









要使开发人员能够在 TKGS 集群上部署 AI/ML 工作负载,vSphere 管理员应设置 vSphere with Tanzu 环境以支持 NVIDIA GPU 硬件。
在 TKGS 集群上部署 AI/ML 工作负载的 vSphere 管理员工作流
| 步骤 | 操作 | 链接 |
|---|---|---|
| 0 | 查看系统要求。 |
请参见管理员步骤 0:查看系统要求。 |
| 1 | 在 ESXi 主机上安装受支持的 NVIDIA GPU 设备。 |
|
| 2 | 设置适用于 vGPU 操作的 ESXi 设备图形设置。 |
|
| 3 | 在每个 ESXi 主机上安装 NVIDIA vGPU Manager (VIB)。 |
|
| 4 | 验证 NVIDIA 驱动程序操作和 GPU 虚拟化模式。 |
|
| 5 | 在配置了 GPU 的集群上启用工作负载管理。结果在启用了 vGPU 的 ESXi 主机上运行的主管集群。 |
|
| 6 | 为 Tanzu Kubernetes 版本创建* 或更新内容库,并在库中填充 vGPU 工作负载所需的受支持 Ubuntu OVA。 |
请参见
管理员步骤 6:使用 Tanzu Kubernetes Ubuntu 版本创建或更新内容库。
注: * 如有必要。如果已为 TKGS 集群 Photon 映像创建了内容库,则无需为 Ubuntu 映像创建新的内容库。
|
| 7 | 创建自定义虚拟机类并选择特定的 vGPU 配置文件。 |
|
| 8 | 为 TKGS GPU 集群创建并配置 vSphere 命名空间:为持久卷添加具有编辑权限和存储的用户。 |
|
