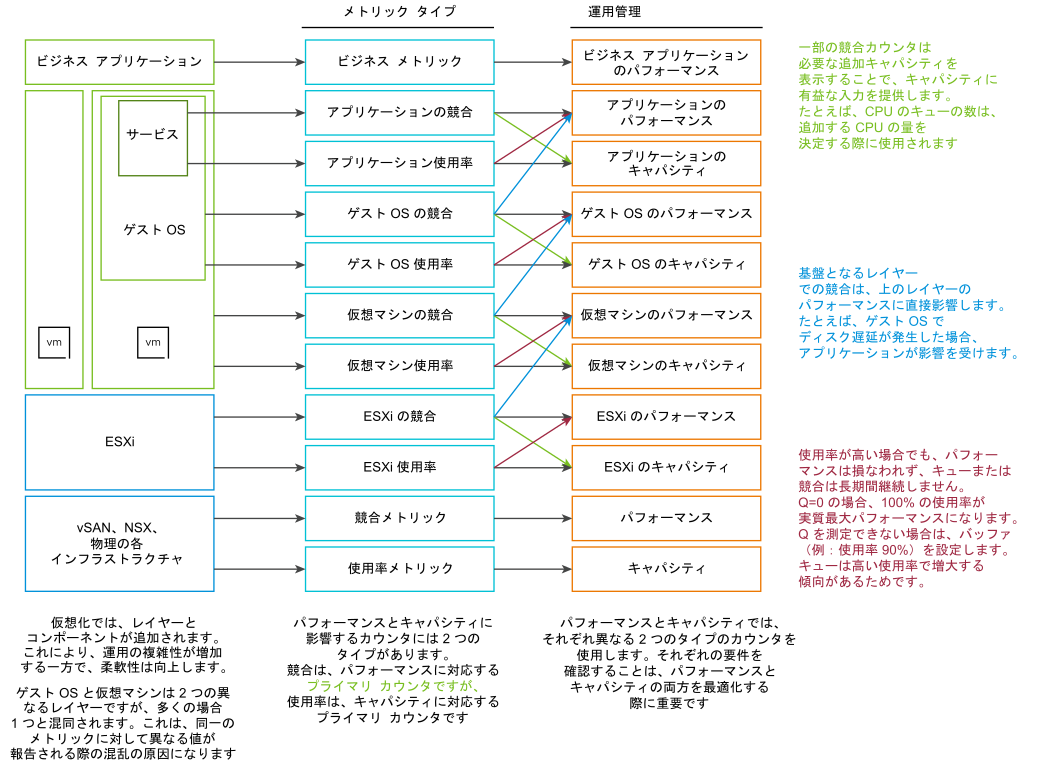
パフォーマンスとは、ワークロードが必要とするリソースを確保することであり、パフォーマンスの管理とは広く問題の排除を指します。方法としては、レイヤーへの切り分けを行い、各レイヤーにパフォーマンスの問題の原因があるかどうかを判別します。特定のレイヤーが適切に機能しているかどうかを示す単一のメトリックが必要不可欠になります。このプライマリ メトリックは、文字どおりキー パフォーマンス インジケータ (KPI) と呼ばれます。
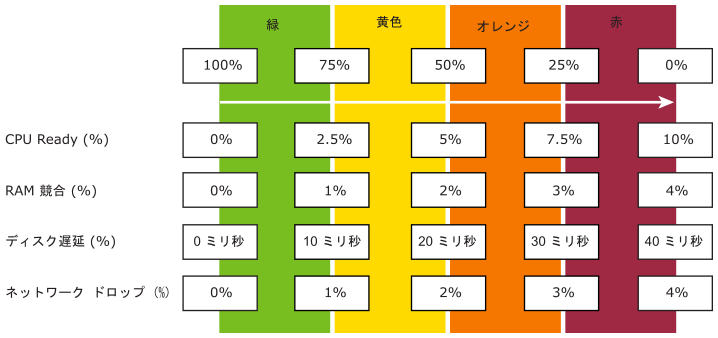
ディスク遅延などの各メトリックには、緑、黄、オレンジ、赤の 4 つの範囲が設定されています。
監視を容易にするために、この範囲は 0 ~ 100% にマッピングされています。緑は 75 ~ 100% に、赤は 0 ~25% にマッピングされています。100% を 4 つの均等な幅の範囲に分割することで、各範囲を適切なサイズに設定できます。
この方法により、異なる単位のメトリックを組み合わせることが可能になります。パーセンテージで表される同じ範囲にそれぞれがマッピングされます。
メトリックを 4 つの範囲に適切にマッピングするには、4 つではなく 5 つのメトリックが必要です。たとえば、ディスク遅延の場合は次のようになります。
-
41 ミリ秒は 0%(赤)になります。これは、赤色の上限が 40 ミリ秒であるためです。
-
35 ミリ秒は 12.5% になります。これは、30 ミリ秒と 40 ミリ秒の中間であるため、赤色になります。
-
30 ミリ秒は 25% になります。これは、赤色とオレンジ色の境界にあるためです。
各メトリックを 0 ~ 100% の範囲に変換すると、KPI メトリックを算出するために、ピーク値ではなく平均値が使用されます。平均値を使用するのは、いずれか 1 つのメトリックが KPI 値を大きく左右することを避けるためです。運用上重要なメトリックについては、アラートを使用することができます。平均値を使用すると、各メトリックが均等に考慮されるため、実際の状況が反映されます。
これらのダッシュボードは KPI を使用して、コンシューマ レイヤーでの Horizon セッションのパフォーマンスと、Horizon インフラストラクチャ レイヤーで集計されたワークロードのパフォーマンスを表示します。これらのダッシュボードは、Horizon アーキテクトまたはリード管理者向けに設計されています。Desktop as a Service (DaaS) のデータセンター部分の全体的なパフォーマンスを把握できます。
パフォーマンス管理の観点から見た Horizon
パフォーマンスの監視とトラブルシューティングの点で、Horizon は、クライアントが WAN ネットワークを介しているクライアント/サーバ アーキテクチャと似ています。ネットワークとデータセンターのコンポーネントは互いに独立しており、それぞれ異なるメトリック セットが使用され、単独のエンティティとして監視する必要があります。修正アクションも固有です。大規模企業では、ネットワークは独立したチームが所有しています。
そのため、Management Pack for Horizon も個別に監視して KPI を提供します。

