









クラスタは、共有リソースと共有管理インターフェイスを持つ複数の ESXi ホストとそれに関連する仮想マシンの集合体です。クラスタ レベルのリソース管理の利点を得る前に、クラスタを作成し、DRS を有効にする必要があります。
Enhanced vMotion Compatibility (EVC) が有効であるかどうかに応じて、クラスタ内の vSphere フォールト トレランス (vSphere FT) 仮想マシンを使用するときの DRS 動作は異なります。
| EVC | DRS (ロード バランシング) | DRS (初期配置) |
|---|---|---|
| 有効にする | 有効 (プライマリ仮想マシンとセカンダリ仮想マシン) | 有効 (プライマリ仮想マシンとセカンダリ仮想マシン) |
| 無効 | 無効 (プライマリ仮想マシンとセカンダリ仮想マシン) | 無効 (プライマリ仮想マシン) 完全自動化 (セカンダリ仮想マシン) |
アドミッション コントロールと初期配置
DRS が有効なクラスタ内の単一の仮想マシンまたは仮想マシンのグループをパワーオンする際、vCenter Server がアドミッション コントロールを実行します。アドミッション コントロールによって、クラスタ内に仮想マシンをサポートする十分なリソースがあるかどうかが確認されます。
単一の仮想マシン、または仮想マシン グループ内のいずれかの仮想マシンのパワーオンに十分なリソースがクラスタにない場合、メッセージが表示されます。十分なリソースがある場合、DRS は各仮想マシンを実行するホストの配置を推奨し、次のアクションのいずれかを行います。
- 配置の推奨を自動実行する。
- 配置の推奨を表示し、ユーザーは承諾するか変更するかを選択できる。
注: スタンドアロン ホストまたは非 DRS クラスタの仮想マシンには、初期配置の推奨は表示されません。パワーオン時に、現在格納されているホストに配置されます。
- DRS では、ネットワーク バンド幅が考慮されます。ホスト ネットワークの利用状況を計算することで、DRS は配置についてさらに適正な判断を下すことができます。これにより、環境をさらに包括的に把握し、仮想マシンのパフォーマンスの低下を回避できます。
1 台の仮想マシンのパワーオン
DRS クラスタで、単一仮想マシンをパワーオンし、初期配置の推奨を取得します。
単一仮想マシンをパワーオンする場合、2 種類の初期配置の推奨があります。
-
パワーオンに必要な前処理はなく、1 台の仮想マシンがパワーオンされる。
ユーザーには、相互に排他的な仮想マシンの初期配置の推奨のリストが表示されます。1 つだけを選択できます。
-
パワーオンに必要な前処理を行なってから、1 台の仮想マシンがパワーオンされる。
これらの操作には、スタンバイ モードのホストのパワーオン、別の仮想マシンのホスト間の移行が含まれます。この場合、推奨は複数行で表示され、必要な各操作が示されます。ユーザーは、この推奨全体を受け入れるか、仮想マシンのパワーオンをキャンセルできます。
グループ パワーオン
複数の仮想マシンを同時にパワーオンできます(グループ パワーオン)。
グループのパワーオンの試行に選択する仮想マシンは、同じ DRS クラスタにある必要はありません。クラスタをまたがって選択できますが、同じデータセンター内にある必要があります。また、DRS 以外のクラスタまたはスタンドアロン ホストにある仮想マシンを含めることもできます。これらの仮想マシンは自動的にパワーオンされますが、初期配置の推奨には含まれません。
グループ パワーオンの初期配置に関する推奨は、クラスタ単位で提供されます。グループのパワーオンの試行に関する配置関連のすべてのアクションが自動モードの場合、初期配置の推奨は表示されずに、仮想マシンがパワーオンされます。いずれかの仮想マシンの配置関連のアクションが手動モードである場合は、すべての仮想マシン(自動モードである仮想マシンを含む)のパワーオンは、手動で行われます。そのようなアクションは、初期配置の推奨に含まれています。
パワーオンする仮想マシンが属する DRS クラスタごとに、必要なすべての前提条件が含まれた単一の推奨が作成されます(または、推奨は作成されません)。このようなクラスタ固有の推奨は、[パワーオン推奨] タブの下にまとめて表示されます。
