









VMware Aria Automation provides support for self-service catalog items that DevOps engineers and data scientists can use to provision AI workloads in VMware Private AI Foundation with NVIDIA in a user-friendly and customizable way.
Prerequisites
As a cloud administrator, verify that the VMware Private AI Foundation with NVIDIA environment is configured. See Preparing VMware Cloud Foundation for Private AI Workload Deployment.
Connect VMware Aria Automation to a Workload Domain for VMware Private AI Foundation with NVIDIA
Before you can add the catalog items for provisioning AI applications by using VMware Aria Automation, you connect VMware Aria Automation to VMware Cloud Foundation.
Procedure
Create AI Catalog Items in VMware Aria Automation using the Catalog Setup Wizard
As a cloud administrator, you use the Catalog Setup Wizard in VMware Aria Automation to set up and provide GPU-enabled deep learning virtual machines and VMware Tanzu Kubernetes Grid(TKG) clusters as catalog items that data scientists and DevOps teams in your organization can request in the self-service Automation Service Broker catalog.
How does the Catalog Setup Wizard work
- Add a cloud account. Cloud accounts are the credentials that are used to collect data from and deploy resources to your vCenter instance.
- Add an NVIDIA license.
- Configure a VMware Data Services Manager integration.
- Select content to add to the Automation Service Broker catalog.
- Create a project. The project links your users with cloud account regions, so that they can deploy cloud templates with networks and storage resources to your vCenter instance.
- AI Workstation – a GPU-enabled virtual machine that can be configured with desired vCPU, vGPU, memory, and the option to pre-install AI/ML frameworks like PyTorch, CUDA Samples, and TensorFlow.
- AI RAG Workstation – a GPU-enabled virtual machine with Retrieval Augmented Generation (RAG) reference solution.
- Triton Inference Server – a GPU-enabled virtual machine with Triton Inference Server.
- AI Kubernetes Cluster – a VMware Tanzu Kubernetes Grid Cluster with GPU-capable worker nodes to run AI/ML cloud-native workloads.
- AI Kubernetes RAG Cluster – a VMware Tanzu Kubernetes Grid Cluster with GPU-capable worker nodes to run a reference RAG solution.
- DSM Database – a pgvector database managed by VMware Data Services Manager.
- AI RAG Workstation with DSM – a GPU-enabled virtual machine with a pgvector database managed by VMware Data Services Manager.
- AI Kubernetes RAG Cluster with DSM – a VMware Tanzu Kubernetes Grid Cluster with a pgvector database managed by VMware Data Services Manager.
- Enable provisioning of AI workloads on another supervisor.
- Accommodate a change in your NVIDIA AI Enterprise license, including the client configuration .tok file and license server, or the download URL for the vGPU guest drivers for a disconnected environment.
- Accommodate a deep learning VM image change.
- Use other vGPU or non-GPU VM classes, storage policy, or container registry.
- Create catalog items in a new project.
You can modify the templates for the catalog items that the wizard created to meet the specific needs of your organization.
Before you begin
- Verify that VMware Private AI Foundation with NVIDIA is configured up to this step of the deployment workflow. See Preparing VMware Cloud Foundation for Private AI Workload Deployment.
Procedure
- After you log into VMware Aria Automation, click Launch Quickstart.
- On the Private AI Automation Services card, click Start.
- Select the cloud account to provision access to.
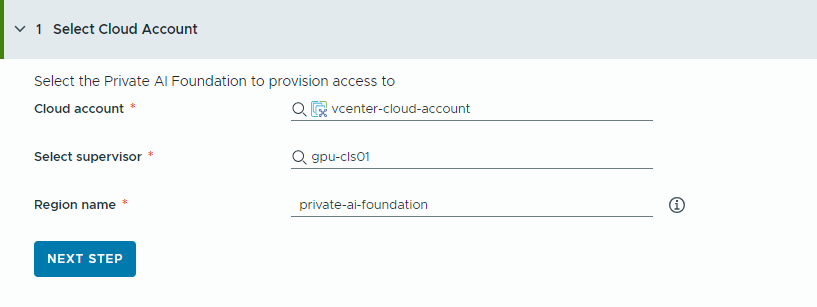
Remember that all values here are use case samples. Your account values depend on your environment.