パフォーマンス監視では、クライアント コンポーネントの監視の優先度は高くありません。クライアント コンポーネントはテレビと同様の動作をするためです。送信されたピクセルを表示し、単純な入力を受け付けるのみです。また、クライアントでの問題は一般的に切り分けが容易です。しかし、ネットワークとデータセンターの障害は多くのユーザーに影響を与えます。
パフォーマンスのトラブルシューティングの 3 つのプロセス
パフォーマンス管理には、次の 3 つの独立したプロセスがあります。
-
[計画]。ここでは、パフォーマンスの目標を設定します。この vSAN を設計する際、ディスク遅延を何ミリ秒と想定したでしょうか。(vSAN レベルではなく)仮想マシン レベルの測定値として 10 ミリ秒が妥当と考えられます。
-
[監視]。ここでは、計画と現実を比較します。アーキテクチャが提供する予定であったものと、現実のデータが一致しているでしょうか。一致していない場合は、修正する必要があります。
-
[トラブルシューティング]。これは、苦情に応じて行うのではなく、現実が計画よりも悪い場合に行います。トラブルシューティングに時間をかけないために、プロアクティブに実施することをお勧めします。

パフォーマンス管理の 2 つのメトリック
パフォーマンスを表す主なカウンタは競合です。多くのユーザーは使用率に注目します。これは、使用率が高いと何か問題が発生すると考えているためです。その何かとは競合です。競合は、さまざまな形で現れます。たとえば、キュー、遅延、ドロップ、中止、コンテキスト スイッチなどです。
使用率の指標がきわめて高いことと、パフォーマンスに問題があるかどうかは異なります。ESXi ホストでバルーニング、圧縮、スワップが発生していても、仮想マシンにメモリ パフォーマンスの問題が発生するとは限りません。ホストのパフォーマンスは、仮想マシンに対してどの程度のリソースを提供できるかによって測定されます。これは ESXi の使用率に関係していますが、パフォーマンス メトリックは使用率に基づいていません。競合のメトリックに基づいています。
クラスタ使用率が低いときでも、クラスタ内の仮想マシンのパフォーマンスが望ましい状態にならないことがあります。主な理由の 1 つとして、クラスタ使用率がプロバイダ レイヤー (ESXi) に着目しているのに対し、パフォーマンスが個々のコンシューマ(仮想マシン)に着目していることが挙げられます。

パフォーマンス管理の観点では、vSphere クラスタがリソースの最小論理構成要素です。リソース プールと仮想マシン ホストのアフィニティは、より小さなスライスを提供できますが、運用が複雑になるため、IaaS サービスの確実な品質をもたらすことはできません。リソース プールでは、サービス クラスを差別化して提供することはできません。たとえば、プレミアム デスクトップの料金はレギュラー デスクトップの 2 倍であるため、2 倍の速度が提供されると SLA で規定している場合などです。この場合、リソース プールでプレミアム デスクトップに 2 倍のシェアを割り当てることは可能です。この追加のシェアによって CPU 準備中の時間を半分にできるかどうかを前もって判断することはできません。
深さと広さ
プロアクティブな監視には、複数の視点からのインサイトが必要です。ユーザーがパフォーマンス上の問題に遭遇している場合は、次の点を確認します。
-
問題の程度はどのくらいか。これによって問題の深さを把握します。