自動モードでないグループのパワーオンが試行され、初期配置に関する推奨の対象外である仮想マシン(スタンドアロン ホストまたは DRS 以外のクラスタにある仮想マシン)が含まれている場合、vCenter Server はこれらの仮想マシンを自動的にパワーオンしようとします。このパワーオンが成功すると、[パワーオン開始] タブの下に仮想マシンが一覧表示されます。パワーオンに失敗した仮想マシンは、[パワーオン失敗] タブに一覧表示されます。
グループ パワーオン
ユーザーは、グループのパワーオンを試行するために、同じデータセンターにある 3 台の仮想マシンを選択します。最初の 2 台の仮想マシン (VM1 と VM2) は、同じ DRS クラスタ (Cluster1) にあり、3 番目の仮想マシン (VM3) はスタンドアロン ホストにあります。VM1 は自動モードで、VM2 は手動モードです。このシナリオでは、VM1 と VM2 をパワーオンするアクションで構成された Cluster1 の初期配置の推奨が([パワーオン推奨 ] タブに)表示されます。VM3 のパワーオン試行は自動的に行われ、成功した場合、[パワーオン開始] タブに表示されます。この試行が失敗した場合は、[パワーオン失敗] タブに一覧表示されます。
仮想マシンの移行
DRS が初期配置を実行するため、クラスタ間の負荷は均衡になりますが、仮想マシンの負荷やリソースの可用性が変化すると、クラスタがアンバランスになります。このようなアンバランスを調整するには、DRS が移行の推奨を作成します。
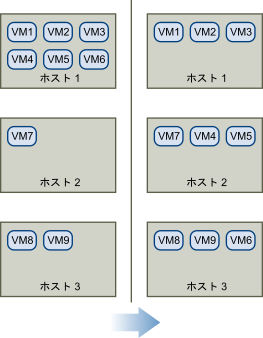
クラスタで DRS が有効な場合は、負荷をより均一に分散し、前述の不均衡を軽減できます。たとえば、この図の左側にある 3 台のホストは、不均衡です。ホスト 1、ホスト 2、ホスト 3 の容量が同一であり、すべての仮想マシンの構成と負荷 (予約が設定されている場合はそれも含む) が同じであるとします。しかし、ホスト 1 には 6 台の仮想マシンがあるので、ホスト 1 のリソースは使用過剰になる場合があるのに対し、ホスト 2 とホスト 3 では、使用可能なリソースが十分にあります。DRS は、仮想マシンをホスト 1 からホスト 2 とホスト 3 に移行します (または移行を推奨します)。図の右側に、適切にロード バランシングされたあとのホストの構成が表示されます。
クラスタが不均衡になった場合、DRS はデフォルトの自動化レベルに応じて、推奨を行うか仮想マシンを移行します。
- クラスタまたはいずれかの仮想マシンが手動または一部自動化の場合、vCenter Server はリソースのバランスをとるための自動的なアクションを実行しません。代わりに、移行の推奨が使用可能であることがサマリ ページに表示され、クラスタ内で最も効率的にリソースを使用できる変更の推奨が DRS 推奨ページに表示されます。
-
関連するクラスタおよび仮想マシンが完全自動化の場合、vCenter Server は、実行中の仮想マシンを必要に応じてホスト間で移行して、クラスタ リソースが効率的に使用できるようにします。
注: 自動移行設定であっても、ユーザーが個々の仮想マシンを明示的に移行できますが、 vCenter Server は、クラスタ リソースを最適化するためにそれらの仮想マシンをほかのホストに移動する場合があります。
デフォルトでは、自動化レベルはクラスタ全体に対して指定されます。個々の仮想マシンについてカスタム自動化レベルを指定することもできます。
DRS 移行のしきい値
DRS 移行のしきい値を使用すると、どの推奨を生成して適用するか (推奨に関与する仮想マシンが完全自動化モードの場合)、または表示するか (手動モードの場合) を指定できます。このしきい値は、仮想マシンの健全性を高めるために移行を推奨する上で、DRS の積極性をどの程度にするかを示す尺度です。
しきい値スライダを移動して、[保守的] から [積極的] までの 5 つの設定のうち、1 つを使用できます。積極性設定を高くすると、仮想マシンの健全性を高めるために DRS が移行を推奨する頻度が高くなります。[保守的] に設定すると、優先順位が最上位の推奨(必須の推奨)のみが生成されます。
推奨が優先順位レベルを取得したあと、そのレベルは設定した移行のしきい値と比較されます。優先順位レベルがしきい値の設定以下の場合、推奨が適用される (関連する仮想マシンが完全自動化モードの場合) か、ユーザーの確認のために表示されます (手動モードまたは一部自動化モードの場合)。
DRS スコア
