









特殊なハードウェアへのワークロード クラスタの展開
Tanzu Kubernetes Grid は、vSphere 7.0 以降の特定のタイプの GPU 対応ホストへのワークロード クラスタの展開をサポートします。
GPU 対応ワークロード クラスタの展開
vSphere ワークロード クラスタで、GPU を備えたノードを使用するには、PCI パススルー モードを有効にする必要があります。この操作を行うと、クラスタが ESXi ハイパーバイザーをバイパスして GPU に直接アクセスできるようになるため、ネイティブ システム上の GPU のパフォーマンスと同様なレベルのパフォーマンスを実現できます。PCI パススルー モードを使用している場合、各 GPU デバイスは vSphere ワークロード クラスタの仮想マシン (VM) の専用デバイスになります。
注GPU 対応ノードを既存のクラスタに追加するには、
tanzu cluster node-pool setコマンドを使用します。
前提条件
- NVIDIA V100 または NVIDIA Tesla T4 GPU カードを搭載した ESXi ホスト。
- vSphere 7.0 Update 3 以降。以下に、これをサポートするために最低限必要な 7.0u3 のビルドを示します。
- Tanzu Kubernetes Grid v1.6 以降。
- Helm(Kubernetes パッケージ マネージャ)。インストールする方法については、Helm ドキュメントの「Helm のインストール」を参照してください。
手順
GPU 対応ホストのワークロード クラスタを作成するには、次の手順に従って PCI パススルーを有効にし、カスタム マシン イメージをビルドし、クラスタ構成ファイルと Tanzu Kubernetes リリースを作成し、ワークロード クラスタを展開し、Helm を使用して GPU Operator をインストールします。
-
GPU カードを使用する ESXi ホストを vSphere Client に追加します。
-
PCI パススルーを有効にし、GPU ID を次のように記録します。
- vSphere Client で、
GPUクラスタ内のターゲット ESXi ホストを選択します。 - [構成 (Configure)] > [ハードウェア (Hardware)] > [PCI デバイス (PCI Devices)] の順に選択します。
- [すべての PCI デバイス (All PCI Devices)] タブを選択します。
- リストからターゲット GPU を選択します。
- [パススルーの切り替え (Toggle Passthrough)] をクリックします。
- [一般情報 (General Information)] で、デバイス ID とベンダー ID を記録します(下の図では緑色で強調表示されています)。これらの ID は、同一の GPU カードでは同じです。これらは、クラスタ構成ファイルで必要になります。
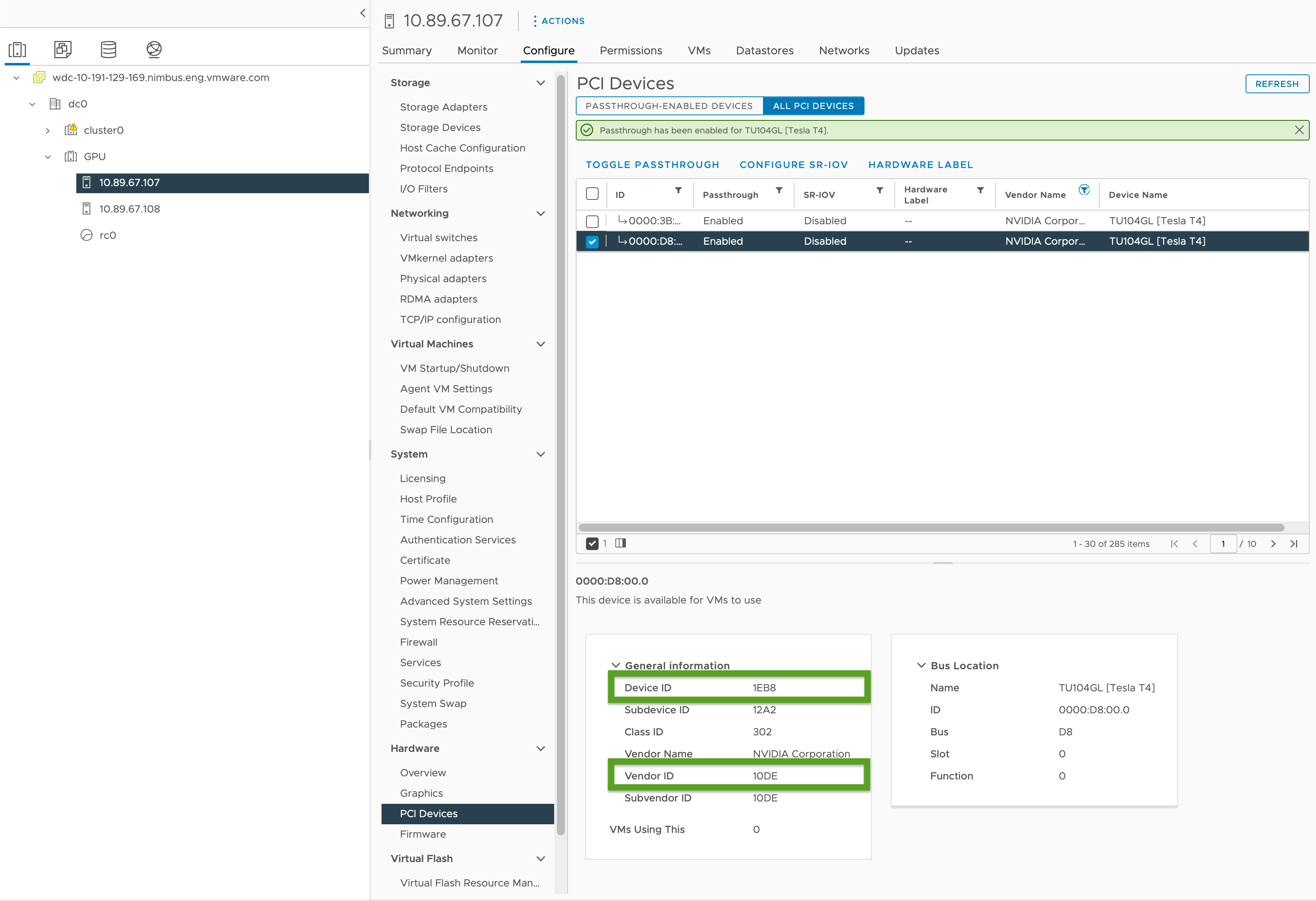
- vSphere Client で、
-
「ワークロード クラスタ テンプレート」のテンプレートを使用してワークロード クラスタ構成ファイルを作成し、次の変数を含めます。
... VSPHERE_WORKER_PCI_DEVICES: "0x<VENDOR-ID>:0x<DEVICE-ID>" VSPHERE_WORKER_CUSTOM_VMX_KEYS: 'pciPassthru.allowP2P=true,pciPassthru.RelaxACSforP2P=true,pciPassthru.use64bitMMIO=true,pciPassthru.64bitMMIOSizeGB=<GPU-SIZE>' VSPHERE_IGNORE_PCI_DEVICES_ALLOW_LIST: "<BOOLEAN>" VSPHERE_WORKER_HARDWARE_VERSION: vmx-17 WORKER_ROLLOUT_STRATEGY: "RollingUpdate"ここで、
<VENDOR-ID>と<DEVICE-ID>は前の手順で記録したベンダー ID とデバイス ID です。たとえば、ベンダー ID が10DEで、デバイス ID が1EB8の場合、値は"0x10DE:0x1EB8"です。<GPU-SIZE>は、クラスタ内のすべての GPU のフレームバッファ メモリの合計 GB で、その次に大きい 2 の累乗数に切り上げられます。- たとえば、40 GB の GPU が 2 つある場合、合計は 80 GB で、128 GB に切り上げられます。そのため、値を