-
影響を受けるユーザーの数はどのくらいか。これによって問題の広さを把握します。
2 つ目の質問への回答は、トラブルシューティングの進め方に影響します。その問題は範囲が限られているか、広範囲に及んでいるか。範囲が限られている場合は、影響を受けるオブジェクトに注目します。問題が広範囲に及ぶ場合は、影響を受けるオブジェクトの間で共有される共通領域(クラスタ、データストア、リソース プール、ホストなど)に注目します。

平均的なパフォーマンスについては質問していないことに注目してください。このケースの場合、平均では対応が遅れるためです。平均パフォーマンスが低下する頃には、全体の半分が影響を受けている可能性があります。
メンバー数が多い場合、Count() は Percentage() より有用です。たとえば、10 万ユーザーの VDI 環境で 5 人のユーザーが影響を受けている場合、これは 0.005% に過ぎません。現実の世界に置き換えて把握できるという意味で、カウント数を使用して監視する方が容易です。
全体的なフロー
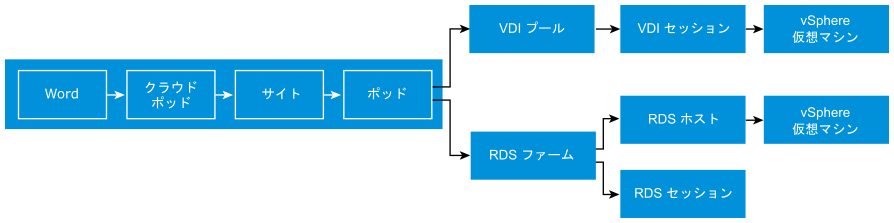
Management Pack for Horizon のダッシュボードは、それぞれが独立した設計にはなっていません。ドリルダウンするとフローが形成され、コンテキストが渡されます。次の例に、俯瞰的なビューから、セッションをサポートしている基盤の仮想マシンにドリルダウンする際の流れを示します。最初のダッシュボードは、Horizon ワールドのすべてのポッドを扱っています。そこから、RDS ファームと VDI プールのいずれかにドリルダウンできます。各ブランチ内で、個別のセッションにドリルダウンできます。
設計上の考慮事項
すべてのパフォーマンス ダッシュボードは、同じ設計原則を共有しています。これらのダッシュボードは、外観が異なると混乱の元になるため、類似の設計になっています。ダッシュボードの目的は共通です。
ダッシュボードは、サマリ セクションと詳細セクションがトップダウン形式で構成されています。
-
サマリ セクションは通常、ダッシュボードの一番上に配置されます。ここでは、全体像を把握できます。
-
詳細セクションはサマリ セクションの下に配置されます。ここから、特定のオブジェクトにドリルダウンすることができます。たとえば、仮想マシンのパフォーマンスに着目する場合は、特定の仮想マシンの詳細なパフォーマンスを知ることができます。
また、パフォーマンスのトラブルシューティングの際に複数のオブジェクトのパフォーマンスを確認できるように、この詳細セクションには、すばやい操作が可能なコンテキスト スイッチも組み込まれています。たとえば、RDS ホスト パフォーマンス ダッシュボードには、すべての RDS ホスト固有の情報が表示され、画面を変更することなく KPI を確認できます。1 つの RDS ホストから別の RDS ホストに移動して、複数のウィンドウを開くことなく詳細を表示できます。
ユーザー インターフェイスという点では、このダッシュボードは段階的表示を採用しているため、情報の過負荷を最小限に抑え、Web ページを迅速にロードできます。ブラウザ セッションのアクティブ状態が維持されている間は、最新の選択内容が保持されます。
意味を表す色
ダッシュボードでは、さまざまなしきい値が使用されているため、色を使用して意味を伝えます。
