









Para permitir que los desarrolladores implementen cargas de trabajo de AI/ML en clústeres TKGS, como administrador de vSphere, configure el entorno de vSphere with Tanzu para que admita el hardware de NVIDIA GPU.
Flujo de trabajo del administrador de vSphere para implementar cargas de trabajo de AI/ML en clústeres TKGS
| Paso | Acción | Vincular |
|---|---|---|
| 0 | Revise los requisitos del sistema. |
Consulte Paso 0 del administrador: Revisar los requisitos del sistema. |
| 1 | Instale un dispositivo NVIDIA GPU compatible en hosts ESXi. |
Consulte Paso 1 del administrador: Instalar un dispositivo NVIDIA GPU compatible en hosts ESXi. |
| 2 | Configure los ajustes de gráficos de dispositivos ESXi para las operaciones de vGPU. |
Consulte Paso 2 del administrador: Configurar cada host ESXi para operaciones de vGPU. |
| 3 | Instale el administrador de NVIDIA vGPU (VIB) en cada host ESXi. |
|
| 4 | Compruebe la operación del controlador de NVIDIA y el modo de virtualización de GPU. |
|
| 5 | Habilite la administración de cargas de trabajo en el clúster configurado para GPU. El resultado es un clúster supervisor que se ejecuta en hosts ESXi habilitados para vGPU. |
|
| 6 | Cree* o actualice una biblioteca de contenido para las versiones de Tanzu Kubernetes y rellene la biblioteca con el archivo OVA de Ubuntu compatible que se requiere para las cargas de trabajo de vGPU. |
Consulte
Paso 6 del administrador: Crear o actualizar una biblioteca de contenido con la versión de Ubuntu para Tanzu Kubernetes.
Nota: *Si es necesario. Si ya tiene una biblioteca de contenido para imágenes Photon de clústeres de TKGS, no cree una biblioteca de contenido nueva para imágenes de Ubuntu.
|
| 7 | Cree una clase de máquina virtual personalizada con un determinado perfil de vGPU seleccionado. |
Consulte Paso 7 del administrador: Crear una clase de máquina virtual personalizada con el perfil de vGPU. |
| 8 | Cree y configure un espacio de nombres de vSphere para clústeres GPU de TKGS: agregue un usuario con permisos de edición y almacenamiento para volúmenes persistentes. |
|
| 9 | Asocie la biblioteca de contenido con el archivo OVA de Ubuntu y la clase de máquina virtual personalizada para vGPU con el espacio de nombres de vSphere que creó para TGKS. |
|
| 10 | Compruebe que se aprovisione el clúster supervisor y que el operador del clúster pueda acceder a él. |
Consulte Paso 10 del administrador: comprobar que se pueda acceder al clúster supervisor. |
Paso 0 del administrador: Revisar los requisitos del sistema
| Requisito | Descripción |
|---|---|
| Infraestructura de vSphere |
vSphere 7 Update3, revisión mensual 1 ESXi compilación vCenter Server compilación |
| Administración de cargas de trabajo |
Versión de espacio de nombres de vSphere
|
| Clúster supervisor |
Versión de clúster supervisor
|
| OVA de TKR Ubuntu | versión de Tanzu Kubernetes Ubuntu
|
| Controlador de host NVIDIA vGPU |
Descargue el VIB del sitio web de NGC. Si desea más información, consulte la documentación del controlador del software vGPU. Por ejemplo:
|
| Servidor de licencias NVIDIA para vGPU |
FQDN proporcionado por la organización |
Paso 1 del administrador: Instalar un dispositivo NVIDIA GPU compatible en hosts ESXi
Para implementar cargas de trabajo de AI/ML en TKGS, instale uno o varios dispositivos NVIDIA GPU compatibles en cada host ESXi que contenga el clúster de vCenter en el que se habilitará Administración de cargas de trabajo.
Para ver los dispositivos NVIDIA GPU compatibles, consulte la guía de compatibilidad de VMware.