| 9 | 将包含 Ubuntu OVA 的内容库和 vGPU 的自定义虚拟机类与您为 TGKS 创建的 vSphere 命名空间相关联。 |
|
| 10 | 验证是主管集群否已置备,是否可供集群运维人员访问。 |
管理员步骤 0:查看系统要求
| 要求 | 描述 |
|---|---|
| vSphere 基础架构 |
vSphere 7 Update3 Monthly Patch 1 ESXi 内部版本 vCenter Server build |
| 工作负载管理 |
vSphere 命名空间版本
|
| 主管集群 |
主管集群 版本
|
| TKR Ubuntu OVA | Ubuntu Tanzu Kubernetes 版本
|
| NVIDIA vGPU 主机驱动程序 |
从 NGC 网站下载 VIB。有关详细信息,请参见 vGPU 软件驱动程序文档。例如:
|
| 用于 vGPU 的 NVIDIA 许可证服务器 |
您的组织提供的 FQDN |
管理员步骤 1:在 ESXi 主机上安装受支持的 NVIDIA GPU 设备
要在 TKGS 上部署 AI/ML 工作负载,请在将启用工作负载管理的 vCenter 集群中的每个 ESXi 主机上安装一个或多个受支持的 NVIDIA GPU 设备。
要查看兼容的 NVIDIA GPU 设备,请参阅 VMware 兼容性指南。
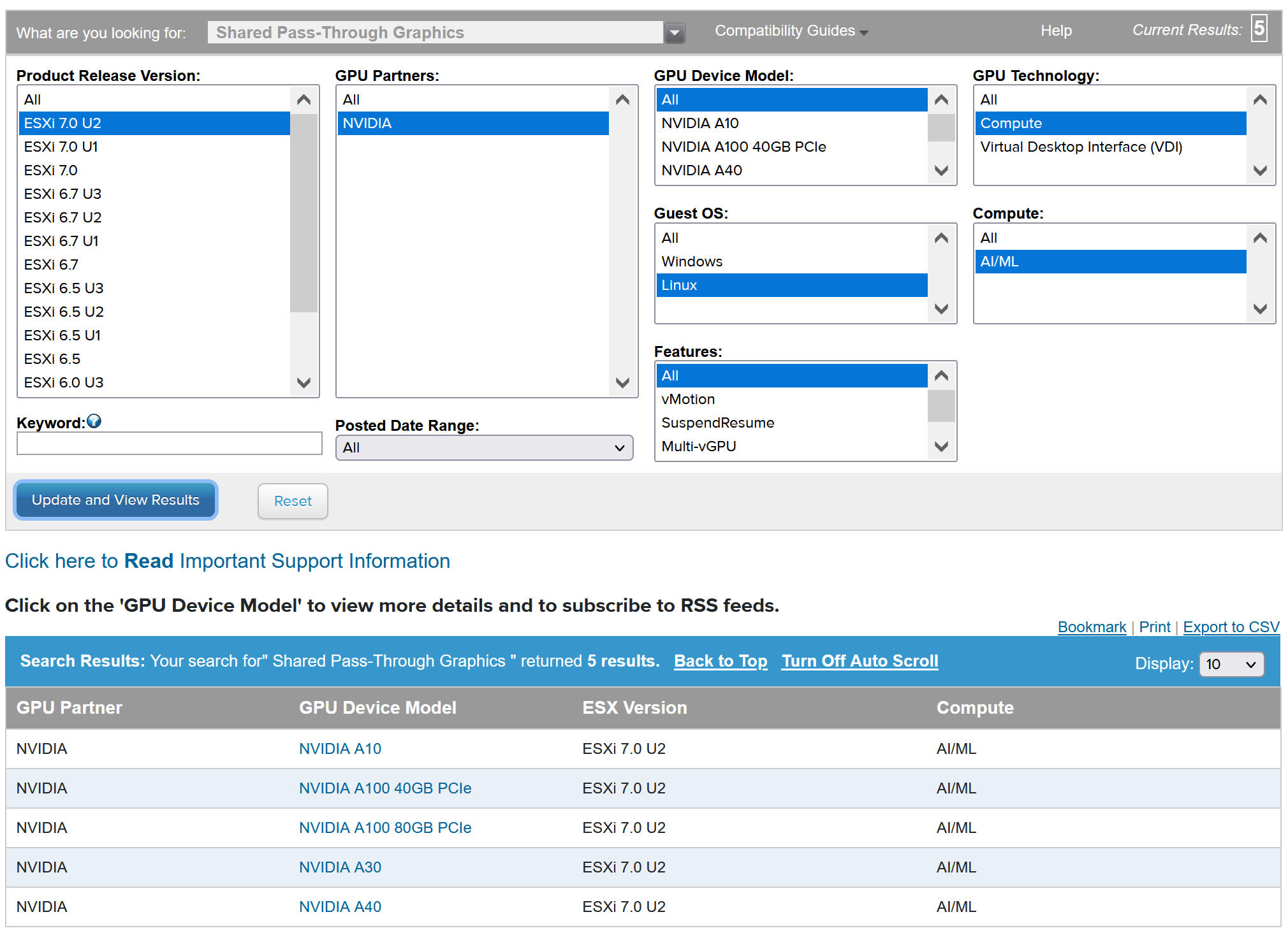
NVIDA GPU 设备应支持最新的 NVIDIA AI Enterprise (NVAIE) vGPU 配置文件。有关指导,请参阅 NVIDIA 虚拟 GPU 软件支持的 GPU 文档。
例如,以下 ESXi 主机上安装了两个 NVIDIA GPU A100 设备。