pciPassthru.64bitMMIOSizeGB=128に設定します。 - GPU カードに必要なメモリを確認するには、特定の NVIDIA GPU カードのドキュメントを参照してください。NVIDIA ドキュメントにある「Requirements for Using vGPU on GPUs Requiring 64 GB or More of MMIO Space with Large-Memory VMs」の表を参照してください。
- 以下も参照してください。
- たとえば、40 GB の GPU が 2 つある場合、合計は 80 GB で、128 GB に切り上げられます。そのため、値を
- NVIDIA Tesla T4 GPU を使用している場合は
<BOOLEAN>がfalse、NVIDIA V100 GPU を使用している場合はtrueです。 <VSPHERE_WORKER_HARDWARE_VERSION>は、仮想マシンのハードウェア バージョンで、このバージョンに仮想マシンをアップグレードします。GPU ノードに必要な最小バージョンは 17 です。- アップグレード中にワーカー ノードで使用できる追加の PCI デバイスがある場合、
WORKER_ROLLOUT_STRATEGYはRollingUpdateです。それ以外の場合は、OnDeleteを使用します。
注
仮想マシンごとに使用できる GPU は 1 種類だけです。たとえば、NVIDIA V100 と NVIDIA Tesla T4 の両方を単一の仮想マシンで使用することはできませんが、ベンダー ID とデバイス ID が同じ、複数の GPU インスタンスを使用することはできます。
tanzuCLI では、MachineDeploymentのWORKER_ROLLOUT_STRATEGY仕様を更新できません。PCI デバイスが使用できないためにクラスタのアップグレードが停止した場合、VMware はkubectlCLI を使用してMachineDeployment戦略を編集することを推奨します。ロールアウト戦略は、spec.strategy.typeで定義されます。GPU 対応クラスタに対して構成可能な変数の完全なリストについては、「構成ファイル変数リファレンス」の「GPU 対応クラスタ」を参照してください。
-
次のコマンドを実行して、ワークロード クラスタを作成します。
tanzu cluster create -f CLUSTER-CONFIG-NAMEここで、
CLUSTER-CONFIG-NAMEは、前の手順で作成したクラスタ構成ファイルの名前です。 -
NVIDIA Helm リポジトリを追加します。
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia \ && helm repo update -
NVIDIA GPU Operator をインストールします。
helm install --kubeconfig=./KUBECONFIG --wait --generate-name -n gpu-operator --create-namespace nvidia/gpu-operatorここで、
KUBECONFIGはワークロード クラスタのkubeconfigの名前と場所です。詳細については、「ワークロード クラスタkubeconfigの取得」を参照してください。このコマンドのパラメータの詳細については、NVIDIA ドキュメントの「GPU Operator のインストール」を参照してください。
-
NVIDIA GPU Operator が実行されていることを確認します。
kubectl --kubeconfig=./KUBECONFIG get pods -A出力は次のようになります。
