









開発者が TKGS クラスタに AI/ML ワークロードをデプロイできるようにするには、vSphere 管理者が NVIDIA vGPU ハードウェアをサポートするように vSphere with Tanzu 環境を設定します。
TKGS クラスタへの AI/ML ワークロードのデプロイに関する vSphere 管理者ワークフロー
| 手順 | 操作 | リンク |
|---|---|---|
| 0 | システム要件を確認します。 |
管理者の手順 0:システム要件を確認するを参照してください。 |
| 1 | サポートされている NVIDIA GPU デバイスを ESXi ホストにインストールします。 |
管理者の手順 1:サポートされている NVIDIA GPU デバイスを ESXi ホストにインストールするを参照してください。 |
| 2 | vGPU を操作するための ESXi デバイス グラフィック設定を構成します。 |
管理者の手順 2:各 ESXi ホストを vGPU 操作用に構成するを参照してください。 |
| 3 | NVIDIA vGPU Manager (VIB) を各 ESXi ホストにインストールします。 |
管理者の手順 3:各 ESXi ホストに NVIDIA ホスト マネージャ ドライバをインストールするを参照してください。 |
| 4 | NVIDIA ドライバの動作と GPU 仮想化モードを確認します。 |
|
| 5 | GPU が構成されたクラスタでワークロード管理を有効にします。これにより、vGPU 対応の ESXi ホストでスーパーバイザー クラスタが実行されるようになります。 |
管理者の手順 5:vGPU が構成された vCenter Server クラスタでワークロード管理を有効にするを参照してください。 |
| 6 | Tanzu Kubernetes リリース用のコンテンツ ライブラリを作成*または更新し、vGPU ワークロードに必要なサポート対象の Ubuntu OVA をライブラリにポピュレートします。 |
管理者の手順 6:Tanzu Kubernetes Ubuntu リリースを含むコンテンツ ライブラリを作成または更新するを参照してください。
注: *必要に応じて行います。TKGS クラスタの Photon イメージ用のコンテンツ ライブラリがすでにある場合は、Ubuntu イメージ用の新しいコンテンツ ライブラリを作成しないでください。
|
| 7 | 特定の vGPU プロファイルが選択されたカスタムの仮想マシン クラスを作成します。 |
|
| 8 | TKGS GPU クラスタ用の vSphere 名前空間を作成して構成します。パーシステント ボリュームの編集権限とストレージを持つユーザーを追加します。 |
|