- Select a vCenter cloud account.
- Select a GPU-enabled supervisor.
- Enter a region name.
A region is automatically selected if the supervisor is already configured with a region.
If the supervisor is not associated with a region, you add one in this step. Consider using a descriptive name for your region that helps your users distinguish GPU-enabled regions from other available regions.
- Click Next Step.
- Provide information about your NVIDIA license server.
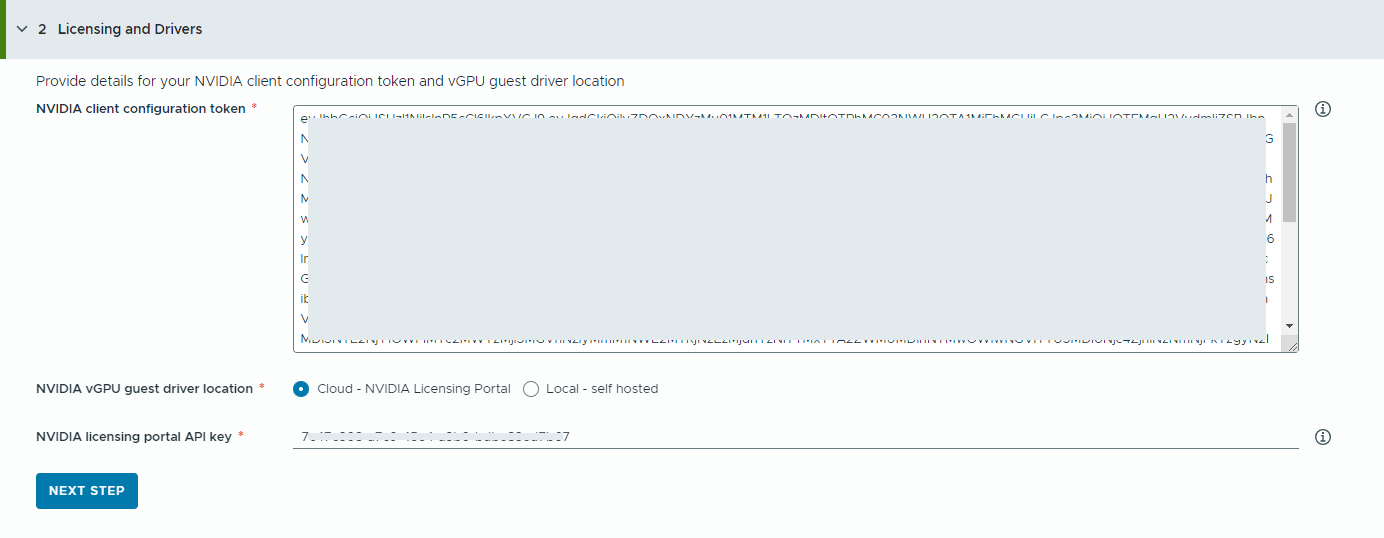
- Copy and paste the contents of the NVIDIA client configuration token.
The client configuration token is used to assign a license to the guest vGPU driver in the deep learning virtual machine and the GPU Operators on TKG clusters.
- Select the location of the NVIDIA vGPU drivers.
- Cloud – the NVIDIA vGPU driver is hosted on the NVIDIA Licensing Portal.
You must provide the NVIDIA Licensing Portal API key, which is used to evaluate if a user has the right entitlement to download the NVIDIA vGPU drivers. The API key must be a UUID.
- Local – the NVIDIA vGPU driver is hosted on-premises and is accessed from а private network.
You must provide the location of the vGPU guest drivers for VMs.
For air-gapped environments, the vGPU driver must be avaiable on your private network or data center.
- Cloud – the NVIDIA vGPU driver is hosted on the NVIDIA Licensing Portal.
- Click Next Step.
- Copy and paste the contents of the NVIDIA client configuration token.
