









VMware Aria Automation fornisce supporto per gli elementi catalogo self-service che i tecnici devOps e i data scientist possono utilizzare per eseguire il provisioning dei carichi di lavoro AI in VMware Private AI Foundation with NVIDIA in modo semplice e personalizzabile.
Prerequisiti
In qualità di amministratore del cloud, verificare che l'ambiente VMware Private AI Foundation with NVIDIA sia configurato. Vedere Preparazione di VMware Cloud Foundation per la distribuzione del carico di lavoro di Private AI.
Connessione di VMware Aria Automation a un dominio del carico di lavoro per VMware Private AI Foundation with NVIDIA
Prima di poter aggiungere elementi del catalogo per il provisioning delle applicazioni di intelligenza artificiale utilizzando VMware Aria Automation, connettere VMware Aria Automation a VMware Cloud Foundation.
Procedura
Creazione di elementi del catalogo di AI in VMware Aria Automation tramite la configurazione guidata del catalogo
In qualità di amministratore del cloud, è possibile utilizzare la configurazione guidata del catalogo in VMware Aria Automation per configurare e fornire istanze di Deep Learning VM abilitate per GPU e cluster VMware Tanzu Kubernetes Grid (TKG) come elementi del catalogo che i data scientist e i team DevOps dell'organizzazione possono richiedere nel catalogo self-service di Automation Service Broker.
Come funziona l'installazione guidata del catalogo
- Aggiungere un account cloud. Gli account cloud sono le credenziali utilizzate per raccogliere dati dall'istanza di vCenter e distribuire risorse in tale istanza.
- Aggiungere una licenza di NVIDIA.
- Configurare un'integrazione di VMware Data Services Manager.
- Selezionare il contenuto da aggiungere al catalogo di Automation Service Broker.
- Creare un progetto. Il progetto collega gli utenti alle regioni dell'account cloud, in modo che possano distribuire modelli cloud con reti e risorse di storage nell'istanza di vCenter.
- Workstation AI: macchina virtuale abilitata per la GPU che può essere configurata con la vCPU, la vGPU e la memoria desiderate e la possibilità di preinstallare framework AI/ML come PyTorch, esempi di CUDA e TensorFlow.
- Workstation RAG AI: macchina virtuale abilitata per la GPU con soluzione di riferimento Retrieval Augmented Generation (RAG).
- Triton Inference Server: macchina virtuale abilitata per la GPU con Triton Inference Server.
- Cluster Kubernetes AI: cluster VMware Tanzu Kubernetes Grid con nodi worker compatibili con GPU per eseguire carichi di lavoro AI/ML nativi del cloud.
- Cluster RAG Kubernetes AI: cluster VMware Tanzu Kubernetes Grid con nodi worker compatibili con GPU per eseguire una soluzione RAG di riferimento.
- Database DSM: database pgvector gestito da VMware Data Services Manager.
- Workstation RAG AI con DSM: macchina virtuale abilitata per la GPU con un database pgvector gestito da VMware Data Services Manager.
- Cluster RAG Kubernetes AI con DSM: cluster VMware Tanzu Kubernetes Grid con un database pgvector gestito da VMware Data Services Manager.
- Abilitare il provisioning dei carichi di lavoro AI in un altro supervisore.
- Apportare una modifica alla licenza AI Enterprise di NVIDIA, che include il file .tok per la configurazione del client e il server delle licenze o l'URL di download per i driver guest della vGPU per un ambiente disconnesso.
- Apportare una modifica all'immagine di un'istanza di Deep Learning VM.
- Utilizzare altre classi di macchine virtuali vGPU o non GPU, un criterio di storage o un registro di container.
- Creare elementi catalogo in un nuovo progetto.
È possibile modificare i modelli per gli elementi del catalogo creati dalla procedura guidata per soddisfare le esigenze specifiche dell'organizzazione.
Prima di iniziare
- Verificare che VMware Private AI Foundation with NVIDIA sia configurato fino a questo passaggio del workflow di distribuzione. Vedere Preparazione di VMware Cloud Foundation per la distribuzione del carico di lavoro di Private AI.