| 9 | Ubuntu OVA および vGPU 用のカスタム仮想マシン クラスが含まれているコンテンツ ライブラリを、TGKS 用に作成した vSphere 名前空間に関連付けます。 |
|
| 10 | スーパーバイザー クラスタがプロビジョニングされ、クラスタ オペレータがアクセスできることを確認します。 |
管理者の手順 0:システム要件を確認する
| 要件 | 説明 |
|---|---|
| vSphere インフラストラクチャ |
vSphere 7 Update3 Monthly Patch 1 ESXi ビルド vCenter Server ビルド |
| ワークロード管理 |
vSphere 名前空間のバージョン
|
| スーパーバイザー クラスタ |
スーパーバイザー クラスタ のバージョン
|
| TKR Ubuntu OVA | Tanzu Kubernetes リリース Ubuntu
|
| NVIDIA vGPU ホスト ドライバ |
NGC Web サイトから VIB をダウンロードします。詳細については、vGPU ソフトウェア ドライバのドキュメントを参照してください。例:
|
| vGPU の NVIDIA ライセンス サーバ |
組織から提供された FQDN |
管理者の手順 1:サポートされている NVIDIA GPU デバイスを ESXi ホストにインストールする
TKGS に AI/ML ワークロードをデプロイするには、[ワークロード管理] を有効にする vCenter Server クラスタ内の各 ESXi ホストに、サポートされている NVIDIA GPU デバイスを 1 つ以上インストールします。
互換性のある NVIDIA GPU デバイスを表示するには、VMware 互換性ガイドを参照してください。
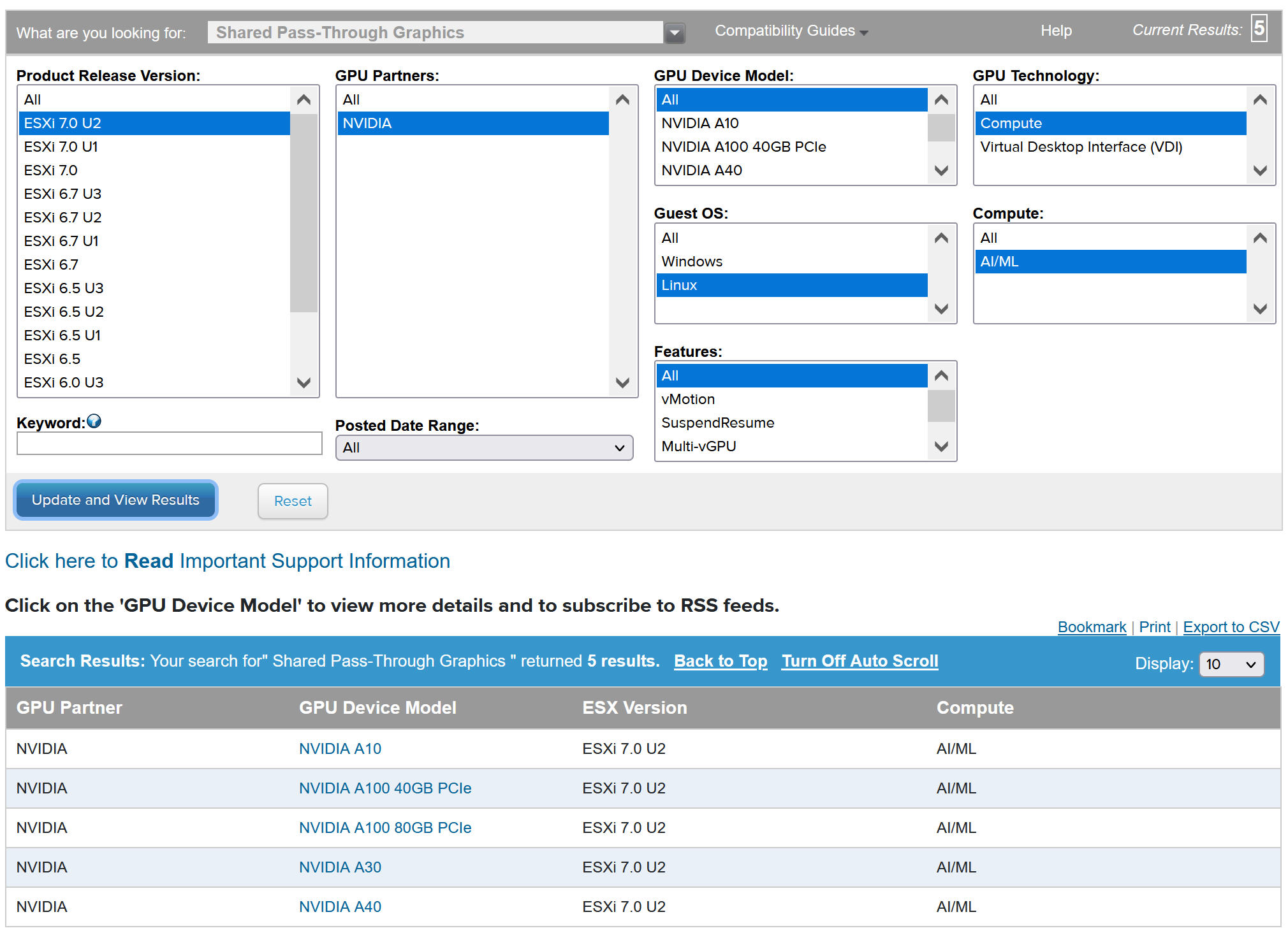
NVIDA GPU デバイスは、最新の NVIDIA AI Enterprise (NVAIE) vGPU プロファイルをサポートしている必要があります。ガイダンスについては、NVIDIA Virtual GPU Software Supported GPUsドキュメントを参照してください。
たとえば、次の ESXi ホストには、2 つの NVIDIA GPU A100 デバイスがインストールされています。
![vSphere Client の [グラフィック デバイス] タブに NVIDIA GPU A100 デバイスが一覧表示されます。](images/GUID-9F07693E-0109-4456-B0A6-3D9D1BA404D4-high.jpg)
管理者の手順 2:各 ESXi ホストを vGPU 操作用に構成する
[直接共有] および [SR-IOV] を有効にして、各 ESXi ホストを vGPU 用に構成します。