- Configure a VMware Data Services Manager (DSM) database for RAG applications to generate separate database catalog items.
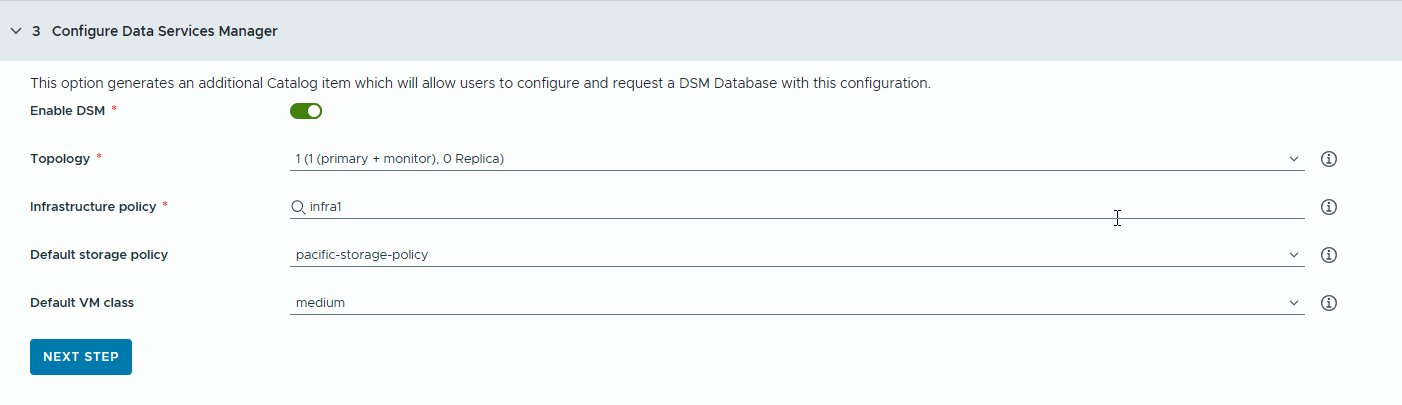
You use VMware Data Services Manager to create vector databases, such as a PostgreSQL database with pgvector extension.
Databases are provisioned in a different workload domain than the deep learning VMs, so you must use different VM classes and storage profiles for each. For VMware Data Services Manager databases, select a storage policy and VM class that are suitable for RAG use cases.
- Turn on the toggle.
If you want your developers and catalog users to share a single DSM database, use this option.Note: When the toggle is on, a new DSM database catalog item is created.
If a DSM integration is not required for your project, you can turn the toggle off and continue with the next step. In this case, a DSM catalog item is not generated, but your users still have an embedded DSM database on other RAG catalog items.
- Select a replica mode and topology.
Configuration of the database nodes depends on the replica mode.
- Single Server – one primary node without replicas.
- Single vSphere Cluster – three nodes (1 primary, 1 monitor, 1 replica) on a single vSphere cluster providing non-disruptive upgrades.
- Select an infrastructure policy.
The infrastructure policy defines the quality and quantity of resources the database can consume from vSphere clusters.
Once you select an infrastructure policy, you can choose from storage policies and VM classes that are associated with the infrastructure policy.
- Select a default storage policy.
The storage policy defines storage placement and resources for the database.
- Select a default VM class.
A VM class is not available to provision the newly requested database on.
Note that DSM VM classes are different from Supervisor VM classes.
- Turn on the toggle.
- Configure the catalog items.