個々の移行の推奨は、実行効率を測定する仮想マシン健全性メトリックを使用して計算されます。このメトリックは、vSphere Client にあるクラスタの [サマリ] タブに DRS スコアとして表示されます。DRS ロード バランシングの推奨は、仮想マシンの DRS スコアの改善を意図しています。クラスタの DRS スコアは、クラスタ内でパワーオンされているすべての仮想マシンの仮想マシン DRS スコアの加重平均です。クラスタの DRS スコアはゲージ コンポーネントに表示されます。値表示部分の色は、仮想マシンの DRS スコアのヒストグラムの対応するバーと一致するように変化します。ヒストグラムのバーには、DRS スコアがその範囲内に該当する仮想マシンの割合が表示されます。クラスタの [監視] タブを選択して [vSphere DRS] を選択すると、サーバ側でソートおよびフィルタリングしたリストを表示できます。これにより、クラスタ内の仮想マシンが DRS スコアの昇順にソートされて一覧表示されます。
移行の推奨
デフォルトが手動または一部自動化モードのクラスタを作成した場合、vCenter Server は DRS 推奨ページに移行の推奨を表示します。
システムは、ルールを実施してクラスタのリソースのバランスをとるのに必要なだけの推奨を行います。各推奨には、移動する仮想マシン、現在の (ソース) ホストとターゲット ホスト、および推奨の理由が含まれます。理由は次のいずれかです。
- CPU 負荷または予約を均衡化する。
- メモリ負荷または予約を均衡化する。
- リソース プールの予約に従う。
- アフィニティ ルールに従う。
- ホストがメンテナンス モードまたはスタンバイ モードに切り替えている最中である。
DRS クラスタの要件
クラスタ機能を正しく使用するには、DRS クラスタに追加するホストが、特定の要件を満たしている必要があります。
共有ストレージの要件
DRS クラスタには、一定の共有ストレージ要件があります。
管理対象ホストが共有ストレージを使用している必要があります。共有ストレージは、SAN 上にあるのが一般的ですが、NAS 共有ストレージを使用して実装することもできます。
他の共有ストレージの情報については、『vSphere のストレージ』ドキュメントを参照してください。
共有 VMFS ボリュームの要件
DRS クラスタには、一定の共有 VMFS ボリュームの要件があります。
共有 VMFS ボリュームを使用するように、すべての管理対象ホストを構成します。
- ソース ホストとターゲット ホストからアクセスできる VMFS ボリューム上に、全仮想マシンのディスクを設置します。
- VMFS ボリュームが、仮想マシンのすべての仮想ディスクを保存するのに十分なサイズであることを確認します。
- ソース ホストとターゲット ホスト上のすべての VMFS ボリュームがボリューム名を使用すること、およびすべての仮想マシンがそれらのボリューム名を使用して仮想ディスクを指定することを確認します。
.vmdk 仮想ディスクと同様に、ソース ホストとターゲット ホストがアクセスできる VMFS 上に配置される必要があります。 すべてのソース ホストとターゲット ホストが ESX Server 3.5 以降で、ホストのローカル スワップを使用している場合、この要件は適用されません。 この場合は、非共有ストレージのスワップ ファイルを使用する vMotion がサポートされます。 スワップ ファイルはデフォルトで VMFS 上に配置されますが、管理者は、仮想マシンの詳細構成オプションを使用してファイルの場所をオーバーライドできます。
プロセッサの互換性要件
DRS クラスタには、一定のプロセッサ互換性要件があります。
DRS の機能が制限されないようにするためには、クラスタ内のソース ホストとターゲット ホストのプロセッサの互換性を最大にする必要があります。
vMotion は、実行中の仮想マシンのアーキテクチャ状態を、基盤となる ESXi ホスト間で移行します。vMotion の互換性とは、ソース ホストのプロセッサのサスペンドに用いたのと同等の命令を使用して、ターゲット ホストのプロセッサが実行をレジュームできなければならないことを意味します。vMotion での移行に必要な互換性を保つためには、プロセッサのクロック速度とキャッシュ サイズは異なっていてもかまいませんが、プロセッサが同じクラスのベンダー (Intel と AMD) 製で、同じプロセッサ ファミリでなければなりません。
プロセッサ ファミリはプロセッサ ベンダーによって決められています。同じファミリ内の異なるプロセッサ バージョンは、プロセッサのモデル、ステッピング レベル、拡張機能を比較することで区別できます。