Procedura
- Dopo aver effettuato l'accesso a VMware Aria Automation, fare clic su Inizia Avvio rapido.
- Nella scheda Private AI Automation Services fare clic su Inizia.
- Selezionare l'account cloud per cui eseguire il provisioning dell'accesso.
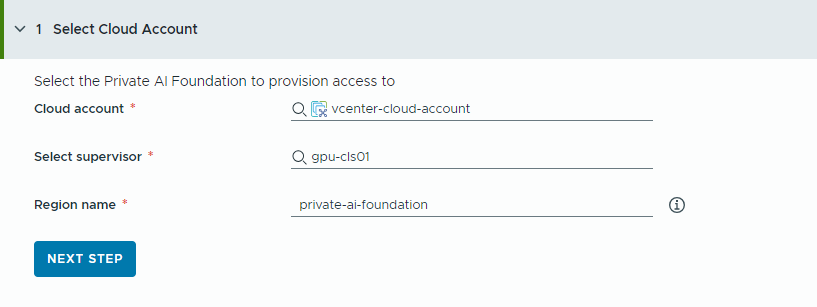
Si tenga presente che tutti i valori indicati qui sono esempi di casi d'uso. I valori effettivi dell'account dipendono dall'ambiente in uso.
- Selezionare un account cloud vCenter.
- Selezionare un supervisore abilitato per la GPU.
- Immettere il nome di una regione.
Se il supervisore è già configurato con una regione, tale regione viene selezionata automaticamente.
Se il supervisore non è associato a una regione, aggiungerne una in questo passaggio. È consigliabile utilizzare un nome descrittivo per la regione che consenta agli utenti di distinguere le regioni abilitate per la GPU dalle altre regioni disponibili.
- Fare clic su Passaggio successivo.
- Inserire le informazioni relative al server delle licenze NVIDIA.
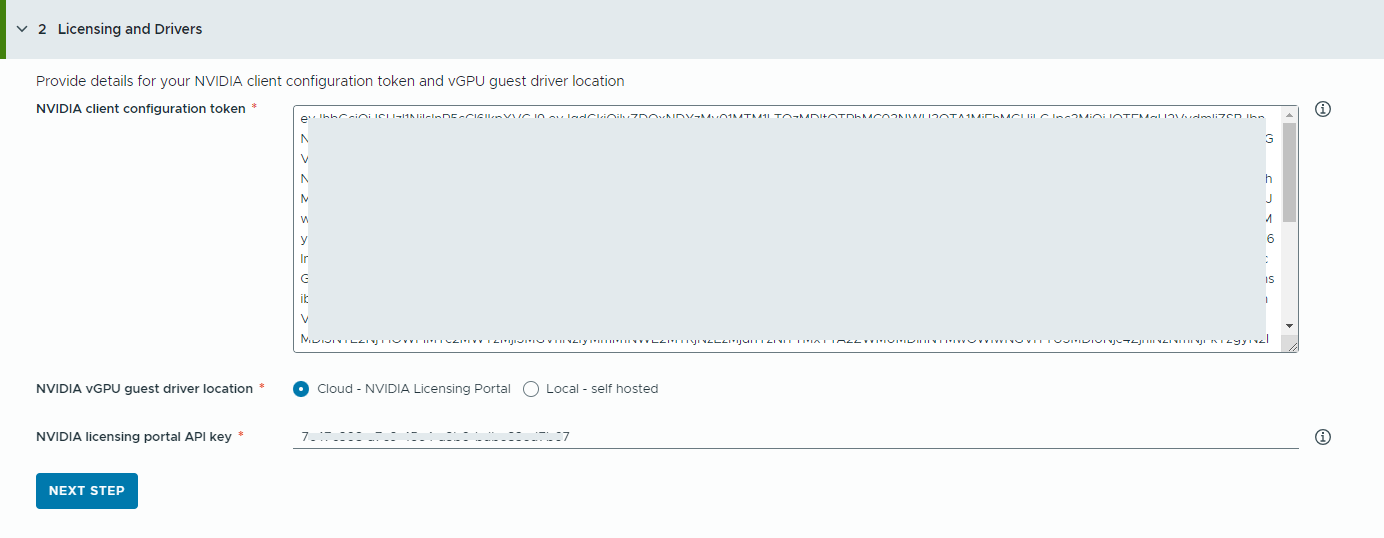
- Copiare e incollare il contenuto del token di configurazione del client NVIDIA.