| カウンタ | 使用されているしきい値 |
|---|---|
| KPI | 緑:75% ~ 100% 黄:50% ~ 75% オレンジ:25% ~ 50% 赤:0% ~ 25% この場合、しきい値セットは 25%、50%、75% になります。 |
| 赤色のオブジェクトの数(赤色の KPI の VDI セッションの数など) |
KPI 値が赤色の範囲にある VDI セッションは許容されないため、これは常に 0 であることが求められます。そのため、しきい値セットは 1、2、および 3 になります。 カウントの値が 1 のときに赤色で表示されるようにするには、0.1、0.2、または 1 に設定します。 |
表示される数値は、緑色の範囲(75% ~ 100%)であることが求められます。平均値が 100% でなくても、緑色の範囲に入ることを目指します。
インサイトとしての表
表は単なるリストであり、各行が 1 つのオブジェクト、各列が 1 つの値を表します。この形式で数百の行が表示され、フィルタリングとソートが可能になります。各セルの値に色を設定することもできます。
表は詳細を表示するのに適しています。ただし、各セルの値は 1 つのみであるため、サマリの場合の主な問題として、時間の経過に伴うインサイトをどのようにして提供するかということがあります。過去に発生したことについてのインサイトを提供するにはどうすればよいでしょうか。たとえば、過去 1 週間のパフォーマンスを確認するにはどうすればよいでしょうか。過去 7 日間のデータポイントは数千個に達します。どれを選べばよいでしょうか。
VMware Aria Operations 8.2 には、いくつかの選択肢があります
-
現在の数。これは、現在の状況を示すのに役立ちます。ただし、5 分前に発生したことは表示されません。
-
期間の平均。平均は遅行指標です。平均が悪化する頃には、全体のおよそ 50% が不良になっている可能性があります。
-
期間のワースト。これは 1 つのピーク値のみを使用するため、非常に極端になる可能性があります。数百個のデータポイントのうち 1 つだけ外れ値が発生する場合もあります。ピークの検出には適していますが、補完する手段が必要です。
-
95 パーセンタイル。これは、平均とワーストの適切な中間点です。パフォーマンスの監視では、95 パーセンタイルは平均よりも優れたサマリになります。
ワーストと 95 パーセンタイルの両方を組み合わせて、95 パーセンタイルを先に表示します。2 つの数値の差が大きい場合は、ワーストが外れ値であることを示しています。
わかりやすくするために、98 パーセンタイルを追加して 95 パーセンタイルとワーストを補うことを検討してください。
インサイトとしての横棒グラフ
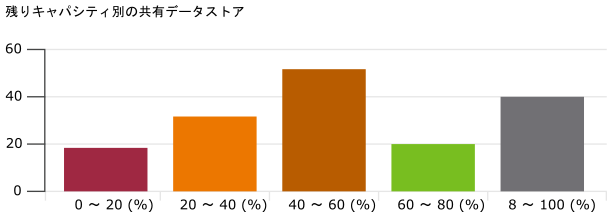
分布チャートには多くの形態があり、その中で横棒グラフが最も一般的です。これは、大きなデータセットに関するインサイトを提供するために使用できます。たとえば、vSphere 共有データストアにはそれぞれの残りキャパシティが表示されます。残りキャパシティが最小のものから最大のものまで、5 つのバケットに分類されます。各バケットには、意味を伝える色が割り当てられています。80% を超えるキャパシティはグレーで表示されます。未使用容量が多い場合はリソースの浪費を示しているためです。