プロセッサ ベンダーが、同じプロセッサ ファミリ内で大幅なアーキテクチャ変更 (64 ビット拡張や SSE3 など) を行うことがあります。vMotion での正常な移行を保証できない場合、これらの例外を確認します。
vCenter Server には、vMotion で移行した仮想マシンがプロセッサの互換性要件を確実に満たすようにする機能が備わっています。これには、次の機能が含まれます。
- Enhanced vMotion Compatibility (EVC): EVC を使用して、クラスタ内のホストの vMotion 互換性を確保できます。ホスト上の実際の CPU が異なる場合でも、EVC によって 1 つのクラスタ内のすべてのホストが確実に同じ CPU 機能セットを仮想マシンに提供するようになります。これにより、互換性のない CPU が原因で vMotion での移行が失敗することがなくなります。
EVC は、クラスタ設定ダイアログ ボックスで構成します。クラスタで EVC を使用するためには、クラスタ内のホストが特定の要件を満たす必要があります。EVC および EVC の要件については、『vCenter Server およびホストの管理』 ドキュメントを参照してください。
- CPU 互換性マスク: vCenter Server は仮想マシンで使用できる CPU 機能をターゲット ホストの CPU 機能と比較して、vMotion での移行が可能かどうかを判断します。個々の仮想マシンに CPU 互換性マスクを適用することにより、特定の CPU 機能を仮想マシンから隠し、互換性のない CPU が原因で vMotion での移行が失敗する可能性を減らすことができます。
DRS クラスタの vMotion 要件
DRS クラスタには、一定の vMotion 要件があります。
DRS 移行の推奨を使用できるようにする場合は、クラスタ内のホストが vMotion ネットワークの一部である必要があります。 ホストが vMotion ネットワーク内にない場合でも、DRS は初期配置の推奨を行うことができます。
vMotion 用に構成するためには、クラスタ内の各ホストが次の要件を満たしている必要があります。
- vMotion は、Raw ディスク、または MSCS (Microsoft Cluster Service) でクラスタリングしたアプリケーションの移行をサポートしていません。
- vMotion では、vMotion に対応したすべての管理対象ホスト間に、プライベートなギガビット イーサネット移行ネットワークが必要です。 管理対象ホスト上で vMotion を有効にする場合は、管理対象ホストに固有のネットワーク ID オブジェクトを構成し、これをプライベートな移行用ネットワークに接続します。
仮想フラッシュによる DRS の構成
DRS は、仮想フラッシュ予約を持つ仮想マシンを管理できます。
仮想フラッシュ容量は、ホストからvSphere Clientに定期的に報告される統計情報として表されます。DRS が実行されるたびに、報告された最新の容量値が使用されます。
ホストあたり 1 つの仮想フラッシュ リソースを構成できます。そのため、仮想マシンがパワーオンになっている間、DRS は特定のホスト上のさまざまな仮想フラッシュ リソースの中から選択する必要がありません。
DRS は、仮想マシンの起動に十分な仮想フラッシュ容量のあるホストを選択します。DRS が仮想マシンの仮想フラッシュ予約を満たせない場合、パワーオンにすることはできません。DRS は、仮想フラッシュ予約のあるパワーオン状態の仮想マシンを、その現在のホストとソフト アフィニティがあるものとして扱います。DRS では vMotion にそのような仮想マシンを使用することは推奨されません。ただし、ホストをメンテナンス モードにしたり、過剰に使用されているホストの負荷を減らしたりするなどの強制的な理由がある場合はこの限りではありません。
クラスタの作成
クラスタとは、ホストのグループです。あるクラスタに 1 台のホストが追加されると、そのホストのリソースはそのクラスタのリソースの一部になります。クラスタは、そのクラスタ内のすべてのホストのリソースを管理します。
前提条件
- クラスタ オブジェクトの作成に必要な権限を持っていることを確認します。
- データセンターがインベントリに存在することを確認します。
- vSAN を使用する場合は、vSphere HA を構成する前に有効にする必要があります。