[各 ESXi ホストでの直接共有の有効化]
NVIDIA vGPU 機能をロック解除するには、[ワークロード管理] を有効にする vCenter Server クラスタ内の各 ESXi ホストで [直接共有] モードを有効にします。
- vSphere Client を使用して、vCenter Server にログインします。
- vCenter Server クラスタで ESXi ホストを選択します。
- の順に選択します。
- NVIDIA GPU アクセラレータ デバイスを選択します。
- グラフィック デバイスの設定を [編集] します。
- [直接共有] を選択します。
- [[X.Org Server を再起動]] を選択します。
- [OK] をクリックして構成を保存します。
- ESXi ホストを右クリックして、メンテナンス モードにします。
- ホストを再起動します。
- ホストが再実行されているときに、メンテナンス モードを終了します。
- [ワークロード管理] を有効にする vCenter Server クラスタ内の ESXi ホストごとにこのプロセスを繰り返します。
![[グラフィック デバイス設定の編集] 画面。[直接共有] オプションと [X.Org Server を再起動] オプションが選択されています。](images/GUID-D3A546A5-7242-4515-A31A-A714BB93782E-high.jpg)
![vSphere Client の [グラフィック デバイス] タブに、直接共有モードが有効な NVIDIA GPU A100 デバイスが一覧表示されます。](images/GUID-58CC6EEB-4538-48FB-B5C0-D1A98EF925A8-high.jpg)
[NVIDIA GPU A30 デバイスおよび A100 デバイスの SR-IOV BIOS の有効化]
マルチインスタンス GPU(MIG モード)で必要となる NVIDIA A30 デバイスまたは A100 GPU デバイスを使用している場合は、ESXi ホストで SR-IOV を有効にする必要があります。SR-IOV が有効になっていない場合は、Tanzu Kubernetes クラスタ ノード仮想マシンを起動できません。この問題が発生すると、[ワークロード管理] が有効になっている vCenter Server の [最近のタスク] ペインに次のエラー メッセージが表示されます。
Could not initialize plugin libnvidia-vgx.so for vGPU nvidia_aXXX-xx. Failed to start the virtual machine. Module DevicePowerOn power on failed.