El dispositivo NVIDIA GPU debe admitir los perfiles de vGPU NVIDIA AI Enterprise (NVAIE) más recientes. Consulte la documentación de GPU compatibles con el software NVIDIA Virtual GPU para obtener instrucciones.
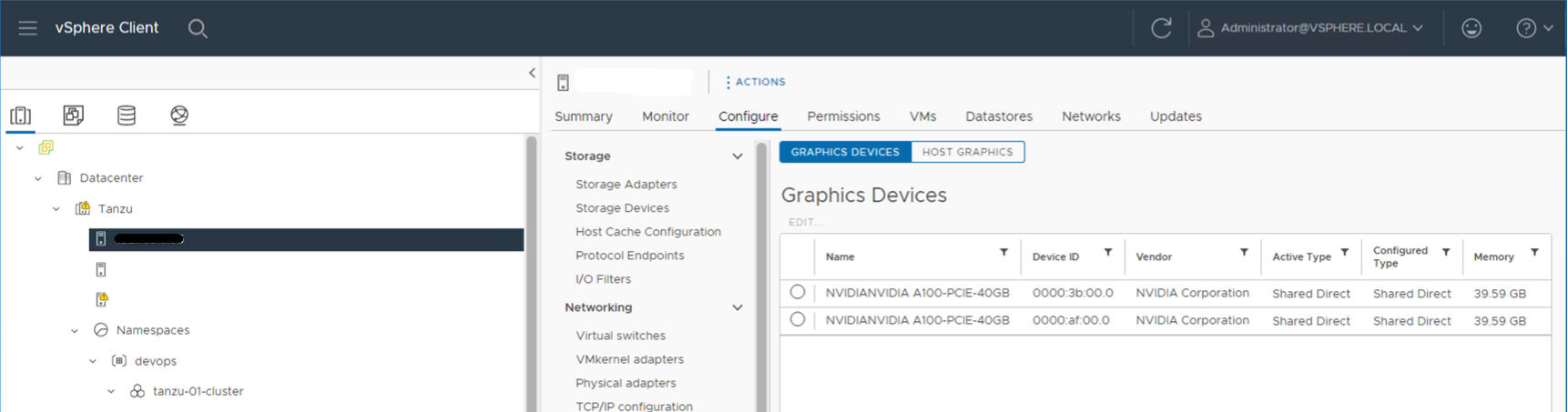
Por ejemplo, el siguiente host ESXi tiene dos dispositivos NVIDIA GPU A100 instalados.
Paso 2 del administrador: Configurar cada host ESXi para operaciones de vGPU
Configure cada host ESXi para vGPU habilitando Compartidos directos y SR-IOV.
Habilitar Compartidos directos en cada host ESXi
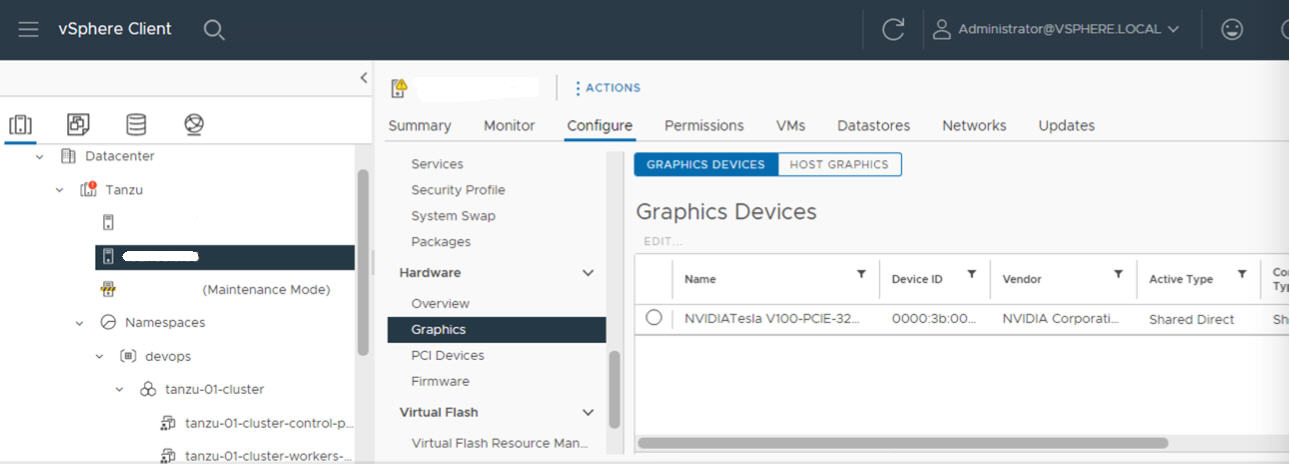
Para que la funcionalidad NVIDIA vGPU se desbloquee, habilite el modo Compartidos directos en cada host ESXi que contenga el clúster de vCenter en el que se habilitará Administración de cargas de trabajo.
