









Per consentire agli sviluppatori di distribuire carichi di lavoro AI/ML in cluster TKG, l'amministratore di vSphere può configurare l'ambiente di Supervisore per supportare l'hardware NVIDIA GPU.
Passaggio 1 dell'amministratore: revisione dei requisiti di sistema
| Requisito | Descrizione |
|---|---|
| Infrastruttura vSphere 8 |
vCenter Server e host ESXi |
| Licenza per la gestione del carico di lavoro |
Spazi dei nomi di vSphere e Supervisore |
| OVA Ubuntu TKR | |
| Driver host NVIDIA vGPU |
Scaricare il VIB dal sito Web di NGC. Per ulteriori informazioni, consultare la documentazione relativa al driver software della vGPU. |
| License Server NVIDIA per vGPU |
Nome di dominio completo fornito dall'organizzazione |
Passaggio 2 dell'amministratore: installare il dispositivo GPU NVIDIA supportato negli host ESXi
Per distribuire carichi di lavoro IA/ML in TKG, installare uno o più dispositivi GPU NVIDIA supportati in ogni host ESXi che include il cluster vCenter in cui sarà abilitato Gestione carico di lavoro.
Per visualizzare i dispositivi GPU NVIDIA compatibili, fare riferimento alla guida alla compatibilità di VMware.

Il dispositivo GPU NVIDA deve supportare i profili vGPU NVIDIA AI Enterprise (NVAIE) più recenti. Per istruzioni, fare riferimento al documento NVIDIA Virtual GPU Software Supported GPUs.
Ad esempio, nel seguente host ESXi sono installati due dispositivi NVIDIA GPU A100.

Passaggio 3 dell'amministratore: configurare ciascun host ESXi per le operazioni vGPU
Per ogni host ESXi che include il cluster vCenter in cui è abilitata la funzionalità Gestione carico di lavoro, configurare l'host per NVIDIA vGPU abilitando Condiviso diretta e SR-IOV.
Abilitare Condiviso diretta su ciascun host ESXi
Per sbloccare la funzionalità NVIDIA vGPU, abilitare la modalità Condiviso diretta in ogni host ESXi che include il cluster vCenter in cui è abilitatoa la funzionalità Gestione carico di lavoro.
- Accedere a vCenter Server utilizzando vSphere Client.
- Selezionare un host ESXi nel cluster vCenter.
- Selezionare .
- Selezionare il dispositivo acceleratore GPU NVIDIA.
- Modificare le impostazioni dell dispositivo grafico.
- Selezionare Condiviso diretta.
- In Criterio di assegnazione GPU passthrough condiviso per ottenere prestazioni ottimali, selezionare macchine virtuali Distribuisci macchine virtuali tra le GPU.
- Fare clic su OK per salvare le configurazione.
- Si tenga presente che le impostazioni verranno applicate dopo il riavvio dell'host.
- Fare clic con il pulsante destro del mouse sull'host ESXi e passarlo in modalità di manutenzione.
- Riavviare l'host.
- Quando l'host è di nuovo in esecuzione, disattivare la modalità di manutenzione.
- Ripetere questo processo per ogni host ESXi nel cluster vSphere che supporta Gestione carico di lavoro.
Attivare il BIOS SR-IOV per i dispositivi NVIDIA GPU A30 e A100
Se si utilizza il dispositivo GPU NVIDIA A30 o A100, necessario per la GPU multi-istanza ( modalità MIG), è necessario abilitare SR-IOV nell'host ESXi. Se SR-IOV non è abilitato, non è possibile avviare le macchine virtuali dei nodi del cluster di Tanzu Kubernetes. Se si verifica questa condizione, viene visualizzato il seguente messaggio di errore nel riquadro Attività recenti di vCenter Server in cui è abilitato Gestione carico di lavoro.
Could not initialize plugin libnvidia-vgx.so for vGPU nvidia_aXXX-xx. Failed to start the virtual machine. Module DevicePowerOn power on failed.
