









パフォーマンスとは、ワークロードに必要なリソースを確保することです。主要なパフォーマンス インジケータ (KPI) を使用して、ワークロードに関連するパフォーマンスの問題を特定できます。これらの KPI を使用して、サービス階層に関連付けられている SLA を定義します。これらのダッシュボードは KPI を使用して、コンシューマ レイヤーのワークロードのパフォーマンスと、プロバイダ レイヤーで集計されたワークロードのパフォーマンスを表示します。
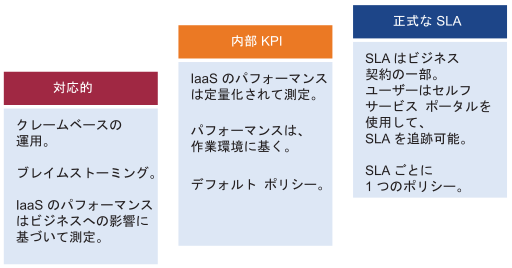
SLA は、お客様との正式なビジネス契約です。通常、SLA(サービス レベル アグリーメント)は、IaaS プロバイダ(インフラストラクチャ チーム)と IaaS ユーザー(アプリケーション チームまたはビジネス部門)の間の契約です。正式な SLA には、運用上の大きな変更が必要です。たとえば、技術的な変更だけでなく、契約、価格(コストではなく)、プロセス、人材の確認が必要になる場合があります。KPI は、SLA メトリックおよび早期警告を提供するその他のメトリックをカバーします。SLA がない場合は、内部 KPI から開始します。IaaS の実際のパフォーマンスを理解し、プロファイルを作成する必要があります。独自のしきい値が設定されていない場合は、vRealize Operations のデフォルトの設定を使用します。これらのしきい値は、プロアクティブな運用に対応するために選択されているからです。
パフォーマンス管理の 3 つのプロセス
- 計画。パフォーマンスの目標を設定します。vSAN を設計するときは、必要なディスク遅延(ミリ秒)を把握しておく必要があります。仮想マシン レベルで測定された 10 ミリ秒(vSAN レベルではない)は、良好な最初の数値です。
- 監視。計画を実際のデータと比較します。アーキテクチャが提供する予定であったものと、実際のデータが一致しているでしょうか。一致していない場合は修正する必要があります。
- トラブルシューティング。現実が計画に従っていない場合は、問題や苦情の発生を待たずにプロアクティブに修正する必要があります。
- 競合:これが主なインジケータです。
- 構成:バージョンの非互換を確認します。
- 可用性:ソフト エラーを確認します。vMotion の短時間ダウンタイム、ロックアップ。これには Log Insight が必要です。
- 使用率:最後にこれを確認します。最初の 3 つのパラメータに問題がない場合、これは省略できます。
パフォーマンス管理の 3 つのレイヤー
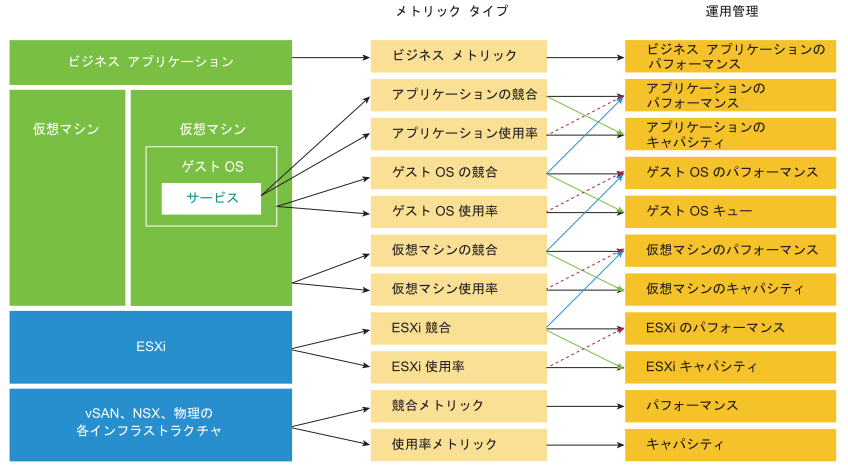
エンタープライズ アプリケーションには、主に 3 つの領域があります。これらの領域にはそれぞれ独自のチームのセットがあります。各チームには独自の責任のセットがあり、関連するスキル セットが必要です。3 つの領域は、ビジネス、アプリケーション、IaaS で構成されます。次の図を参照して、3 つのレイヤーと各レイヤーでの疑問の例を確認してください。
パフォーマンス管理の大半は排除の実践です。手法としては、各レイヤーをスライスし、そのレイヤーがパフォーマンスの問題を引き起こしているかどうかを判断します。したがって、特定のレイヤーが良好な状態かどうかを示すメトリックを 1 つのみ設定することが不可欠です。このプライマリ メトリックは、主要パフォーマンス インジケータ (KPI) という名称です。