手順
結果
クラスタがインベントリに追加されます。
次のタスク
クラスタ設定の編集
ある DRS クラスタにホストを追加すると、ホストのリソースはクラスタのリソースの一部になります。このリソースの統合に加えて、DRS クラスタを使用すると、クラスタ全体にわたるリソース プールがサポートされ、リソース割り当てポリシーをクラスタ レベルで適用できます。
次のクラスタ レベルのリソース管理機能も使用できます。
- ロード バランシング
- クラスタ内にあるすべてのホストおよび仮想マシンの CPU およびメモリ リソースの配分と使用率を継続的に監視します。DRS は、これらのメトリックを、クラスタのリソース プールと仮想マシンの属性に設定された理想的なリソース使用率、現在の需要、および負荷が調整されていないホストと比較します。次に DRS は推奨を行い、それに応じて仮想マシン移行を実行します。 仮想マシンの移行を参照してください。クラスタ内で仮想マシンをパワーオンしたときに、DRS は仮想マシンを適切なホストに配置するか、推奨を提示して、適切なロード バランシングを維持しようとします。 アドミッション コントロールと初期配置を参照してください。
- 電源管理
- vSphere Distributed Power Management (DPM) の機能が有効になっている場合、DRS はクラスタ レベルおよびホスト レベルのキャパシティと、クラスタの仮想マシンに必要なキャパシティ(最近の需要履歴を含む)とを比較します。次に DRS は、ホストをスタンバイ状態にすることを推奨するか、または十分なキャパシティがあることがわかったなら、ホストをスタンバイ電源モードします。DRS は、キャパシティが必要になった場合にはホストをパワーオンします。ホストの電源状態に関する推奨に応じて、ホスト間で仮想マシンの移行が必要になる場合があります。 電力リソースの管理を参照してください。
- アフィニティ ルール
- アフィニティ ルールを割り当てることで、クラスタ内のホスト上の仮想マシンの配置を制御できます。 vSphere DRS を使用したアフィニティ ルールの使用を参照してください。
前提条件
手順
次のタスク
vSphere Client で、DRS のメモリ使用率を確認できます。詳細については、以下を参照してください:
仮想マシンのカスタム自動化レベルの設定
DRS クラスタを作成したあとで、個々の仮想マシンの自動化レベルをカスタマイズして、クラスタのデフォルト自動化レベルをオーバーライドできます。
たとえば、完全に自動化されたクラスタ内の特定の仮想マシンに対して [手動] を選択したり、手動のクラスタ内の特定の仮想マシンに対して [一部自動化] を選択したりできます。
仮想マシンを [無効] に設定すると、vCenter Server でその仮想マシンの移行や、移行に関する推奨を行うことがなくなります。
手順
結果
ほかの当社製品または機能 (vSphere vApp および vSphere Fault Tolerance など) が、DRS クラスタ内の仮想マシンの自動化レベルをオーバーライドする場合があります。詳細については、個別の製品ドキュメントを参照してください。
DRS の無効化
クラスタの DRS をオフにできます。
DRS を無効にした場合の動作は次のとおりです。
- DRS アフィニティ ルールは削除されませんが、DRS が再度有効になるまで適用されません。
- ホスト グループと仮想マシン グループは削除されませんが、DRS が再度有効になるまで適用されません。
- リソース プールはクラスタから完全に削除されます。リソース プールの消失を回避するには、リソース プール ツリーのスナップショットをローカル マシンに保存します。このスナップショットを使用すれば、DRS を有効にしたときに、リソース プールをリストアできます。
手順
- vSphere Client のクラスタを参照して移動します。
- [構成] タブをクリックし、[サービス] をクリックします。
- [vSphere DRS] の [編集] をクリックします。
- [vSphere DRS をオンにする] チェック ボックスを選択解除します。
- [OK] をクリックして DRS をオフにします。
- (オプション) リソース プールを保存するオプションを選択します。
- リソース プール ツリーをローカル マシンに保存する場合は、[はい] をクリックします。