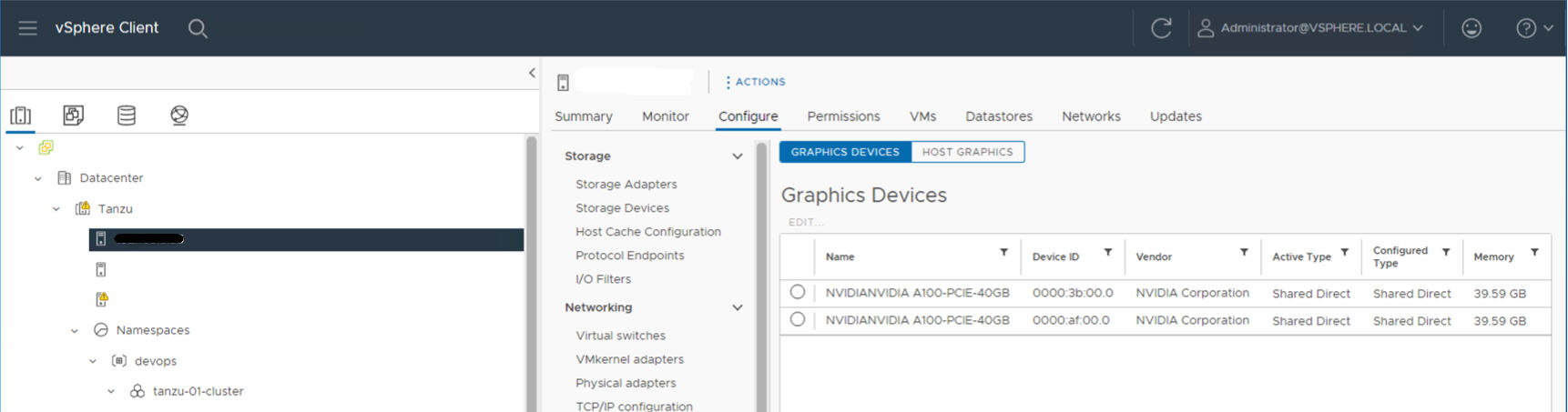
管理员步骤 2:针对 vGPU 操作配置每个 ESXi 主机
通过启用直接共享和 SR-IOV,配置 vGPU 的每个 ESXi 主机。
在每个 ESXi 主机上启用直接共享
要解锁 NVIDIA vGPU 功能,请在将启用工作负载管理的 vCenter 集群中的每个 ESXi 主机上启用直接共享模式。
- 使用 vSphere Client 登录 vCenter Server。
- 选择 vCenter 集群中的 ESXi 主机。
- 选择。
- 选择 NVIDIA GPU 加速器设备。
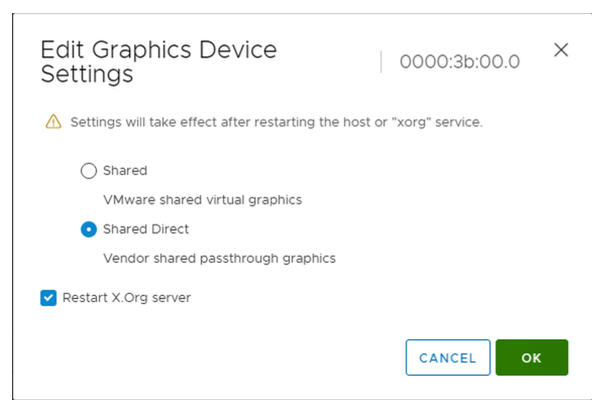
- 编辑图形设备设置。
- 选择直接共享。
- 选择重新启动 X.Org 服务器。
- 单击确定保存配置。
- 右键单击 ESXi 主机,然后将其置于维护模式。
- 重新引导主机。
- 当主机再次运行时,将其退出维护模式。
- 对将启用工作负载管理的 vCenter 集群中的每个 ESXi 主机重复此过程。
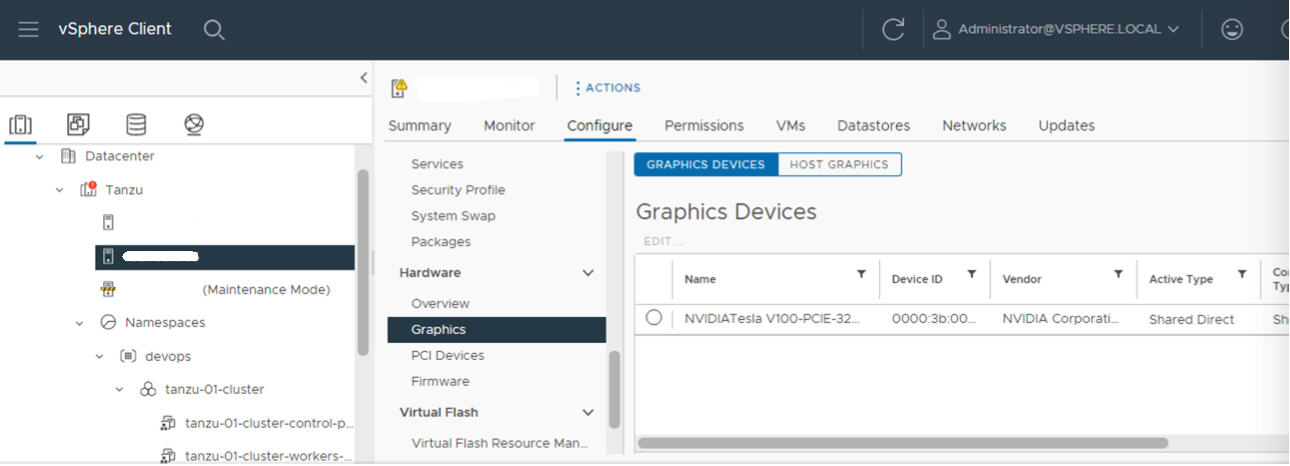
为 NVIDIA GPU A30 和 A100 设备启用 SR-IOV BIOS
如果使用多实例 GPU(MIG 模式)所需的 NVIDIA A30 或 A100 GPU 设备,则必须在 ESXi 主机上启用 SR-IOV。如果未启用 SR-IOV,Tanzu Kubernetes 集群节点虚拟机将无法启动。如果发生这种情况,您会在启用了工作负载管理的 vCenter Server 的近期任务窗格中看到以下错误消息。