Il token di configurazione del client viene utilizzato per assegnare una licenza al driver guest della vGPU in Deep Learning VM e agli operatori della GPU nei cluster TKG.
- Selezionare la posizione dei driver della vGPU NVIDIA.
- Cloud: il driver della vGPU NVIDIA è ospitato nel portale delle licenze di NVIDIA.
È necessario specificare la chiave API del portale delle licenze di NVIDIA utilizzata per verificare se un utente dispone delle autorizzazioni corrette per scaricare i driver della vGPU NVIDIA. La chiave API deve essere un UUID.
- Locale: il driver della vGPU NVIDIA è ospitato in locale ed è accessibile tramite una rete privata.
È necessario specificare la posizione dei driver guest della vGPU per le macchine virtuali.
Per gli ambienti air gap, il driver della vGPU deve essere disponibile nella rete privata o nel data center privato.
- Cloud: il driver della vGPU NVIDIA è ospitato nel portale delle licenze di NVIDIA.
- Fare clic su Passaggio successivo.
- Copiare e incollare il contenuto del token di configurazione del client NVIDIA.
- Configurare un database VMware Data Services Manager (DSM) per le applicazioni RAG per generare elementi del catalogo di database separati.
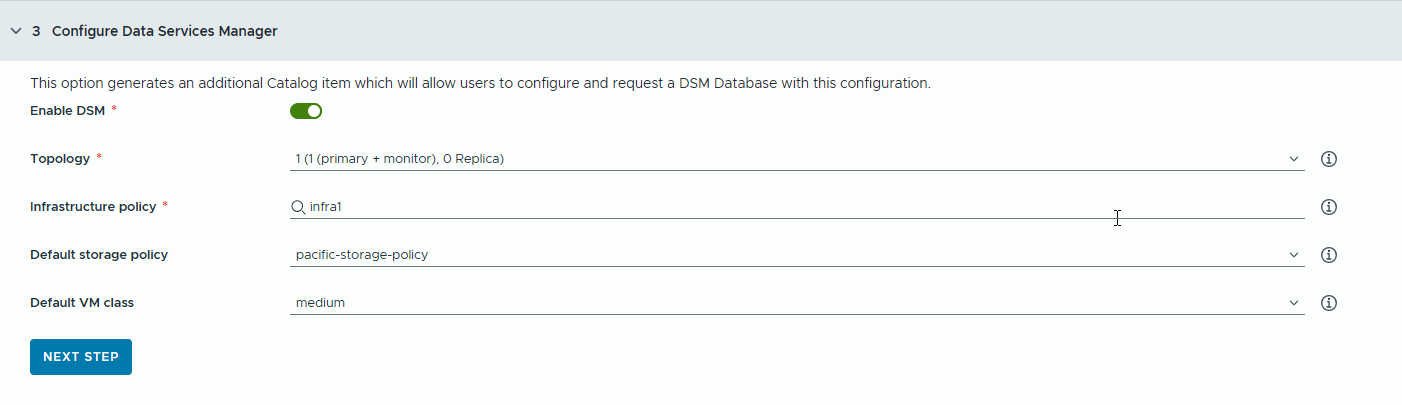
Utilizzare VMware Data Services Manager per creare database vettore, ad esempio un database PostgreSQL con estensione pgvector.
Poiché il provisioning dei database viene eseguito in un dominio del carico di lavoro diverso da quello delle istanze di Deep Learning VM, è necessario utilizzare classi di macchine virtuali e profili di storage diversi per ciascuno. Per i database di VMware Data Services Manager, selezionare un criterio di storage e una classe di macchine virtuali adatti per i casi d'uso di RAG.