上位のレイヤーは、その下位のレイヤーに依存するため、インフラストラクチャ レイヤーは通常競合の原因となります。そのため、最初は一番下のレイヤーに注目します。これは、その上のレイヤーの基盤として機能しているためです。このレイヤーは通常、水平方向の基盤レイヤーであるため、実行されているビジネス アプリケーションの種類とは関係なく、一般的なインフラストラクチャ サービスのセットを提供しています。
パフォーマンス管理の 2 つのメトリック
パフォーマンスを把握する主要な手段は競合です。多くの人は使用率に注目しますが、それは使用率が高いと何かが発生するのではないかと懸念するためです。その何かが競合です。競合は、キュー、遅延、ドロップ、キャンセル、コンテキスト スイッチなど、さまざまな形式で発生します。
ただし、非常に高い使用率のインジケータとパフォーマンスの問題を混同しないようにしてください。ESXi ホストでバルーニング、圧縮、およびスワップが発生しても、仮想マシンにパフォーマンスの問題が発生していることを意味するわけではありません。ホストのパフォーマンスは、仮想マシンに対してどの程度のリソースを提供できるかによって測定できます。パフォーマンスは ESXi ホストの使用率に関連していますが、パフォーマンス メトリックは使用率に基づいているのではなく、競合のメトリックに基づいています。
| インフラストラクチャの競合 | 仮想マシンとゲスト OS の構成 |
|---|---|
ESXi 設定
|
仮想マシン:制限、共有、予約
|
ネットワーク
|
サイズ:NUMA 効果。NUMA ノードにまたがる仮想マシン。 |
クラスタ設定
|
スナップショット。I/O は 2 倍速で処理されます。 仮想マシンのドライバ。 |
vSAN
|
Windows または Linux プロセスのやり取り、プロセスの増大、OS レベルのキュー。 |
パフォーマンス管理の観点から見ると、vSphere クラスタは、リソースの最小論理構成要素となります。リソース プールと仮想マシン ホスト間のアフィニティは、より小さなスライスを提供できますが、運用上複雑なため IaaS サービスの確実な品質をもたらすことはできません。リソース プールでは、サービス クラスをはっきりと区別して提供できません。たとえば、ゴールドの料金はシルバーの 2 倍なので、2 倍の速度が提供されると SLA で規定しているとします。この場合、リソース プールでゴールドに 2 倍のシェアを割り当てる事ができます。ただし、シェアの割り当てを増やせば、CPU 準備中の時間を半分にできるかどうかを前もって判断することはできません。
仮想マシンのパフォーマンス

KPI カウンタは一部のユーザーにとって技術的であるため、vRealize Operations には最初に使用する開始ラインが含まれています。環境のプロファイルを作成した後に、しきい値を調整できます。ほとんどのユーザーにはベースラインがないため、このプロファイルを使用することが推奨されます。プロファイルの作成には Advanced エディションが必要です。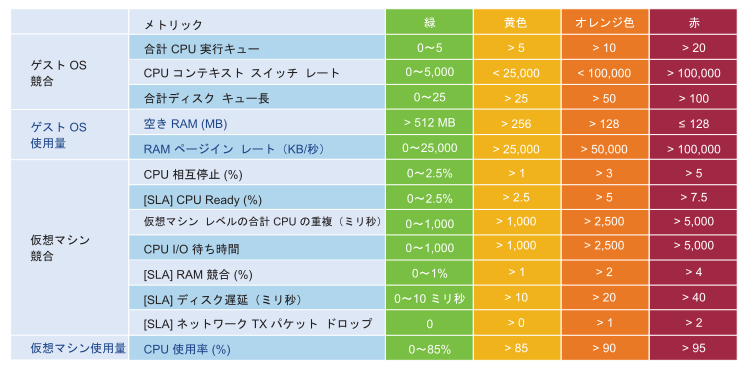
パフォーマンス メトリック
| IaaS | 仮想マシン カウンタ | しきい値 |
|---|---|---|