Per abilitare SR-IOV, accedere all'host ESXi utilizzando la console Web. Selezionare . Selezionare il dispositivo GPU NVIDIA e fare clic su Configura SR-IOV. Da questa sezione è possibile attivare SR-IOV. Per ulteriori istruzioni, vedere la pagina Single Root I/O Virtualization (SR-IOV) nella documentazione di vSphere.
vGPU con Dynamic DirectPath IO (dispositivo abilitato per passthrough)
- Accedere a vCenter Server utilizzando vSphere Client.
- Selezionare l'host ESXi di destinazione nel cluster vCenter.
- Selezionare .
- Selezionare la scheda Tutti i dispositivi PCI.
- Selezionare il dispositivo acceleratore GPU NVIDIA di destinazione.
- Fare clic su Attiva/disattiva passthrough.
- Fare clic con il pulsante destro del mouse sull'host ESXi e passarlo in modalità di manutenzione.
- Riavviare l'host.
- Quando l'host è di nuovo in esecuzione, disattivare la modalità di manutenzione.
Passaggio 4 dell'amministratore: installare il driver NVIDIA Host Manager su ciascun host ESXi
Per eseguire macchine virtuali dei nodi del cluster di Tanzu Kubernetes con accelerazione grafica della NVIDIA vGPU, installare il driver NVIDIA Host Manager su ciascun host ESXi, incluso il cluster vCenter in cui sarà abilitato Gestione carico di lavoro.
I componenti del driver NVIDIA vGPU Host Manager sono incorporati in un pacchetto bundle di installazione per vSphere (VIB). Il VIB NVAIE viene fornito dall'organizzazione tramite il programma di licenza NVIDIA GRID. VMware non fornisce VIB NVAIE né li rende disponibili per il download. Come parte del programma di gestione delle licenze NVIDIA, l'organizzazione configura un server di gestione delle licenze. Per ulteriori informazioni, fare riferimento alla guida rapida del software Virtual GPU di NVIDIA.
esxcli system maintenanceMode set --enable true esxcli software vib install -v ftp://server.domain.example.com/nvidia/signed/NVIDIA_bootbank_NVIDIA-VMware_ESXi_7.0_Host_Driver_460.73.02-1OEM.700.0.0.15525992.vib esxcli system maintenanceMode set --enable false /etc/init.d/xorg restart
Passaggio 5 dell'amministratore: verificare che gli host ESXi siano pronti per le operazioni di NVIDIA vGPU
- Accedere tramite SSH all'host ESXi, accedere alla modalità shell ed eseguire il comando
nvidia-smi. NVIDIA System Management Interface è un'utilità da riga di comando fornita da NVIDA vGPU Host Manager. L'esecuzione di questo comando restituisce le GPU e i driver nell'host. - Eseguire il comando seguente per verificare che il driver NVIDIA sia installato correttamente:
esxcli software vib list | grep NVIDA. - Verificare che l'host sia configurato con la GPU condivisa diretta e che SR-IOV sia attivato (se si utilizzano dispositivi NVIDIA A30 o A100).