- Inicie sesión en vCenter Server mediante vSphere Client.
- Seleccione un host ESXi en el clúster de vCenter.
- Seleccione .
- Seleccione el dispositivo acelerador de NVIDIA GPU.
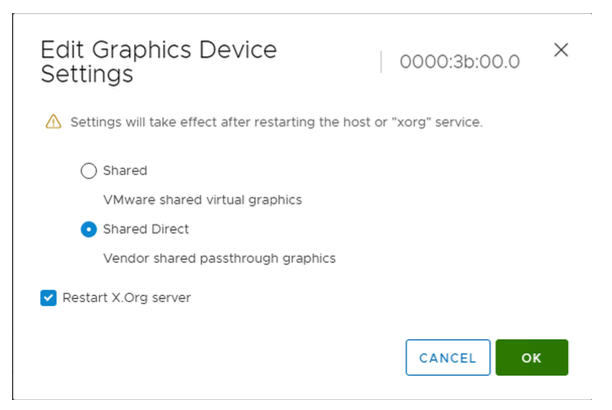
- Edite la configuración de dispositivos de gráficos.
- Seleccione Compartidos directos.
- Seleccione Reiniciar el servidor X.Org.
- Haga clic en Aceptar para guardar la configuración.
- Haga clic con el botón secundario en el host ESXi y póngalo en el modo de mantenimiento.
- Reinicie el host.
- Cuando el host vuelva a ejecutarse, salga del modo de mantenimiento.
- Repita este proceso para cada host ESXi en el clúster de vCenter en el que se habilitará Administración de cargas de trabajo.
Activar el BIOS de SR-IOV para dispositivos NVIDIA GPU A30 y A100
Si utiliza los dispositivos GPU NVIDIA A30 o A100, los cuales son necesarios para GPU de varias instancias (modo MIG), debe habilitar SR-IOV en el host ESXi. Si SR-IOV no está habilitado, no se pueden iniciar las máquinas virtuales del nodo del clúster de Tanzu Kubernetes. Si esto ocurre, verá el siguiente mensaje de error en el panel Tareas recientes de vCenter Server en el que está habilitada Administración de cargas de trabajo.
Could not initialize plugin libnvidia-vgx.so for vGPU nvidia_aXXX-xx. Failed to start the virtual machine. Module DevicePowerOn power on failed.
Para habilitar SR-IOV, inicie sesión en el host ESXi mediante la consola web. Seleccione . Seleccione el dispositivo NVIDIA GPU y haga clic en Configurar SR-IOV. Desde ahí, puede activar SR-IOV. Para ver más instrucciones, consulte Single Root I/O Virtualization (SR-IOV) en la documentación de vSphere.
Paso 3 del administrador: Instalar el controlador del administrador de hosts de NVIDIA en cada host ESXi
Para ejecutar las máquinas virtuales del nodo del clúster de Tanzu Kubernetes con aceleración de gráficos NVIDIA vGPU, instale el controlador del administrador de hosts de NVIDIA en cada host ESXi que contenga el clúster de vCenter en el que se habilitará Administración de cargas de trabajo.