Could not initialize plugin libnvidia-vgx.so for vGPU nvidia_aXXX-xx. Failed to start the virtual machine. Module DevicePowerOn power on failed.
要启用 SR-IOV,请使用 Web 控制台登录到 ESXi 主机。选择。选择 NVIDIA GPU 设备,然后单击配置 SR-IOV。您可以从此处启用 SR-IOV。有关其他指导,请参见 vSphere 文档中的单根 I/O 虚拟化 (SR-IOV)。
管理员步骤 3:在每个 ESXi 主机上安装 NVIDIA 主机管理器驱动程序
要运行具有 NVIDIA vGPU 图形加速的 Tanzu Kubernetes 集群节点虚拟机,请在将启用工作负载管理的 vCenter 集群中的每个 ESXi 主机上安装 NVIDIA 主机管理器驱动程序。
NVIDIA vGPU 主机管理器驱动程序组件打包在 vSphere 安装包 (VIB) 中。NVAIE VIB 由您的组织通过其 NVIDIA GRID 许可计划提供给您。VMware 既不提供 NVAIE VIB,也不提供它们的下载服务。根据 NVIDIA 许可计划,许可服务器由您的组织设置。有关详细信息,请参阅 NVIDIA 虚拟 GPU 软件快速入门指南。
esxcli system maintenanceMode set --enable true esxcli software vib install -v ftp://server.domain.example.com/nvidia/signed/NVIDIA_bootbank_NVIDIA-VMware_ESXi_7.0_Host_Driver_460.73.02-1OEM.700.0.0.15525992.vib esxcli system maintenanceMode set --enable false /etc/init.d/xorg restart
