique GPU est partagé entre les machines virtuelles avec GPU activé. Il existe deux types de mises en œuvre de vGPU : Partage de temps et Partage de GPU multi-instances.
En mode Partage de temps, le planificateur vGPU demande au GPU d'effectuer le travail pour chaque machine virtuelle sur laquelle vGPU est activé en série pendant une durée donnée dans le but d'équilibrer les performances entre les vGPU.
Le mode MIG permet à plusieurs machines virtuelles compatibles avec le vGPU de s'exécuter en en parallèle sur un seul périphérique GPU. Le mode MIG est basé sur une architecture GPU plus récente et n'est pris en charge que sur les périphériques NVIDIA A100 et A30. Si vous ne voyez pas l'option MIG, le périphérique PCI que vous avez sélectionné ne le prend pas en charge.
Mode GPU Calculer Mémoire GPU 8 Go, par exemple Nombre de vGPU 1, par exemple À titre d'exemple, voici un profil NVIDIA vGPU configuré en mode de partage de temps :
À titre d'exemple, voici un profil NVIDIA vGPU configuré en mode MIG avec un périphérique GPU pris en charge :
- Cliquez sur Suivant.
- Vérifiez et confirmez vos sélections.
- Cliquez sur Terminer.
- Assurez-vous que la nouvelle classe de machine virtuelle personnalisée est disponible dans la liste des classes de machines virtuelles.
Étape 8 pour l'administrateur : Création et configuration d'un espace de noms vSphere pour le cluster GPU TKGS
Créez un espace de noms vSphere pour chaque cluster TKGS GPU que vous prévoyez de provisionner. Configurez l'espace de noms en ajoutant un utilisateur SSO vSphere disposant des autorisations de modification, puis attachez une stratégie de stockage pour les volumes persistants.
Pour cela, reportez-vous à Créer et configurer un Espace de noms vSphere
Étape 9 pour l'administrateur : Association de la bibliothèque de contenu et de la classe de machine virtuelle à l'espace de noms vSphere
| Tâche | Description |
|---|---|
| Associez la bibliothèque de contenu avec le fichier OVA Ubuntu pour vGPU à l'espace de noms vSphere dans lequel vous allez provisionner le cluster TKGS. | Reportez-vous à la section Configurer un Espace de noms vSphere pour des Versions de Tanzu Kubernetes. |
| Associez la classe de machine virtuelle personnalisée avec le profil vGPU à l'espace de noms vSphere dans lequel vous allez provisionner le cluster TKGS. | Reportez-vous à la section Associer une classe de machine virtuelle à un espace de noms dans vSphere with Tanzu. |
Étape 10 pour l'administrateur : Vérification de l'accessibilité du cluster superviseur
La dernière tâche d'administration consiste à vérifier que le Cluster superviseur est provisionné et disponible pour être utilisé par l'opérateur de cluster afin de provisionner un cluster TKGS pour les charges de travail AI/ML.
- Téléchargez et installez les Outils de l'interface de ligne de commande Kubernetes pour vSphere .
Reportez-vous à la section Télécharger et installer les Outils de l'interface de ligne de commande Kubernetes pour vSphere.
- Connectez-vous au Cluster superviseur.
Reportez-vous à la section Se connecter à Cluster superviseur en tant qu'utilisateur vCenter Single Sign-On.
- Fournissez à l'opérateur de cluster le lien permettant de télécharger le Outils de l'interface de ligne de commande Kubernetes pour vSphere et le nom de l'espace de noms vSphere.
Reportez-vous à la section Workflow de l'opérateur de cluster pour le déploiement de charges de travail AI/ML sur des clusters TKGS.