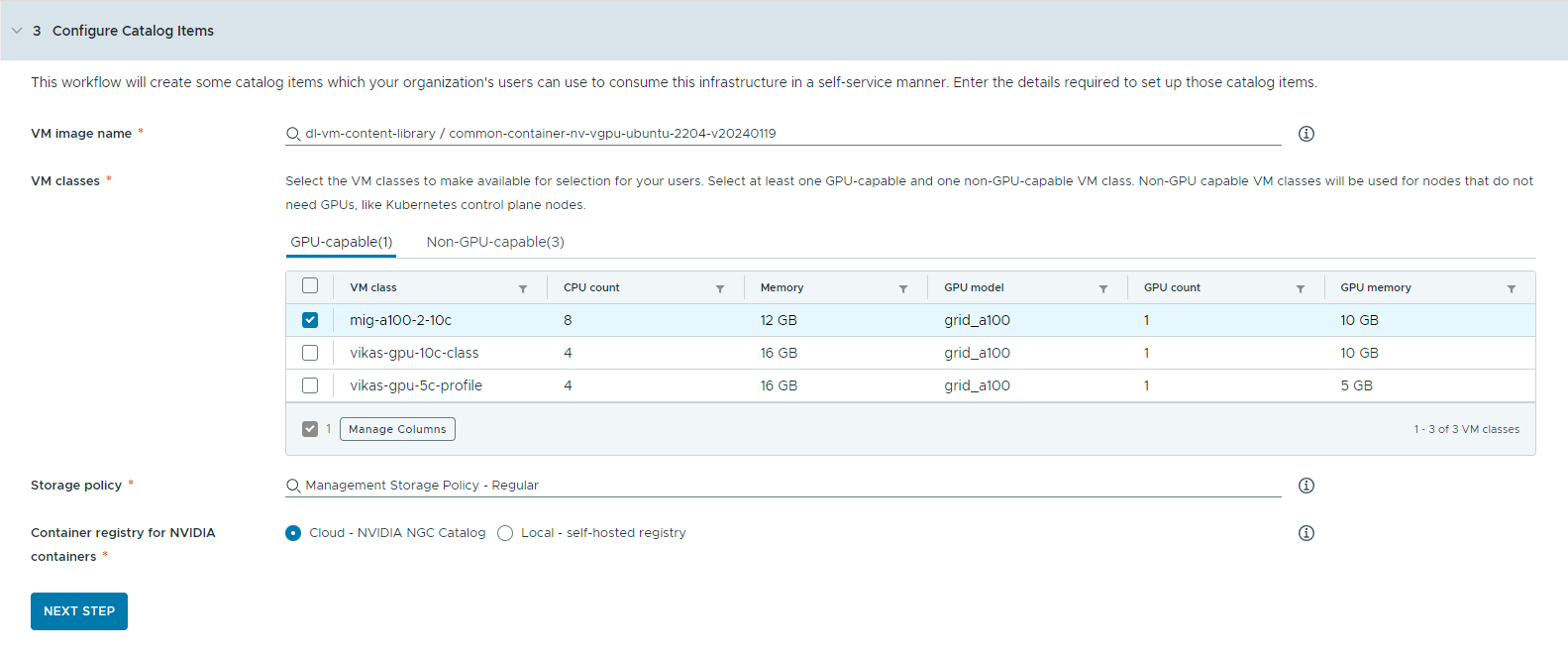
- Select the content library that contains the deep learning VM image.
You can access only one content library at a time. If the content library contains Kubernetes images, those images are filtered out for easier navigation.
- Select the VM image you want to use to create the workstation VM.
- Select a Tanzu Kubernetes release you want to use for AI Kubernetes Cluster deployments.
The Tanzu Kubernetes release (TKr) is the Kubernetes runtime version that is deployed when a user requests a Kubernetes cluster. You can select from the three most recent Tanzu Kubernetes release versions that are supported for VMware Private AI Foundation.
- Select the VM classes you want to make available to your catalog users.
You must add at least one GPU-capable and one non-GPU-capable class.
- GPU-enabled VM classes are used for the deep learning VM and for the worker nodes of the TKG cluster. When the catalog item is deployed, the TKG cluster is created with the selected VM classes.
- Non-GPU-capable nodes are required to run the Kubernetes control planes.
- VM classes with Unified Virtual Memory (UVM) enabled are required to run AI workstations with Triton Inference Server.
- Select a storage policy.
The storage policy defines storage placement and resources for the virtual machines.
The storage policy you define for the VM is not the same as the VMware Data Services Manager storage policy.
- Specify the container registry where you want to pull NVIDIA GPU Cloud resources.
- Cloud – the container images are pulled from the NVIDIA NGC catalog.