SR-IOV を有効にするには、Web コンソールを使用して ESXi ホストにログインします。 の順に選択します。NVIDIA GPU デバイスを選択して、[SR-IOV の構成] をクリックします。ここで SR-IOV をオンにできます。その他のガイダンスについては、vSphere ドキュメントのSingle Root I/O Virtualization (SR-IOV)を参照してください。
管理者の手順 3:各 ESXi ホストに NVIDIA ホスト マネージャ ドライバをインストールする
NVIDIA vGPU グラフィック アクセラレーションを使用して Tanzu Kubernetes クラスタ ノード仮想マシンを実行するには、[ワークロード管理] を有効にする vCenter Server クラスタ内の各 ESXi ホストに NVIDIA ホスト マネージャ ドライバをインストールします。
NVIDIA vGPU ホスト マネージャ ドライバのコンポーネントは、vSphere インストール バンドル (VIB) に含まれています。NVAIE VIB は、NVIDIA GRID ライセンス プログラムを通じて組織から提供されます。VMware は NVAIE VIB を提供することも、ダウンロード可能にすることもしません。NVIDIA ライセンス プログラムの一環として、ユーザーの組織がライセンス サーバを設定します。詳細については、NVIDIA 仮想 GPU ソフトウェア クイック スタート ガイドを参照してください。
esxcli system maintenanceMode set --enable true esxcli software vib install -v ftp://server.domain.example.com/nvidia/signed/NVIDIA_bootbank_NVIDIA-VMware_ESXi_7.0_Host_Driver_460.73.02-1OEM.700.0.0.15525992.vib esxcli system maintenanceMode set --enable false /etc/init.d/xorg restart
管理者の手順 4:ESXi ホストで NVIDIA vGPU 操作の準備ができていることを確認する
- ESXi ホストに SSH 接続を行い、シェル モードに切り替えて、コマンド
nvidia-smiを実行します。NVIDIA システム管理インターフェイスは、NVIDA vGPU ホスト マネージャから提供されるコマンド ライン ユーティリティです。このコマンドを実行すると、ホスト上の GPU とドライバが返されます。 - 次のコマンドを実行して、NVIDIA ドライバが適切にインストールされていることを確認します。