| CPU | Ready | 2.5% |
| RAM | 競合 | 1% |
| ディスク | 待ち時間 | 10 ミリ秒 |
| ネットワーク | TX ドロップ パケット | 0 |
この表は、厳しいしきい値の例です。パフォーマンスの標準は、インフラストラクチャ チームが使用するための内部 KPI であるため、高く設定されています。これは、ユーザーとの間で確認される外部向けの正式な SLA ではありません。オペレーション チームが早めに警告を受け取って、外部 SLA への違反が発生する前に対処するための時間を確保できるように、内部 KPI と外部 SLA の間にはバッファが必要です。また、高く設定した標準は、ミッション クリティカルという観点から開発環境にとっても有用です。標準が最小限のパフォーマンスの環境に設定されていると、その環境を重要度の高い開発環境に適用することはできません。
運用を簡素化するために、1 つのしきい値のみを使用します。これには、本番環境のパフォーマンスが開発環境よりも高いスコアになるという前提があります。開発環境のパフォーマンスは本番環境よりも低いと想定されていますが、それ以外はすべて同じです。1 つのしきい値のみを使用すると、提供されるサービス品質 (QoS) がサービス クラスの違いによって異なることを説明しやすくなります。たとえば、コストを削減するとパフォーマンスが低下します。支払う価格が半分ならばパフォーマンスも半分になると考えることができます。
表に記載されている IaaS の 4 つの要素(CPU、RAM、ディスク、ネットワーク)は、収集サイクルごとに評価されます。収集時間は、監視のために適切なバランスがとれている値である 5 分に設定されます。SLA の基準を 1 分にすると、値が小さすぎるためにコストの増加か、しきい値の低下のいずれかが発生します。
設計上の考慮事項
すべてのパフォーマンス ダッシュボードは、同じ設計原則を共有しています。これらのダッシュボードが同じ目的を持っていることを考慮し、各ダッシュボードの表示が互いに異なっていると混乱が発生するため、これらは意図的に類似するように設計されています。
ダッシュボードは、サマリと詳細の 2 つのセクションで構成されています。
- サマリ セクションは、通常、全体像を把握するためにダッシュボードの上部に配置されます。
- 詳細セクションはサマリ セクションの下に配置されます。ここから特定のオブジェクトにドリルダウンすることができます。たとえば、特定の仮想マシンの詳細パフォーマンス レポートを取得できます。
詳細セクションで、クイック コンテキスト スイッチを使用して、パフォーマンスのトラブルシューティング中に複数のオブジェクトのパフォーマンスを確認します。たとえば、仮想マシンのパフォーマンスを確認する場合は、画面を変更することなく、仮想マシン固有の情報と KPI を表示できます。1 つの仮想マシンから別の仮想マシンに移動して、複数のウィンドウを開かずに詳細を表示することができます。
このダッシュボードでは、段階的開示を使用して、情報の過剰なロードを最小限に抑え、Web ページが迅速にロードされるようにします。また、ブラウザ セッションが維持されている場合は、最後の選択内容がインターフェイスに記憶されます。
これらの操作の中枢には共通性があるため、パフォーマンスと容量のダッシュボードの多くは同様のレイアウトとなっています。