- リソース プール ツリーのスナップショットを保存せずに、DRS をオフにする場合は、[いいえ] をクリックします。
結果
リソース プール ツリーのリストア
保存したリソース プール ツリーのスナップショットはリストアできます。
前提条件
- vSphere DRS はオンにする必要があります。
- スナップショットは、それを取得したクラスタだけにリストアできます。
- それ以外のリソース プールはクラスタにありません。
- バックアップとリストアは、常に同じバージョンの vCenter Server および ESXi で実行する必要があります。
手順
- vSphere Client のクラスタを参照して移動します。
- クラスタを右クリックし、[リソース プール ツリーのリストア] を選択します。
- [参照] をクリックし、ローカル マシンにスナップショット ファイルを格納した場所を選択します。
- [開く] をクリックします。
- [OK] をクリックして、リソース プール ツリーをリストアします。
vSAN ストレッチ クラスタの DRS 認識
DRS を有効にした場合は、ストレッチ クラスタで vSAN ストレッチ クラスタの DRS 認識機能を使用できます。vSAN ストレッチ クラスタには読み取りの局所性があり、仮想マシンはローカル サイトからデータを読み取ります。リモート サイトからデータを読み取ると、仮想マシンのパフォーマンスが影響を受ける可能性があります。vSAN ストレッチ クラスタの DRS 認識機能により、DRS は仮想マシンの読み取り局所性を完全に認識するようになったため、仮想マシンは読み取り局所性に完全に対応するサイトに配置されます。これは自動で行われます。構成可能なオプションはありません。vSAN ストレッチ クラスタの DRS 認識は、既存のアフィニティ ルールと連携します。また、VMware Cloud on AWS とも連携します。
vSphere HA および vSphere DRS を使用する vSAN ストレッチ クラスタでは、回復性を実現するために、2 つのフォルト ドメインに 2 つのデータ コピーを分散し、障害に備えて 3 番目のフォルト ドメインに監視ノードを配置します。2 つのアクティブなフォルト ドメインでデータのレプリケーションが提供されるため、両方のフォルト ドメインに現在のデータ コピーを保持できます。
vSAN ストレッチ クラスタには、2 つのフォルト ドメイン内でのワークロードの移動を自動化する方法が用意されています。サイト全体で障害が発生した場合、vSphere HA は仮想マシンをセカンダリ サイトで再起動します。これにより、重要な本番ワークロードのダウンタイムを確実に回避できます。プライマリ サイトがオンラインに戻ると、DRS は直ちに、ソフト アフィニティ ホストが配置されたプライマリ サイトに仮想マシンをリバランスします。このプロセスにより、仮想マシンは、仮想マシン データ コンポーネントがまだ再構築中である場合もセカンダリ サイトから読み取りおよび書き込みを行うため、仮想マシンのパフォーマンスが低下する可能性があります。
vSphere 7.0 U2 より前のリリースでは、プライマリ サイトへの再同期中に仮想マシンが移行されるのを回避するために、DRS を完全自動化モードから部分的な自動化モードに変更することを推奨します。再同期が完了した後にのみ、DRS を完全自動化に戻してください。
vSAN ストレッチ クラスタの DRS 認識機能では、vSAN ストレッチ クラスタの障害からリカバリするための読み取り局所性ソリューションが完全に自動化されています。読み取り局所性の情報は、仮想マシンが完全にアクセスできるホストを示します。DRS は、仮想マシンを vSAN ストレッチ クラスタのホストに配置するときに、この情報を使用します。サイト リカバリ フェーズ中も vSAN の再同期が進行している場合、DRS は仮想マシンがプライマリ サイトにフェイルバックするのを防止します。データ コンポーネントが完全な読み取り局所性を実現している場合、DRS は仮想マシンをプライマリ アフィニティ サイトに自動的に移行して戻します。これにより、サイト全体で障害が発生した場合に、DRS を完全自動モードで操作できます。