NAMESPACE NAME READY STATUS RESTARTS AGE gpu-operator gpu-feature-discovery-szzkr 1/1 Running 0 6m18s gpu-operator gpu-operator-1676396573-node-feature-discovery-master-7795vgdnd 1/1 Running 0 7m7s gpu-operator gpu-operator-1676396573-node-feature-discovery-worker-bq6ct 1/1 Running 0 7m7s gpu-operator gpu-operator-84dfbbfd8-jd98f 1/1 Running 0 7m7s gpu-operator nvidia-container-toolkit-daemonset-6zncv 1/1 Running 0 6m18s gpu-operator nvidia-cuda-validator-2rz4m 0/1 Completed 0 98s gpu-operator nvidia-dcgm-exporter-vgw7p 1/1 Running 0 6m18s gpu-operator nvidia-device-plugin-daemonset-mln6z 1/1 Running 0 6m18s gpu-operator nvidia-device-plugin-validator-sczdk 0/1 Completed 0 22s gpu-operator nvidia-driver-daemonset-b7flb 1/1 Running 0 6m38s gpu-operator nvidia-operator-validator-2v8zk 1/1 Running 0 6m18s
GPU クラスタのテスト
GPU 対応クラスタをテストするには、Kubernetes ドキュメントにある cuda-vector-add の例のポッド マニフェストを作成して展開します。コンテナはダウンロード、実行、および GPU を使用した CUDA 計算を行います。
-
cuda-vector-add.yamlという名前のファイルを作成し、次の内容を追加します。apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add # https://github.com/kubernetes/kubernetes/blob/v1.7.11/test/images/nvidia-cuda/Dockerfile image: "registry.k8s.io/cuda-vector-add:v0.1" resources: limits: nvidia.com/gpu: 1 # requesting 1 GPU -
ファイルを適用します。
kubectl apply -f cuda-vector-add.yaml -
次を実行します。
kubectl get po cuda-vector-add出力は次のようになります。
cuda-vector-add 0/1 Completed 0 91s -
次を実行します。
kubectl logs cuda-vector-add出力は次のようになります。
[Vector addition of 50000 elements] Copy input data from the host memory to the CUDA device CUDA kernel launch with 196 blocks of 256 threads Copy output data from the CUDA device to the host memory Test PASSED Done
Edge サイトへのワークロード クラスタの展開
Tanzu Kubernetes Grid v1.6 以降では、Edge VMware ESXi ホストへのワークロード クラスタの展開がサポートされています。この方法を使用すると、異なる場所で多くの Kubernetes クラスタを実行し、中央管理クラスタによってすべて管理することができます。
トポロジ:単一の制御プレーン ノードと 1 台または 2 台のホストのみで、本番環境での Edge ワークロード クラスタを実行できます。ただし、この場合は使用する CPU、メモリ、およびネットワーク帯域幅が少なくなりますが、標準的な本番 Tanzu Kubernetes Grid クラスタと同じ回復性とリカバリ特性はありません。詳細については、「VMware Tanzu Edge ソリューション リファレンス アーキテクチャ 1.0」を参照してください。
ローカル レジストリ:通信遅延を最小限に抑え、回復性を最大化するには、各 Edge クラスタに独自のローカル Harbor コンテナ レジストリが必要です。このアーキテクチャの概要については、「アーキテクチャの概要」の「コンテナ レジストリ」を参照してください。ローカル Harbor レジストリをインストールするには、「vSphere でのオフライン Harbor レジストリの展開」を参照してください。