- Attivare l'interruttore.
Se si desidera che gli sviluppatori e gli utenti del catalogo convidano un singolo database DSM, utilizzare questa opzione.Nota: Quando l'interruttore è attivato, viene creato un nuovo elemento del catalogo del database DSM.
Se per il progetto non è necessaria un'integrazione di DSM, è possibile disattivare l'interruttore e continuare con il passaggio successivo. In questo caso, non viene generato un elemento del catalogo DSM, ma gli utenti dispongono comunque di un database DSM incorporato negli altri elementi del catalogo RAG.
- Selezionare una modalità di replica e una topologia.
La configurazione dei nodi del database dipende dalla modalità di replica.
- Server singolo: un nodo primario senza repliche.
- Cluster vSphere singolo: tre nodi (1 primario, 1 di monitoraggio e 1 di replica) in un singolo cluster vSphere che fornisce aggiornamenti senza interruzioni.
- Selezionare un criterio dell'infrastruttura.
Il criterio dell'infrastruttura definisce la qualità e la quantità di risorse che il database può utilizzare nei cluster vSphere.
Dopo aver selezionato un criterio dell'infrastruttura, è possibile scegliere tra i criteri di storage e le classi di macchine virtuali associate al criterio dell'infrastruttura.
- Selezionare un criterio di storage predefinito.
Il criterio di storage definisce il posizionamento dello storage e le risorse per il database.
- Selezionare una classe di macchine virtuali predefinita.
Non è disponibile una classe di macchine virtuali in cui effettuare il provisioning del database appena richiesto.
Si tenga presente che le classi di macchine virtuali DSM sono diverse dalle classi di macchine virtuali del supervisore.
- Attivare l'interruttore.
- Configurare gli elementi del catalogo.
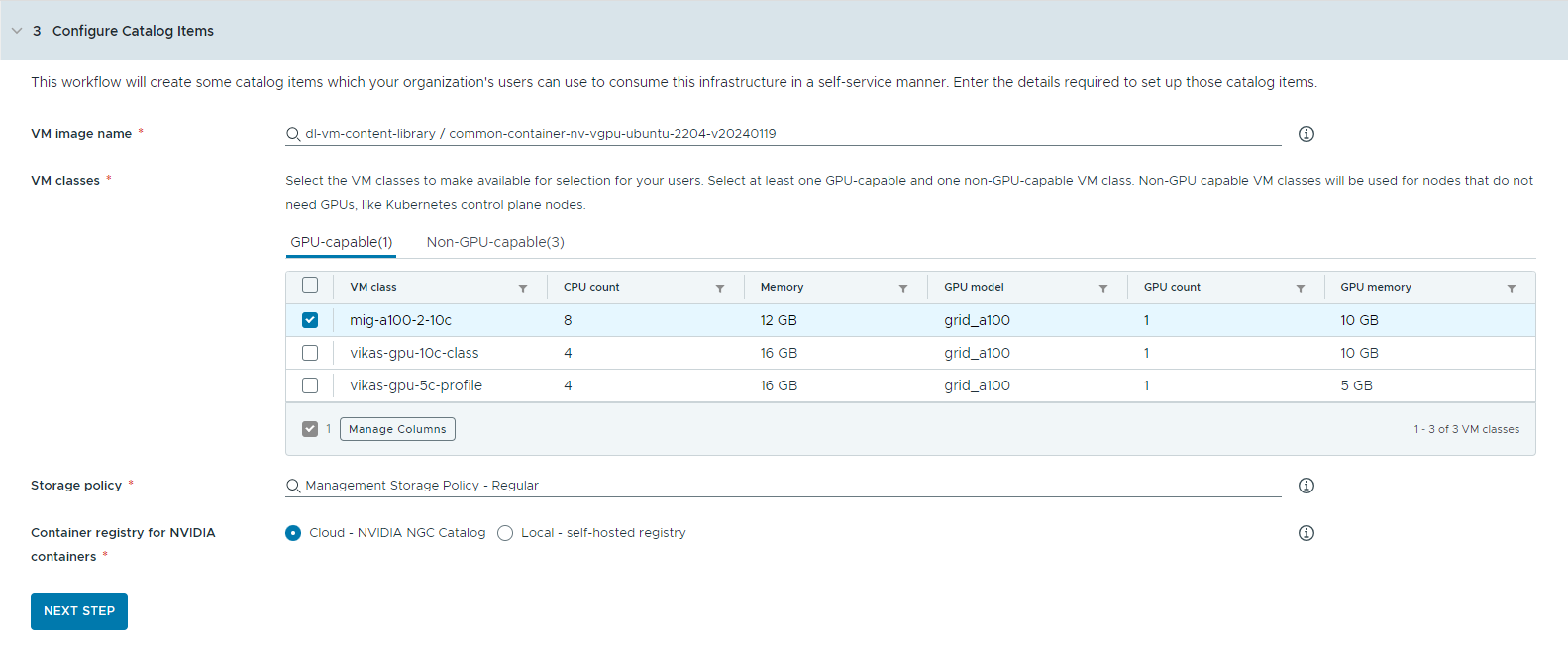
- Selezionare la libreria di contenuti che contiene l'immagine di Deep Learning VM.
È possibile accedere a una sola libreria di contenuti alla volta. Se la libreria di contenuti contiene immagini Kubernetes, tali immagini vengono escluse per semplificare la navigazione.