- Local – for air-gapped environments, the containers are pulled from a private registry.
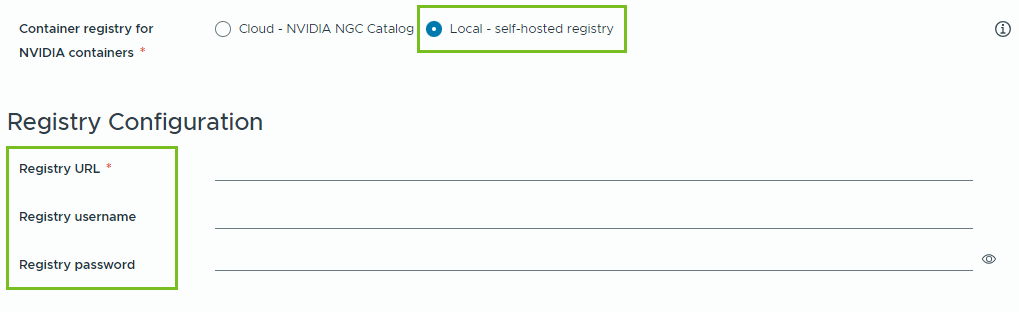
You must provide the location of the self-hosted registry. If the registry requires authentication, you must also provide login credentials.
You can use Harbor as a local registry for container images from the NVIDIA NGC catalog. See Setting Up a Private Harbor Registry in VMware Private AI Foundation with NVIDIA.
- (Optional) Configure a proxy server.
In environments without direct Internet access, the proxy server is used to download the vGPU driver and pull the non-RAG AI Workstation containers.
Note: Support for air-gapped environments is available for the AI Workstation and Triton Inference Server catalog items. The AI RAG Workstation and AI Kubernetes Cluster items do not support air-gapped environments and need Internet connectivity. - Click Next Step.
- Select the content library that contains the deep learning VM image.
- Configure access to the catalog items by creating a project and assigning users.
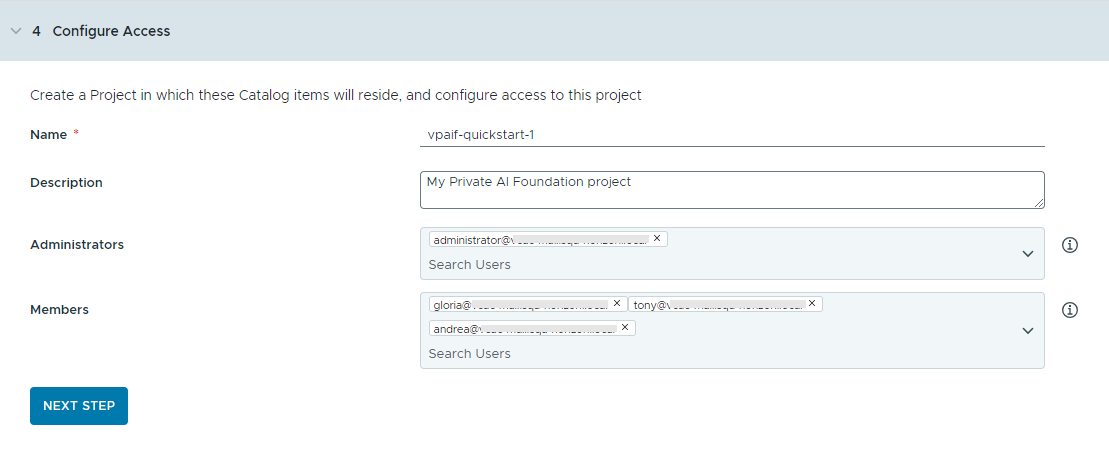
Projects are used to manage people, assigned resources, cloud templates, and deployments.
- Enter a name and description for the project.
The project name must contain only lowercase alphanumeric characters or hyphens (-).
- To make the catalog items available to others, add an Administrator and Members.
Administrators have more permissions than members. For more information, see What are the VMware Aria Automation user roles.
- Click Next Step.
- Enter a name and description for the project.