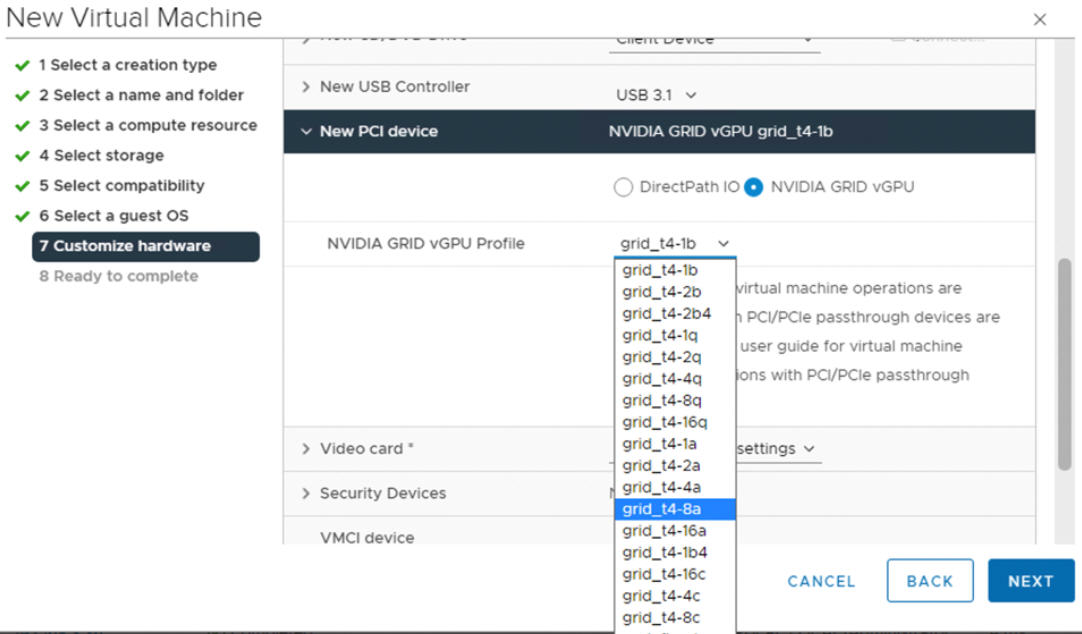
- Utilizzando vSphere Client, nell'host ESXi configurato per la GPU, creare una nuova macchina virtuale con un dispositivo PCI incluso. Il profilo NVIDIA vGPU deve essere visualizzato e selezionabile.
Passaggio 6 dell'amministratore: abilitare la gestione del carico di lavoro
Passaggio 7 dell'amministratore: creare o aggiornare una libreria di contenuti con un Ubuntu di TKR
NVIDIA vGPU richiede il sistema operativo Ubuntu. Non è possibile utilizzare l'edizione PhotonOS di una versione di Tanzu Kubernetes per i cluster vGPU.
VMware fornisce un'edizione Ubuntu delle versioni di Tanzu Kubernetes. A partire da vSphere 8, l'edizione di Ubuntu viene specificata utilizzando un'annotazione nel codice YAML del cluster.
Passaggio 8 dell'amministratore: creare una classe di macchine virtuali personalizzata con il profilo vGPU
Creare una classe di macchine virtuali personalizzata con un profilo vGPU. Questa classe di macchine virtuali verrà quindi utilizzata nella specifica del cluster per creare i nodi del cluster TKGS. Fare riferimento alle istruzioni seguenti: Creazione di una classe di macchine virtuali personalizzata per i dispositivi NVIDIA vGPU.
Passaggio 9 dell'amministratore: configurare Spazio dei nomi vSphere
Creare un Spazio dei nomi vSphere per ogni cluster vGPU TKG di cui si intende eseguire il provisioning. Vedere Creazione di uno Spazio dei nomi vSphere per ospitare i cluster Servizio TKG.
Configurare il Spazio dei nomi vSphere aggiungendo un utente/gruppi SSO vSphere con autorizzazioni Modifica e collegare un criterio di storage per i volumi persistenti. Vedere Configurazione di uno Spazio dei nomi vSphere per i cluster Servizio TKG.
Associare la libreria di contenuti TKR in cui è archiviata l'immagine Ubuntu desiderata a Spazio dei nomi vSphere. Vedere Associazione della libreria di contenuti TKR allo Servizio TKG.
- In Seleziona Spazio dei nomi vSphere, selezionare il riquadro Servizio macchina virtuale e fare clic su Gestisci classi di macchine virtuali.
- Individuare nell'elenco delle classi la classe di macchine virtuali personalizzata creata.
- Selezionare la classe e fare clic su Aggiungi.
Passaggio 10 dell'amministratore: verificare che Supervisore sia pronto
L'ultima attività dell'amministrazione consiste nel verificare che Supervisore sia stato sottoposto a provisioning e che possa essere utilizzato dall'operatore del cluster per il provisioning di un cluster TKG per i carichi di lavoro AI/ML.
Vedere Connessione ai cluster Servizio TKG tramite l'autenticazione SSO di vCenter.