管理员步骤 4:验证 ESXi 主机是否已做好执行 NVIDIA vGPU 操作的准备
- 通过 SSH 登录到 ESXi 主机,进入 shell 模式,然后运行命令
nvidia-smi。NVIDIA 系统管理界面是由 NVIDA vGPU 主机管理器提供的命令行实用程序。运行此命令将返回主机上的 GPU 和驱动程序。 - 运行以下命令以验证是否已正确安装 NVIDIA 驱动程序:
esxcli software vib list | grep NVIDA。 - 验证主机是否配置了 GPU 直接共享并启用了 SR-IOV(如果使用的是 NVIDIA A30 或 A100 设备)。
- 使用 vSphere Client,在为 GPU 配置的 ESXi 主机上创建一个包含 PCI 设备的新虚拟机。NVIDIA vGPU 配置文件应显示且可选择。
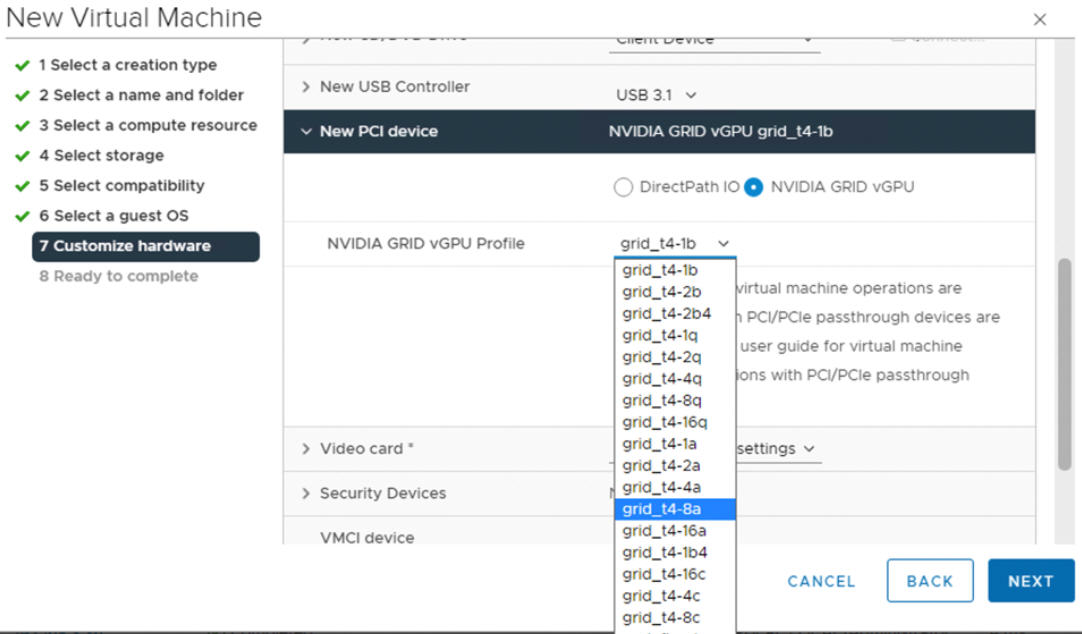
管理员步骤 5:在配置了 vGPU 的 vCenter 集群上启用工作负载管理
现在,ESXi 主机已配置为支持 NVIDIA vGPU,请创建包含这些主机的 vCenter 集群。要支持工作负载管理,vCenter 集群必须满足特定要求,包括共享存储、高可用性、全自动 DRS。
要启用工作负载管理,还需要选择网络堆栈(本机 vSphere vDS 网络连接或 NSX-T Data Center 网络连接)。如果使用 vDS 网络连接,则需要安装负载均衡器(NSX Advanced 或 HAProxy)。