Los componentes del controlador del administrador de hosts NVIDIA vGPU se empaquetan en un paquete de instalación de vSphere (VIB). La organización le proporciona el VIB de NVAIE a través de su programa de licencias NVIDIA GRID. VMware no proporciona los VIB de NVAIE ni hace que estén disponibles para descargarlos. Como parte del programa de licencias NVIDIA, su organización configura un servidor de licencias. Consulte la Guía de inicio rápido del software de GPU virtual para obtener más información.
esxcli system maintenanceMode set --enable true esxcli software vib install -v ftp://server.domain.example.com/nvidia/signed/NVIDIA_bootbank_NVIDIA-VMware_ESXi_7.0_Host_Driver_460.73.02-1OEM.700.0.0.15525992.vib esxcli system maintenanceMode set --enable false /etc/init.d/xorg restart
Paso 4 del administrador: Comprobar que los hosts ESXi estén listos para las operaciones de NVIDIA vGPU
- Acceda mediante SSH al host ESXi, entre en el modo de shell y ejecute el comando
nvidia-smi. La interfaz de administración del sistema NVIDIA es una utilidad de línea de comandos que proporciona el administrador de hosts de NVIDIA vGPU. Al ejecutar este comando, se devuelven los controladores y las GPU en el host. - Ejecute el siguiente comando para comprobar que el controlador de NVIDIA esté instalado correctamente:
esxcli software vib list | grep NVIDA. - Compruebe que el host esté configurado con Compartidos directos de GPU y que SR-IOV esté activado (si utiliza dispositivos NVIDIA A30 o A100).
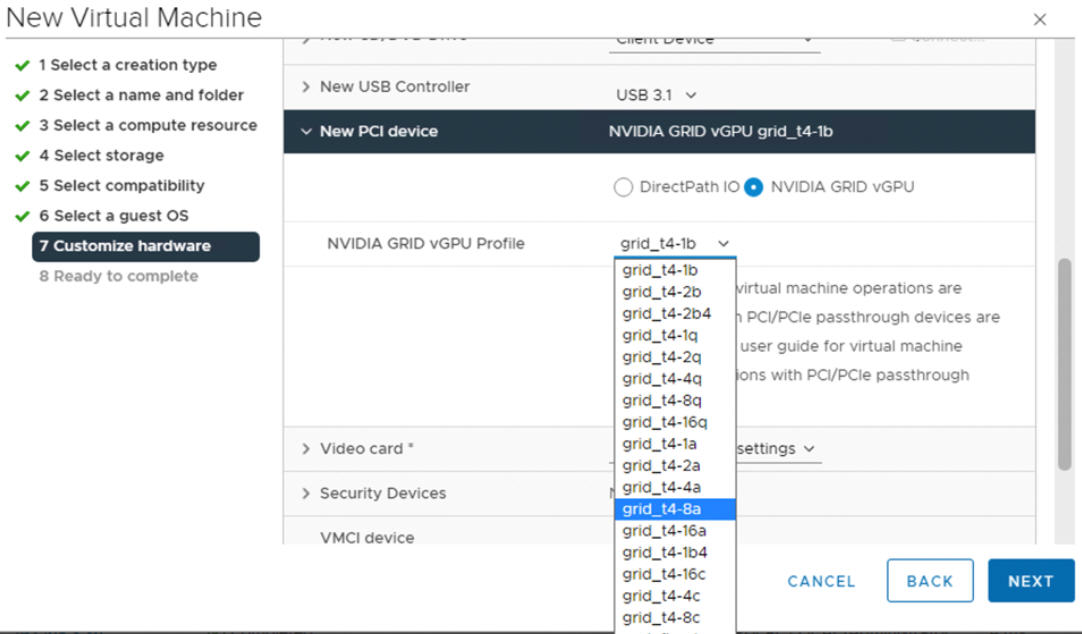
- Con vSphere Client, en el host ESXi que está configurado para GPU, cree una nueva máquina virtual con un dispositivo PCI incluido. El perfil de NVIDIA vGPU debe aparecer y se debe poder seleccionar.