esxcli software vib list | grep NVIDA - ホストに GPU の直接共有が構成され、SR-IOV がオンになっていることを確認します(NVIDIA A30 デバイスまたは A100 デバイスを使用している場合)。
- vSphere Client を使用して、GPU 用に構成されている ESXi ホストに PCI デバイスを含む新しい仮想マシンを作成します。NVIDIA vGPU プロファイルが表示されて、選択可能になります。
![[ハードウェアのカスタマイズ] タブ。NVIDIA vGPU プロファイルが選択されています。](images/GUID-FDD9B658-B177-49D0-B9D3-A18FFF3D1116-high.jpg)
管理者の手順 5:vGPU が構成された vCenter Server クラスタでワークロード管理を有効にする
NVIDIA vGPU をサポートするように ESXi ホストを構成しました。これらのホストで構成される vCenter Server クラスタを作成します。[ワークロード管理] をサポートするには、vCenter Server クラスタが共有ストレージ、高可用性、完全自動化 DRS などの特定の要件を満たしている必要があります。
[ワークロード管理] を有効にするには、ネイティブ vSphere vDS ネットワークまたは NSX-T Data Center ネットワークのいずれかのネットワーク スタックを選択する必要もあります。Distributed Switch ネットワークを使用する場合は、ロード バランサとして NSX Advanced または HAProxy NSX のいずれかをインストールする必要があります。
| タスク | 方法 |
|---|---|
| [ワークロード管理] を有効にするための要件を満たす vCenter Server クラスタを作成します | vSphere クラスタで vSphere with Tanzu を構成するための前提条件 |
| スーパーバイザー クラスタ のネットワーク(NSX-T または Distributed Switch)にロード バランサを構成します。 | vSphere with Tanzu 用 NSX-T Data Center の構成。 vSphere ネットワークと vSphere with Tanzu 用 NSX Advanced Load Balancer の構成。 |
| [ワークロード管理] を有効にします。 |
管理者の手順 6:Tanzu Kubernetes Ubuntu リリースを含むコンテンツ ライブラリを作成または更新する