| 任务 | 说明 |
|---|---|
| 创建满足启用工作负载管理所需要求的 vCenter 集群 | 在 vSphere 集群上配置 vSphere with Tanzu 的必备条件 |
| 为 主管集群(NSX-T 或具有负载均衡器的 vDS)配置网络连接。 | 为 NSX-T Data Center 配置 vSphere with Tanzu. 为 vSphere with Tanzu 配置 vSphere 网络连接和 NSX Advanced Load Balancer. |
| 启用工作负载管理 |
管理员步骤 6:使用 Tanzu Kubernetes Ubuntu 版本创建或更新内容库
NVIDIA vGPU 需要使用 Ubuntu 操作系统。VMware 提供了 Ubuntu OVA。不能将 PhotonOS Tanzu Kubernetes 版本用于 vGPU 集群。
| 内容库类型 | 描述 |
|---|---|
| 创建已订阅内容库并自动将 Ubuntu OVA 与您的环境同步。 | 创建、保护和同步 Tanzu Kubernetes 版本 的已订阅内容库 |
| 创建本地内容库并手动将 Ubuntu OVA 上载到您的环境。 | 创建、保护和同步 Tanzu Kubernetes 版本 的本地内容库 |

管理员步骤 7:创建包含 vGPU 配置文件的自定义虚拟机类
下一步是创建包含 vGPU 配置文件的自定义虚拟机类。系统在创建 Tanzu Kubernetes 集群节点时将使用此类定义。
- 使用 vSphere Client 登录到 vCenter Server。
- 选择工作负载管理。