- Verify your configuration on the Summary page.
Consider saving the details for your configuration before running the wizard.
- Click Run Quickstart.
Results
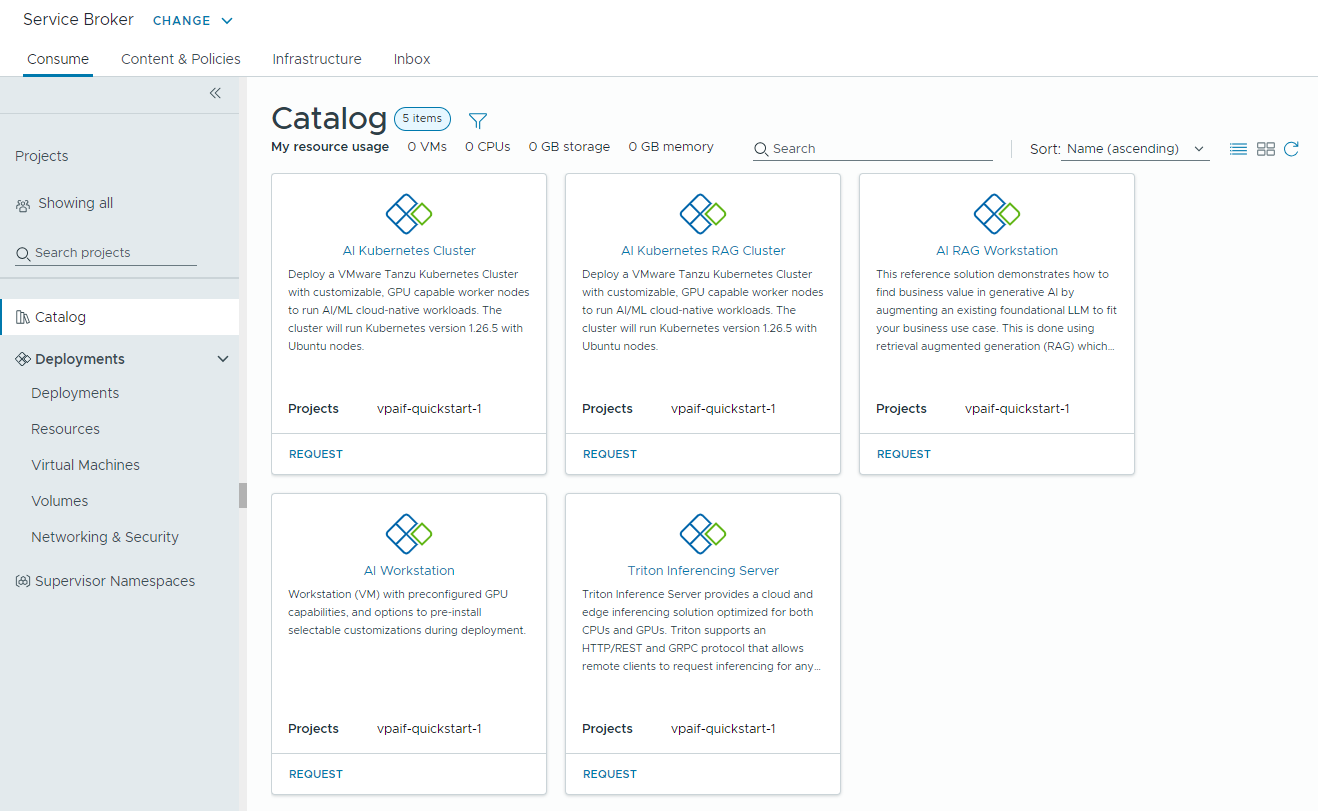
The following catalog items – AI Workstation, AI RAG Workstation, AI RAG Workstation with DSM, DSM Database, Triton Inferencing Server, AI Kubernetes Cluster, AI Kubernetes RAG Cluster, and AI Kubernetes RAG Cluster with DSM, are created in the Automation Service Broker catalog and users in your organization can now deploy them.
Troubleshooting
- If the Catalog Setup Wizard fails, run the wizard again for a different project.