NVIDIA vGPU には Ubuntu オペレーティング システムが必要です。VMware は、このような目的に使用する Ubuntu OVA を提供しています。vGPU クラスタに PhotonOS Tanzu Kubernetes リリースを使用することはできません。
| コンテンツ ライブラリ タイプ | 説明 |
|---|---|
| [サブスクライブ済みコンテンツ ライブラリ] を作成して、Ubuntu OVA を使用環境と自動的に同期します。 | Tanzu Kubernetes リリース のサブスクライブ済みコンテンツ ライブラリの作成、セキュリティ保護、同期 |
| [ローカル コンテンツ ライブラリ] を作成して、Ubuntu OVA を使用環境に手動でアップロードします。 | Tanzu Kubernetes リリース 用のローカル コンテンツ ライブラリの作成、セキュリティ保護、同期 |
![Ubuntu の [OVF & OVA テンプレート] 画面には、コンテンツ ライブラリで使用可能な Ubuntu OVA が表示されます。](images/GUID-042D9891-0A32-40A7-A213-1D183CAB6315-high.jpg)
管理者の手順 7:vGPU プロファイルを使用するカスタム仮想マシン クラスを作成する
次の手順では、vGPU プロファイルを使用するカスタム仮想マシン クラスを作成します。Tanzu Kubernetes クラスタ ノードが作成されるときに、このクラス定義が使用されます。
- vSphere Client を使用して、vCenter Server にログインします。
- [ワークロード管理] を選択します。
- [[サービス]] を選択します。
- [仮想マシン クラス] を選択します。
- [仮想マシン クラスの作成] をクリックします。
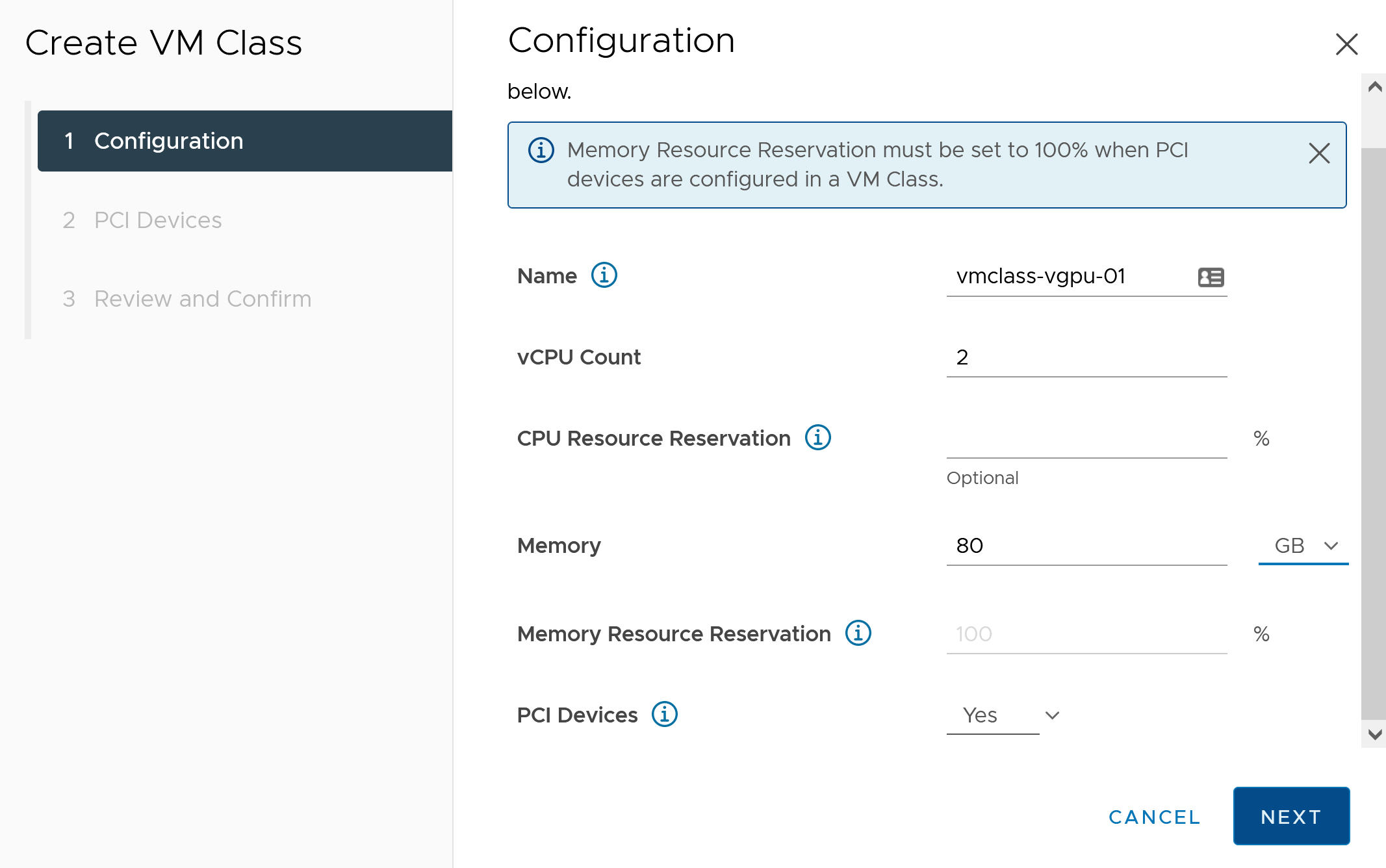
- [構成] タブで、カスタム仮想マシン クラスを構成します。
構成フィールド 説明 [名前] カスタム仮想マシン クラスのわかりやすい名前を入力します(vmclass-vgpu-1 など)。 [vCPU の数] 2 [CPU リソース予約] オプション。空白のままにする場合は [OK] をクリックします。 [メモリ] 80 [GB] など [メモリ リソース予約] [100%](仮想マシン クラスで PCI デバイスが構成されている場合は必須) [PCI デバイス] [はい] 注: PCI デバイスに対して [はい] を選択すると、GPU デバイスを使用していることがシステムに通知され、vGPU 構成をサポートするように仮想マシン クラスの構成が変更されます。例:
- [次へ] をクリックします。
- [PCI デバイス] タブで オプションを選択します。
- NVIDIA vGPU モデルを構成します。