- 选择服务。
- 选择虚拟机类。
- 单击创建虚拟机类。
- 在配置选项卡上,配置自定义虚拟机类。
配置字段 描述 名称 输入自定义虚拟机类的自描述性名称,例如 vmclass-vgpu-1。 vCPU 计数 2 CPU 资源预留 可选,单击“确定”留空 内存 例如 80 GB 内存资源预留 100%(如果在虚拟机类中配置了 PCI 设备,则强制使用此值) PCI 设备 是 注: 针对 PCI 设备选择“是”将告知系统您使用的是 GPU 设备,并将更改虚拟机类配置以支持 vGPU 配置。例如:
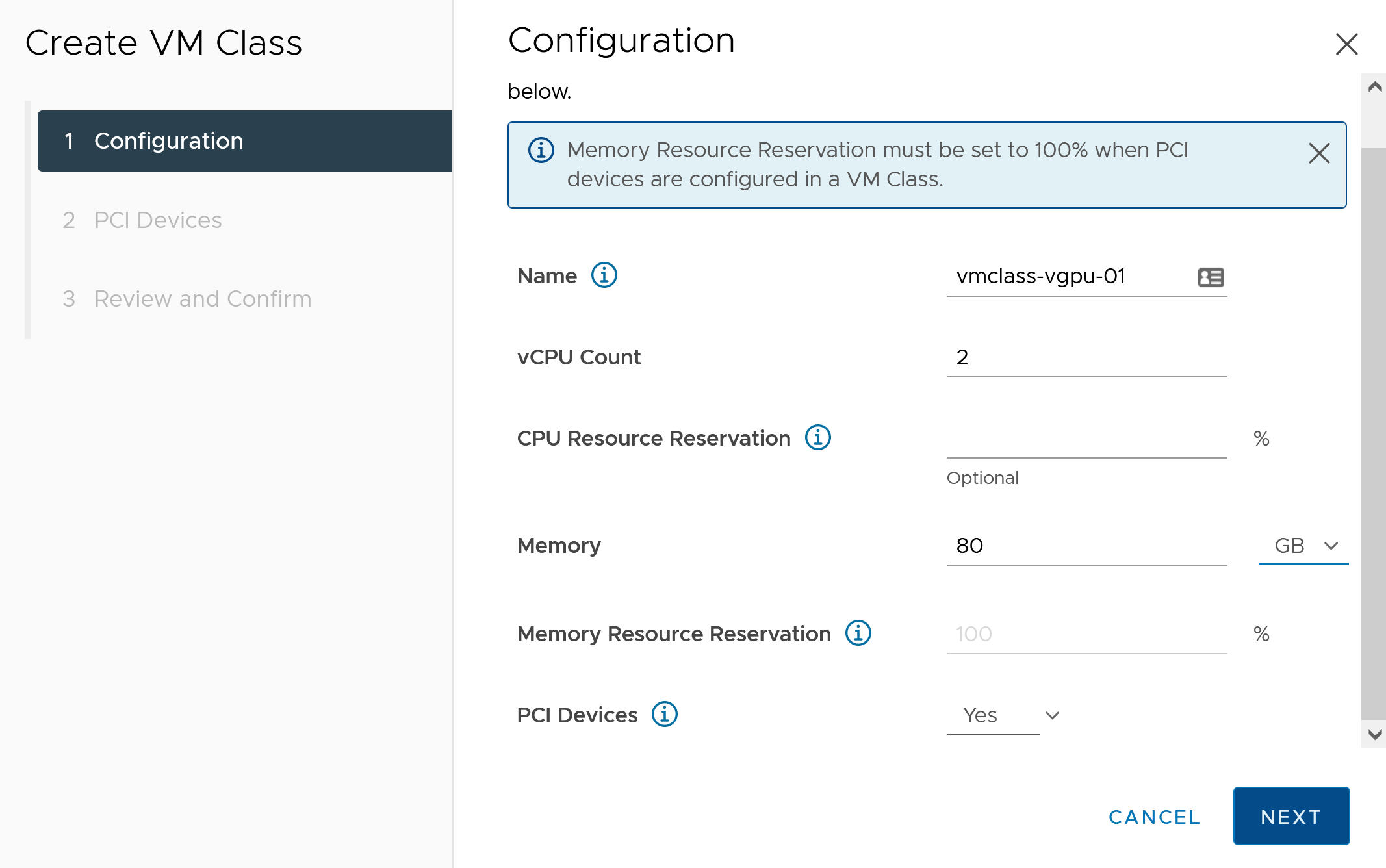
- 单击下一步。
- 在 PCI 设备选项卡上选择 选项。
- 配置 NVIDIA vGPU 型号。
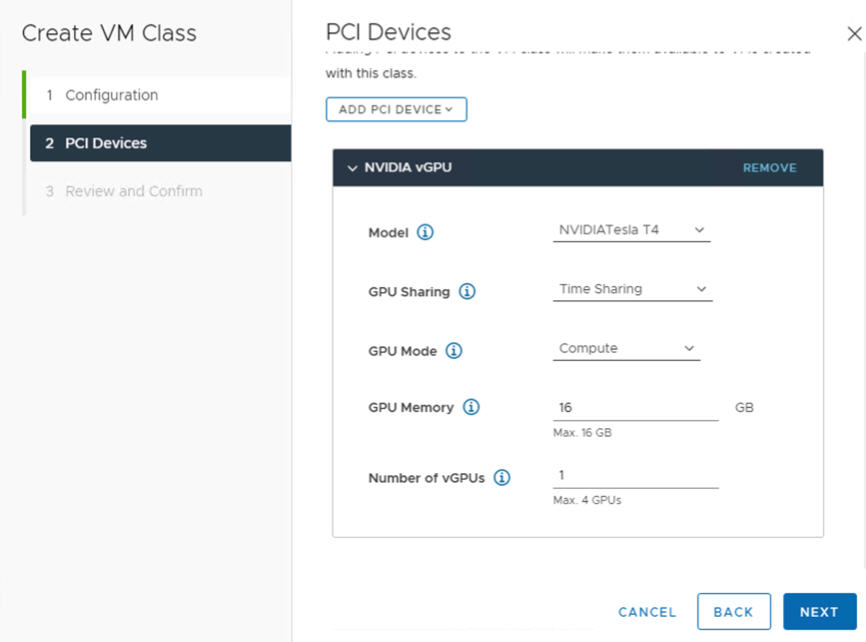
NVIDIA vGPU 字段 描述 型号 从 菜单所提供的型号中选择 NVIDIA GPU 硬件设备型号。如果系统未显示任何配置文件,表示集群中的所有主机都不具有受支持的 PCI 设备。 GPU 共享 此设置定义如何在启用了 GPU 的虚拟机之间共享 GPU 设备。vGPU 实施有两种类型:时间共享和多实例 GPU 共享。
在时间共享模式下,vGPU 调度程序指示 GPU 在一段时间内按顺序为每个启用了 vGPU 的虚拟机执行工作,并将尽最大努力平衡各 vGPU 的性能。
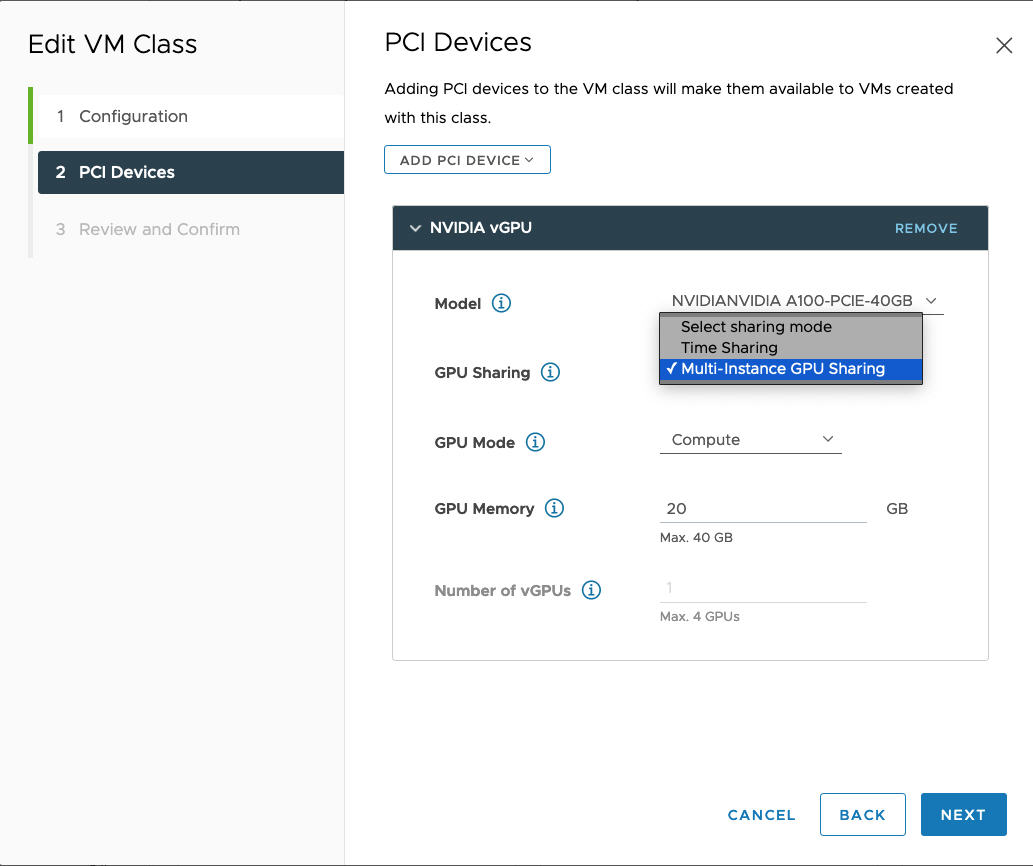
MIG 模式允许多个启用了 vGPU 的虚拟机在单个 GPU 设备上并行运行。MIG 模式基于较新的 GPU 架构,仅在 NVIDIA A100 和 A30 设备上受支持。如果没有看到 MIG 选项,表示您选择的 PCI 设备不支持该选项。