サイトの一部に障害が発生した場合に、許容される障害の数以上の数のデータ コンポーネントが失われたために仮想マシンの読み取り局所性が失われると、vSphere DRS は、読み取りバンド幅を大量に使用する仮想マシンを特定して、セカンダリ サイトにリバランスします。これにより、サイトの一部に障害が発生した場合に、読み取り負荷が高いワークロードを処理する仮想マシンの負担が軽減されることはありません。プライマリ サイトがオンラインに戻り、データ コンポーネントの再同期が完了すると、仮想マシンはアフィニティ サイトに戻されます。
vGPU の DRS 配置
DRS は、vGPU 仮想マシンをクラスタのホスト全体に分散します。
vGPU 仮想マシンは、幅優先方式でクラスタのホスト全体に分散されます。仮想マシンのフラクショナル vGPU プロファイル割り当てには、同種プロファイルの相互除外ルールが適用される場合があります。
- vGPU 仮想マシンを目的のホストに手動で移行して、未使用の物理 GPU キャパシティを空けます。
- クラスタ内のすべての vGPU 仮想マシンで同じ vGPU プロファイル構成を使用します。
- ホストの「GPU 統合」を有効にします。詳細については、「ホスト グラフィックの設定」を参照してください。
- DRS 自動化が有効な場合は、クラスタまたは仮想マシンを [一部自動化] モードにすることを検討してください。詳細については、「クラスタ設定の編集」を参照してください。
仮想マシンの DRS オーバーヘッド メモリ管理
vSphere 8.0 U3 DRS では、再構成中の仮想マシンのオーバーヘッド メモリ管理が強化されています。
VMware vSphere では、オーバーヘッド メモリとは、ESXi が仮想マシン (VM) の管理に使用するメモリの量を指します。このメモリは、ESXi がその機能を実行するために必要なものであり、仮想マシンに割り当てられるゲスト メモリとは別です。オーバーヘッド メモリの量は、仮想 CPU (vCPU) の数、仮想マシンに割り当てられるメモリの量、仮想マシンの構成とハードウェア バージョンなど、いくつかの要因によって異なります。vCPU が多くなり、メモリ割り当てが大きくなると、オーバーヘッド メモリの消費量が増加します。vSphere では、DRS は ESXi メモリ管理と連携して、仮想マシンのオーバーヘッド メモリの使用量を最適化します。DRS は仮想マシンのオーバーヘッド メモリ制限を設定してオーバーヘッド メモリを管理し、ESXi は制限内でオーバーヘッド メモリを使用できます。
VMware vSphere で仮想マシンを再構成すると、ESXi による仮想マシンの管理に必要なオーバーヘッド メモリが直接影響を受ける可能性があります。vCPU の数や割り当てられる RAM の量の変更、ネットワーク アダプタやディスク コントローラといった仮想ハードウェアの追加など、仮想マシンの構成を変更すると、オーバーヘッド メモリの要件が変化することがあります。たとえば、仮想マシン予約を 250 GB から 0 GB に再構成するには、約 25 MB のオーバーヘッド メモリ使用量が必要です。ESXi は、仮想ページと物理ページ間のページ テーブル マッピングを管理するために、25 MB の追加オーバーヘッド メモリを割り当てます。vSphere は、これらの変更を監視および管理します。ただし、以前の vSphere リリースは、これらのオーバーヘッド メモリの増加に対応するようにカスタマイズされていません。新たなオーバーヘッド メモリの増加がオーバーヘッド制限を超えると、再構成が失敗する可能性があります。
vSphere 8.0 U3 では、DRS は再構成前に仮想マシンのオーバーヘッド メモリ制限をプロアクティブに更新します。DRS は、仮想マシンのリソース仕様、I/O フィルタ、オーバーヘッド メモリに影響を与えるその他の要素など、さまざまな要因をチェックします。再構成後の仮想マシン仕様の更新によって、オーバーヘッド メモリの増加が予想される場合でも、DRS による新たなオーバーヘッド制限で対応できるため、仮想マシンのパフォーマンスと安定性が最適化されます。
DRS の強化されたオーバーヘッド メモリ管理は、仮想マシンの再構成前にオーバーヘッド メモリ制限をインテリジェントに管理するため、再構成の失敗を防ぐのに役立ちます。これにより、再構成エラーのリスクが大幅に軽減されます。このプロアクティブなアプローチにより、より信頼性の高いエクスペリエンスが確保されます。仮想マシンのパフォーマンスと安定性を最適化することで、特に重要な再構成の処理中に、仮想環境を中断することなく効率的に実行できます。この機能強化は、既存の vSphere 環境にシームレスに統合され、パフォーマンスと信頼性を向上させます。