Paso 5 del administrador: Habilitar la administración de cargas de trabajo en el clúster de vCenter configurado para vGPU
Ahora que los hosts ESXi están configurados para admitir NVIDIA vGPU, cree un clúster de vCenter que incluya estos hosts. Para admitir Administración de cargas de trabajo, el clúster de vCenter debe cumplir determinados requisitos, incluidos el almacenamiento compartido, la alta disponibilidad y el DRS completamente automatizado.
Para habilitar Administración de cargas de trabajo, también hay que seleccionar una pila de redes, ya sea de redes nativas de vSphere vDS o de redes de NSX-T Data Center. Si utiliza redes de vDS, debe instalar un equilibrador de carga, ya sea NSX Advanced o HAProxy.
| Tarea | Instrucciones |
|---|---|
| Crear un clúster de vCenter que cumpla los requisitos para habilitar Administración de cargas de trabajo | Requisitos previos para configurar vSphere with Tanzu en un clúster de vSphere |
| Configure las redes del clúster supervisor, ya sea NSX-T o vDS con un equilibrador de carga. | Configurar NSX-T Data Center para vSphere with Tanzu. Configurar redes de vSphere y NSX Advanced Load Balancer para vSphere with Tanzu. Configurar redes de vSphere y el equilibrador de carga de HAProxy para vSphere with Tanzu. |
| Habilitar Administración de cargas de trabajo |
Habilitar la administración de cargas de trabajo con redes de NSX-T Data Center. Habilitar la administración de cargas de trabajo con redes de vSphere. |
Paso 6 del administrador: Crear o actualizar una biblioteca de contenido con la versión de Ubuntu para Tanzu Kubernetes
NVIDIA vGPU requiere el sistema operativo Ubuntu. VMware proporciona un archivo OVA de Ubuntu para estos fines. No es posible utilizar la versión de Tanzu Kubernetes para PhotonOS para clústeres de vGPU.
| Tipo de biblioteca de contenido | Descripción |
|---|---|
| Cree una Biblioteca de contenido suscrita y sincronice automáticamente el archivo OVA de Ubuntu con su entorno. | Crear, proteger y sincronizar una biblioteca de contenido suscrita para las versiones de Tanzu Kubernetes |
| Cree una Biblioteca de contenido local y cargue manualmente el archivo OVA de Ubuntu a su entorno. | Crear, proteger y sincronizar una biblioteca de contenido local para versiones de Tanzu Kubernetes |

Paso 7 del administrador: Crear una clase de máquina virtual personalizada con el perfil de vGPU
El siguiente paso consiste en crear una clase de máquina virtual personalizada con un perfil de vGPU. El sistema utilizará esta definición de clase cuando cree los nodos del clúster de Tanzu Kubernetes.
- Inicie sesión en vCenter Server con vSphere Client.
- Seleccione Administración de cargas de trabajo.
- Seleccione Servicios
- Seleccione Clases de VM.
- Haga clic en Crear clase de VM.
- En la pestaña Configuración, configure la clase de máquina virtual personalizada.