GPU 模式 计算 GPU 内存 例如 8 GB vGPU 数量 例如 1 例如,以下是在时间共享模式下配置的 NVIDIA vGPU 配置文件:
例如,以下是在具有受支持 GPU 设备的情况下在 MIG 模式下配置的 NVIDIA vGPU 配置文件:
- 单击下一步。
- 查看并确认您的选择。
- 单击完成。
- 验证虚拟机类列表中是否有新的自定义虚拟机类。
管理员步骤 8:为 TKGS GPU 集群创建和配置 vSphere 命名空间
为计划置备的每个 TKGS GPU 集群创建一个 vSphere 命名空间。通过添加具有编辑权限的 vSphere SSO 用户配置命名空间,并附加用于持久卷的存储策略。
要执行此操作,请参见创建和配置 vSphere 命名空间。
管理员步骤 9:将内容库和虚拟机类与 vSphere 命名空间相关联
| 任务 | 描述 |
|---|---|
| 将包含用于 vGPU 的 Ubuntu OVA 的内容库与将在其中置备 TKGS 集群的 vSphere 命名空间相关联。 | |
| 将具有 vGPU 配置文件的自定义虚拟机类与将在其中置备 TKGS 集群的 vSphere 命名空间相关联。 |
管理员步骤 10:验证主管集群是否可访问
最后一个管理任务是验证 主管集群 是否已置备,是否可供集群运维人员用于为 AI/ML 工作负载置备 TKGS 集群。
- 下载并安装 适用于 vSphere 的 Kubernetes CLI 工具。
- 连接到 主管集群。
- 为集群运维人员提供用于下载 适用于 vSphere 的 Kubernetes CLI 工具 的链接以及 vSphere 命名空间的名称。