- Selezionare l'immagine della macchina virtuale che si desidera utilizzare per creare la macchina virtuale workstation.
- Selezionare la versione di Tanzu Kubernetes che si desidera utilizzare per le distribuzioni del cluster Kubernetes AI.
La versione di Tanzu Kubernetes (TKr) è la versione di runtime di Kubernetes che viene distribuita quando un utente richiede un cluster Kubernetes. È possibile selezionare una delle tre versioni più recenti di Tanzu Kubernetes supportate per VMware Private AI Foundation.
- Selezionare le classi di macchine virtuali che si desidera rendere disponibili per gli utenti del catalogo.
È necessario aggiungere almeno una classe compatibile con GPU e una classe non compatibile con GPU.
- Le classi di macchine virtuali abilitate per la GPU vengono utilizzate per Deep Learning VM e per i nodi worker del cluster TKG. Quando l'elemento del catalogo viene distribuito, il cluster TKG viene creato con le classi di macchine virtuali selezionate.
- Per eseguire i piani di controllo di Kubernetes, sono necessari nodi non compatibili con GPU.
- Le classi di macchine virtuali con Unified Virtual Memory (UVM) abilitata sono necessarie per eseguire workstation AI con Triton Inference Server.
- Selezionare un criterio di storage.
Il criterio di storage definisce il posizionamento dello storage e le risorse per le macchine virtuali.
Il criterio di storage definito per la macchina virtuale non è uguale al criterio di storage di VMware Data Services Manager.
- Specificare il registro del container in cui si desidera eseguire il pull delle risorse cloud della GPU di NVIDIA.
- Cloud: il pull delle immagini del container viene eseguito dal catalogo NGC NVIDIA.
- Locale: per gli ambienti air gap, il pull dei container viene eseguito da un registro privato.
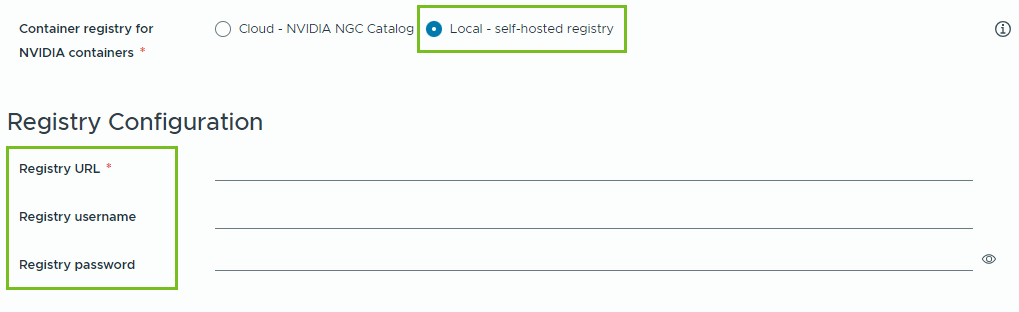
È necessario specificare la posizione del registro auto-ospitato. Se il registro richiede l'autenticazione, è necessario fornire anche le credenziali di accesso.