Campo de configuración Descripción Nombre Introduzca un nombre descriptivo para la clase de máquina virtual personalizada, como vmclass-vgpu-1. Recuento de vCPU 2 Reserva de recursos de CPU Opcional, acepte para dejar en blanco Memoria 80 GB, por ejemplo Reserva de recursos de memoria 100 % (obligatorio cuando se configuran dispositivos PCI en una clase de máquina virtual) Dispositivos PCI Sí Nota: Al seleccionar Sí para Dispositivos PCI, se indica al sistema que se utiliza un dispositivo GPU y se cambia la configuración de la clase de máquina virtual para admitir la configuración de vGPU.Por ejemplo:
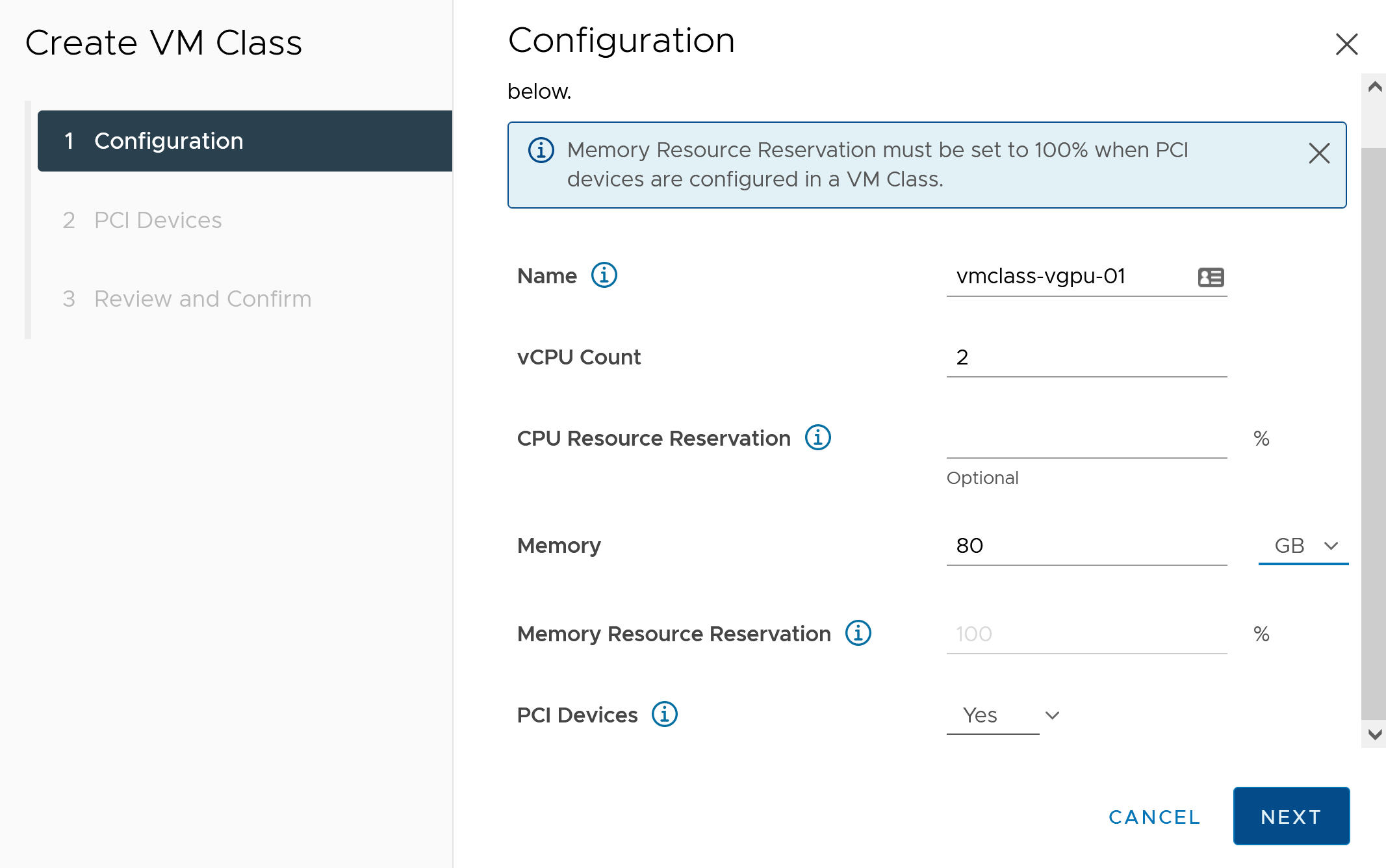
- Haga clic en Siguiente.
- En la pestaña Dispositivos PCI, seleccione la opción .
- Configure el modelo NVIDIA vGPU.