タイムアウト:また、Edge ワークロード クラスタの管理クラスタが、リモートでメイン データセンター内にある場合は、その管理クラスタがワークロード クラスタ マシンと接続するための時間を十分に確保するために、特定のタイムアウトの調整が必要になる可能性があります。これらのタイムアウトを調整するには、下記の「Edge クラスタのより大きい遅延を処理するためのタイムアウト延長」を参照してください。
ローカル仮想マシン テンプレートの指定
Edge ワークロード クラスタが共有 vCenter Server ストレージではなく、独自の隔離されたストレージを使用する場合は、ローカル ストレージからノード仮想マシン テンプレート イメージを OVA ファイルとして取得するように構成する必要があります。
注
tanzu cluster upgradeを使用して、ローカル仮想マシン テンプレートを使用する Edge ワークロード クラスタの Kubernetes バージョンをアップグレードすることはできません。代わりに、「ワークロード クラスタのアップグレード」トピックの「ローカル仮想マシン テンプレートを使用した Edge クラスタのアップグレード」に従ってクラスタをアップグレードします。
クラスタに単一の仮想マシン テンプレートを指定するか、ワーカーおよび制御プレーン マシンの展開に固有の異なるテンプレートを指定するには、次の手順を実行します。
-
クラスタ構成ファイルを作成し、「クラスベースのクラスタを作成する」で説明されている 2 段階のプロセスの手順 1 としてクラスタ マニフェストを生成します。
-
クラスタの仮想マシン テンプレートについて、以下を確認します。
- TKG の有効な Kubernetes バージョンを持っていること。
- TKr の
spec.osImagesプロパティと一致する有効な OVA バージョンを持っていること。 - ローカル vCenter Server にアップロードされ、
/dc0/vm/ubuntu-2004-kube-v1.27.5+vmware.1-tkg.1などの有効なインベントリ パスを持っていること。
-
クラスタ全体の仮想マシン テンプレートと複数の仮想マシン テンプレートのどちらを定義しているかに応じて、マニフェストの
Clusterオブジェクト仕様を次のように編集します。-
クラスタ全体の仮想マシン テンプレート:
annotationsで、run.tanzu.vmware.com/resolve-vsphere-template-from-pathを空の文字列に設定します。spec.topology.variablesのvcenterブロックで、templateを仮想マシン テンプレートのインベントリ パスに設定します。-
例:
annotations: run.tanzu.vmware.com/resolve-vsphere-template-from-path: "" ... spec: topology: class: tkg-vsphere-default-v1.0.0 variables: - name: vcenter value: cloneMode: fullClone datacenter: /dc0 datastore: /dc0/datastore/sharedVmfs-0 folder: /dc0/vm/folder0 network: /dc0/network/VM Network resourcePool: /dc0/host/cluster0/Resources/rp0 ... template: VM-TEMPLATE ...ここで、
VM-TEMPLATEはクラスタの仮想マシン テンプレートへのパスです。
-
machineDeploymentごとの複数の仮想マシン テンプレート:annotationsで、run.tanzu.vmware.com/resolve-vsphere-template-from-pathを空の文字列に設定します。spec.topology.workerおよびcontrolplaneの各machineDeploymentsブロックのvariables.overridesで、templateを仮想マシン テンプレートのインベントリ パスに設定するvcenterの行を追加します。-
例:
annotations: run.tanzu.vmware.com/resolve-vsphere-template-from-path: "" ... spec: workers: machineDeployments: - class: tkg-worker metadata: annotations: run.tanzu.vmware.com/resolve-os-image: image-type=ova,os-name=ubuntu name: md-1 replicas: 2 variables: overrides: - name: vcenter value: ... datacenter: /dco template: VM-TEMPLATE ...ここで、
VM-TEMPLATEは、machineDeploymentの仮想マシン テンプレートへのパスです。
-
-
変更した構成ファイルを使用して、「クラスベースのクラスタを作成する」で説明されているプロセスの手順 2 としてクラスタを作成します。
Edge クラスタのより大きい遅延を処理するためのタイムアウト延長
管理クラスタが Edge サイトで実行されているワークロード クラスタをリモートで管理している場合、または 20 個を超えるワークロード クラスタを管理している場合は、一時的にオフラインになっているマシンやリモート管理クラスタとの通信に 12 分以上かかる可能性のあるマシンがクラスタ API によってブロックまたは削除されないように特定のタイムアウト調整を行うことができます。これは特に、インフラストラクチャがアンダープロビジョニング状態である場合に該当します。
Edge クラスタが制御プレーンと通信する時間を増やすために、次の 3 つの設定を調整できます。
-
MHC_FALSE_STATUS_TIMEOUT:たとえば、デフォルトの12mを40mに延長して、MachineHealthCheckコントローラが、マシンのReady条件が 12 分以上Falseのままであってもマシンを再作成しないようにします。マシン健全性チェックの詳細については、「Tanzu Kubernetes クラスタのマシン健全性チェックの構成」を参照してください。 -
NODE_STARTUP_TIMEOUT:たとえば、デフォルトの20mを60mに延長して、MachineHealthCheckコントローラが、起動に 20 分以上かかっている新しいマシンを健全でないと見なし、そのマシンのクラスタへの参加をブロックしてしまうことを防ぎます。 -
etcd-dial-timeout-duration:たとえばcapi-kubeadm-control-plane-controller-managerマニフェストでデフォルトの10mを40sに延長して、ワークロード クラスタのetcdの健全性をスキャンしている間に管理クラスタ上のetcdクライアントが途中で失敗するのを防ぎます。管理クラスタは、etcdとの接続機能をマシンの健全性の基準として使用します。例:-
ターミナルで、以下を実行します。
kubectl edit capi-kubeadm-control-plane-controller-manager -n capi-system -
--etcd-dial-timeout-durationの値を変更します。- args: - --leader-elect - --metrics-bind-addr=localhost:8080 - --feature-gates=ClusterTopology=false - --etcd-dial-timeout-duration=40s command: - /manager image: projects.registry.vmware.com/tkg/cluster-api/kubeadm-control-plane-controller:v1.0.1_vmware.1
-
さらに、次の点に注意します。
-
capi-kubedm-control-plane-manager : ワークロード クラスタから何らかの理由で「分割」された場合は、ワークロード クラスタ内の
etcdを適切に監視できるように、新しいノードにバウンスする必要がある場合があります。 -
TKG の Pinniped 構成はすべて、ワークロード クラスタが管理クラスタに接続されていることを前提としています。切断された場合は、ワークロード ポッドが管理アカウントまたはサービス アカウントを使用して Edge サイトの API サーバと通信していることを確認する必要があります。そうしないと、管理クラスタから切断されたことにより、Edge サイトがローカル ワークロード API サーバに対して Pinniped 経由で認証されなくなります。