È possibile utilizzare Harbor come registro locale per le immagini dei container del catalogo NGC NVIDIA. Vedere Configurazione di un registro Harbor privato in VMware Private AI Foundation with NVIDIA.
- (Facoltativo) Configurare un server proxy.
Negli ambienti che non hanno accesso diretto a Internet, il server proxy viene utilizzato per scaricare il driver vGPU ed eseguire il pull dei container della workstation non RAG AI.
Nota: Il supporto per gli ambienti air gap è disponibile per gli elementi del catalogo della workstation AI e di Triton Inference Server. Gli elementi della workstation RAG AI e del cluster Kubernetes AI non supportano gli ambienti air gap e richiedono la connettività Internet. - Fare clic su Passaggio successivo.
- Selezionare la libreria di contenuti che contiene l'immagine di Deep Learning VM.
- Configurare l'accesso agli elementi del catalogo creando un progetto e assegnando gli utenti.
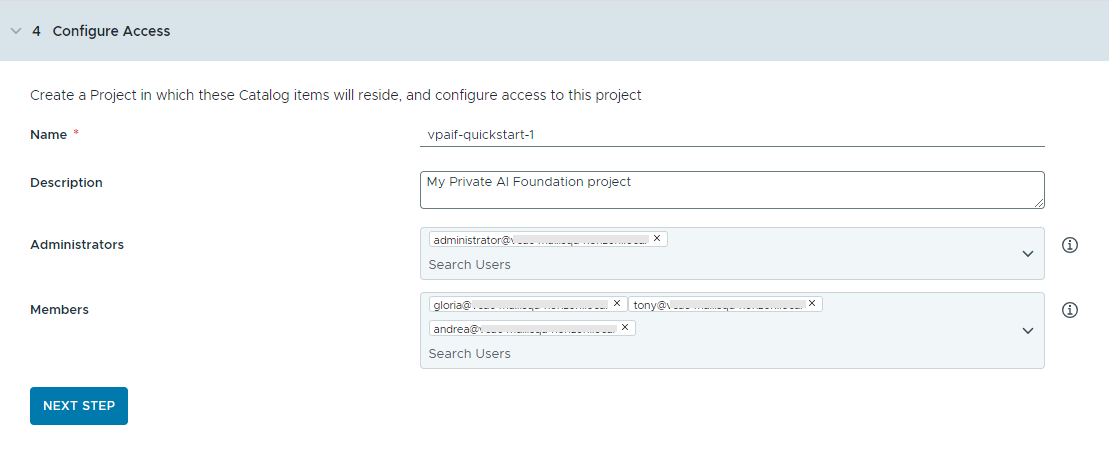
I progetti vengono utilizzati per gestire le persone, le risorse assegnate, i modelli cloud e le distribuzioni.
- Immettere un nome e una descrizione per il progetto.
Il nome del progetto può contenere solo caratteri alfanumerici minuscoli o trattini (-).
- Per rendere gli elementi del catalogo disponibili per gli altri utenti, aggiungere un Amministratore e Membri.
Gli amministratori hanno più autorizzazioni dei membri. Per ulteriori informazioni, vedere Quali sono i ruoli utente di VMware Aria Automation.
- Fare clic su Passaggio successivo.
- Immettere un nome e una descrizione per il progetto.
- Verificare la configurazione nella pagina Riepilogo.
Prima di eseguire la procedura guidata, è consigliabile salvare i dettagli della configurazione.
- Fare clic su Esegui avvio rapido.