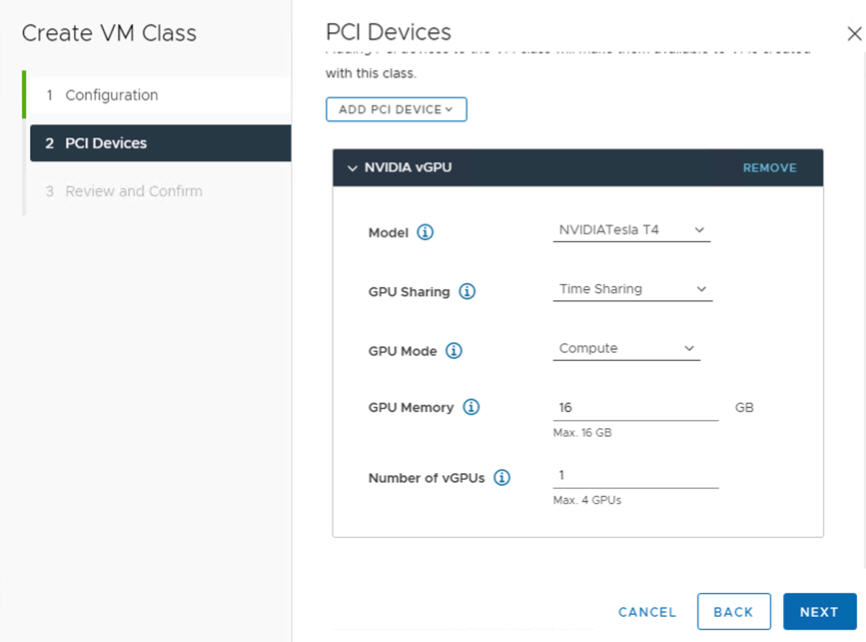
Campo NVIDIA vGPU Descripción Modelo Seleccione el modelo del dispositivo de hardware GPU NVIDIA de los disponibles en el menú . Si el sistema no muestra ningún perfil, ninguno de los hosts del clúster tiene dispositivos PCI compatibles. Uso compartido de GPU Este ajuste define cómo se comparte el dispositivo GPU entre máquinas virtuales habilitadas para GPU. Existen dos tipos de implementaciones de vGPU: Uso compartido de tiempo y Uso compartido de GPU de varias instancias.
En el modo de Uso compartido de tiempo, el programador de vGPU indica a la GPU que realice el trabajo para cada máquina virtual habilitada para vGPU en serie durante un período de tiempo con el mejor objetivo de esfuerzo de equilibrar el rendimiento entre las vGPU.
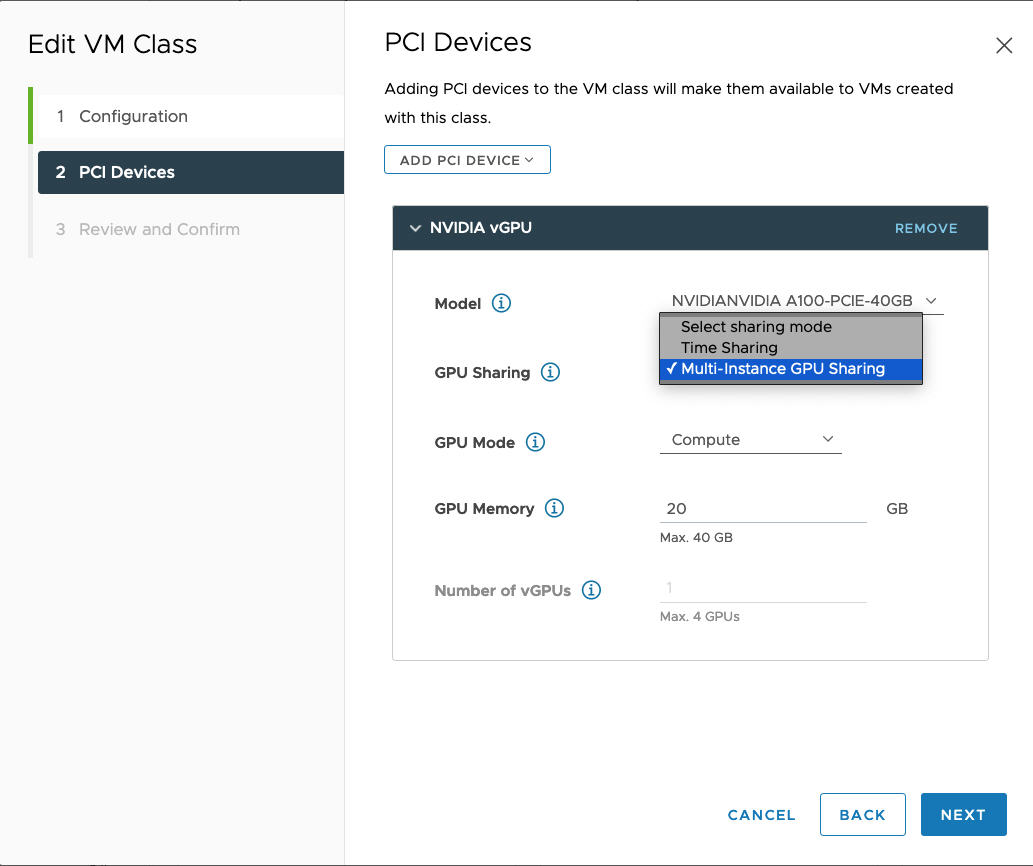
El modo MIG permite que varias máquinas virtuales habilitadas para vGPU se ejecuten en paralelo en un solo dispositivo GPU. El modo MIG se basa en una arquitectura de GPU más reciente y solo se admite en dispositivos NVIDIA A100 y A30. Si no ve la opción MIG, el dispositivo PCI que seleccionó no lo admite.
Modo GPU Cálculo Memoria de GPU 8 GB, por ejemplo Número de vGPU 1, por ejemplo Por ejemplo, este es un perfil de NVIDIA vGPU configurado en el modo Uso compartido de tiempo:
Por ejemplo, aquí se muestra un perfil de NVIDIA vGPU configurado en el modo MIG con un dispositivo GPU compatible:
- Haga clic en Siguiente.
- Revise y confirme las selecciones que hizo.
- Haga clic en Finalizar.
- Compruebe que la nueva clase de máquina virtual personalizada esté disponible en la lista de clases de máquinas virtuales.
Paso 8 de administración: Crear y configurar un espacio de nombres de vSphere para el clúster GPU de TKGS
Cree un espacio de nombres de vSphere para cada clúster GPU de TKGS que tenga previsto aprovisionar. Para configurar el espacio de nombres, agregue un usuario de SSO de vSphere con permisos de edición y asocie una directiva de almacenamiento para volúmenes persistentes.
Para ello, vea Creación y configuración de un espacio de nombres de vSphere.
Paso 9 del administrador: Asociar la biblioteca de contenido y la clase de máquina virtual con el espacio de nombres de vSphere
| Tarea | Descripción |
|---|---|
| Asocie la biblioteca de contenido con el archivo OVA de Ubuntu para vGPU con el espacio de nombres de vSphere en el que aprovisionará el clúster TKGS. | Consulte Configurar un espacio de nombres de vSphere para las versiones de Tanzu Kubernetes. |
| Asocie la clase de máquina virtual personalizada con el perfil de vGPU con el espacio de nombres de vSphere en el que aprovisionará el clúster TKGS. | Consulte Asociar una clase de máquina virtual con un espacio de nombres en vSphere with Tanzu. |
Paso 10 del administrador: comprobar que se pueda acceder al clúster supervisor
La última tarea de administración consiste en comprobar que el clúster supervisor esté aprovisionado y disponible para que lo pueda utilizar el operador del clúster a fin de aprovisionar un clúster TKGS para cargas de trabajo de AI/ML.
- Descargue e instale las Herramientas de la CLI de Kubernetes para vSphere.
Consulte Descargar e instalar Herramientas de la CLI de Kubernetes para vSphere.
- Conéctese al clúster supervisor.
Consulte Conectarse al clúster supervisor como usuario vCenter Single Sign-On.
- Proporcione al operador de clúster el vínculo con el que puede descargar las Herramientas de la CLI de Kubernetes para vSphere y el nombre del espacio de nombres de vSphere.