Risultati
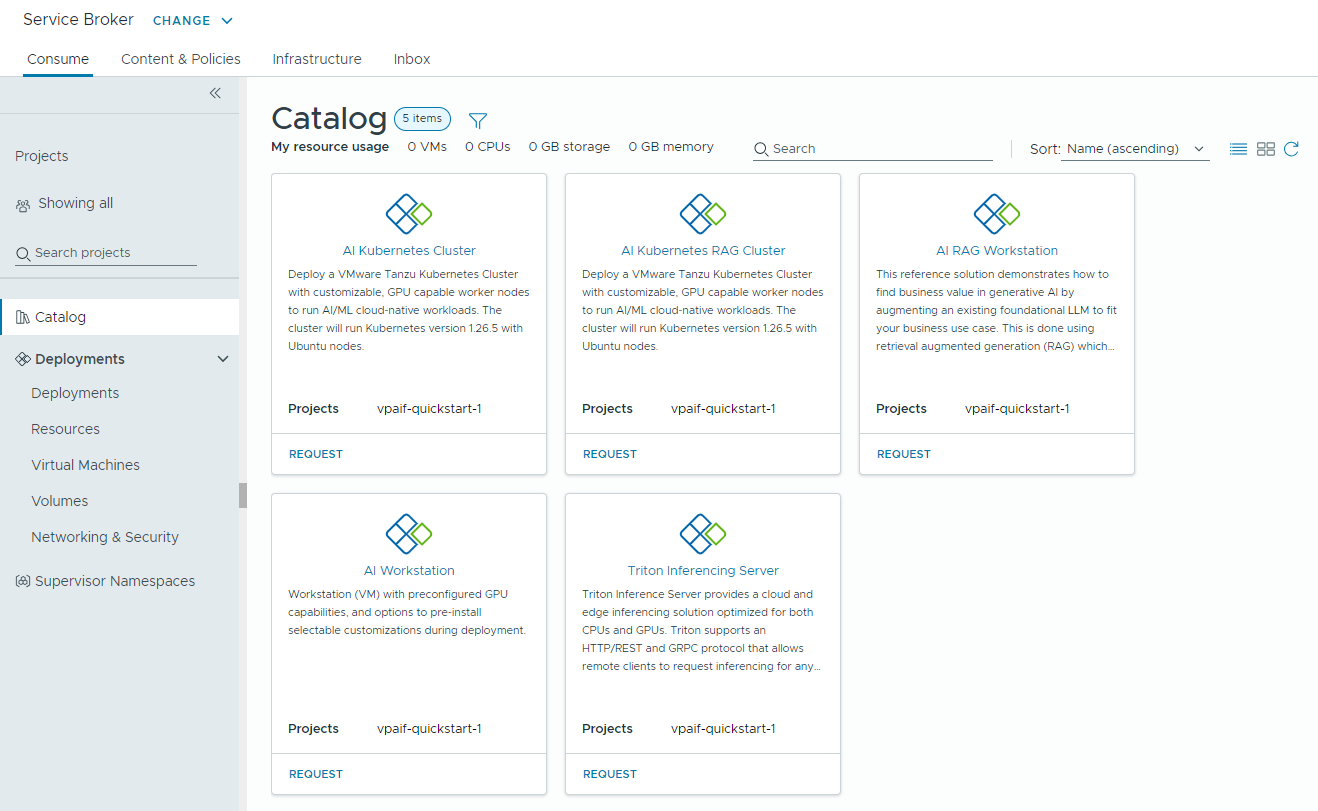
Nel catalogo di Automation Service Broker vengono creati i seguenti elementi del catalogo che gli utenti dell'organizzazione possono ora distribuire: Workstation AI, Workstation RAG AI, Workstation RAG AI con DSM, Database DSM, Triton Inferencing Server, Cluster Kubernetes AI, Cluster RAG Kubernetes AI e Cluster RAG Kubernetes AI con DSM.
Risoluzione dei problemi
- Se la configurazione guidata del catalogo non riesce, eseguirla di nuovo per un progetto diverso.