NVIDIA vGPU フィールド 説明 [モデル] メニューで使用可能なモデルの中から、NVIDIA GPU ハードウェア デバイス モデルを選択します。プロファイルが表示されない場合は、クラスタ内のどのホストも PCI デバイスをサポートしていません。 [GPU 共有] この設定は、GPU 対応の仮想マシン間における GPU デバイスの共有方法を定義します。vGPU の実装には、[時刻の共有] と [マルチインスタンス GPU 共有]の 2 種類があります。
時刻の共有モードの場合、vGPU スケジューラは vGPU 間でパフォーマンスを調整するというベスト エフォート型の目標に従い、vGPU 対応の各仮想マシンの作業を一定期間、順番に実行するように GPU に指示します。
MIG モードの場合は、単一の GPU デバイスで複数の vGPU 対応仮想マシンを並列に実行できます。MIG モードは新しい GPU アーキテクチャに基づいていて、NVIDIA A100 デバイスおよび A30 デバイスでのみサポートされます。MIG オプションが表示されない場合、選択した PCI デバイスではサポートされていません。
[GPU モード] [コンピューティング] [GPU メモリ] 8 [GB] など [vGPU の数] [1] など たとえば、時刻の共有モードで構成された NVIDIA vGPU プロファイルを次に示します。
![[PCI デバイス] タブ。時刻の共有モードで構成した NVIDIA vGPU プロファイルが表示されています。](images/GUID-26039367-9949-4881-A354-8BC21EA341F5-high.jpg)
たとえば、サポートされている GPU デバイスを使用して MIG モードで構成された NVIDIA vGPU プロファイルを次に示します。
![[PCI デバイス] タブ。マルチインスタンス GPU 共有モードで構成した NVIDIA vGPU プロファイルが表示されています。](images/GUID-3D1D77DF-F588-4B04-8F91-78BACB93CFD9-high.jpg)
- [次へ] をクリックします。
- 選択内容を確認します。
- [終了] をクリックします。
- 新しいカスタム仮想マシン クラスが仮想マシン クラスのリストで使用可能になっていることを確認します。
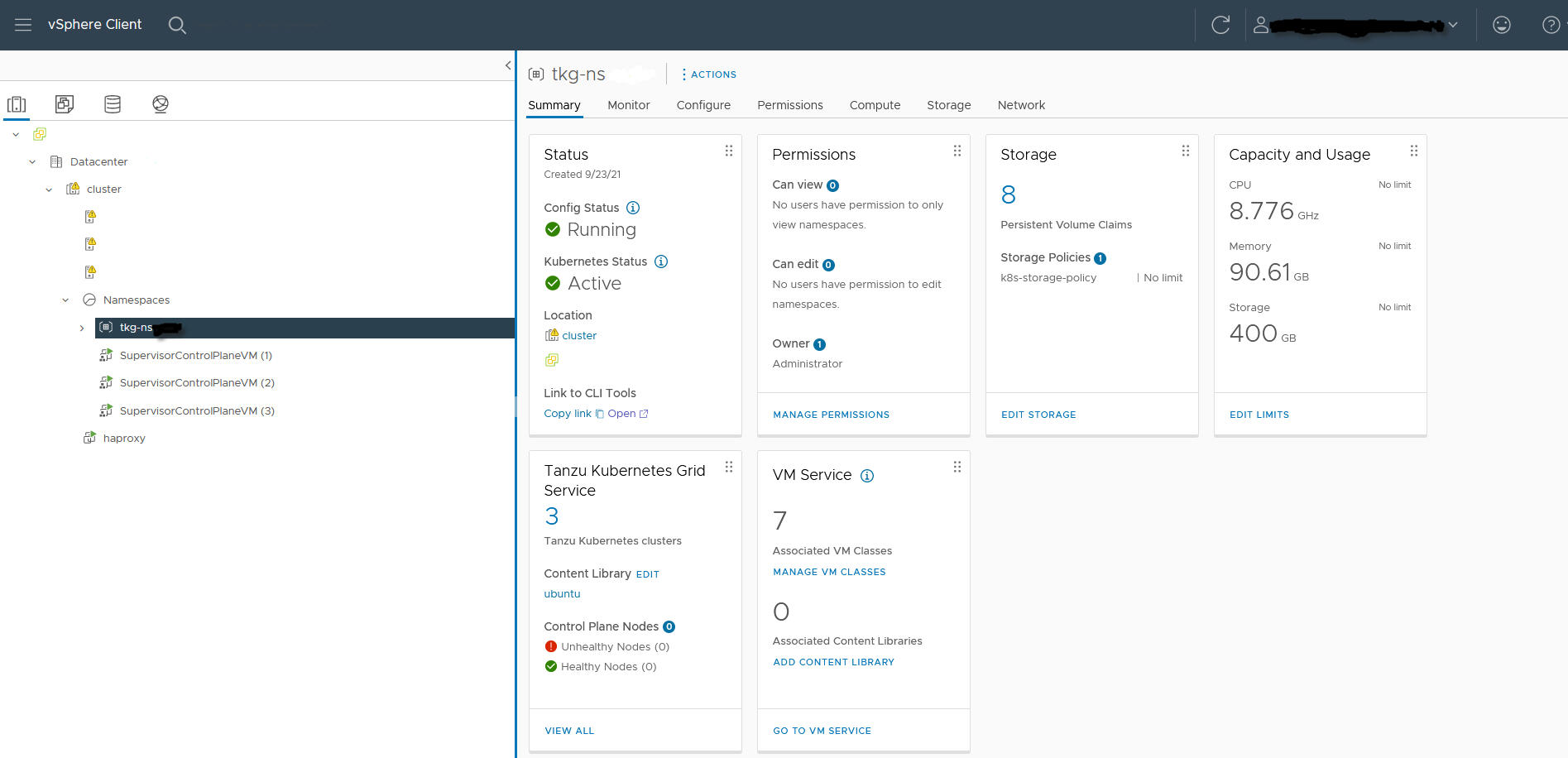
管理者の手順 8:TKGS GPU クラスタの vSphere 名前空間を作成して構成する
プロビジョニングする TKGS GPU クラスタごとに、vSphere 名前空間を作成します。編集権限を持つ vSphere SSO ユーザーを追加して名前空間を構成し、パーシステント ボリュームにストレージ ポリシーを適用します。
この操作を行うには、vSphere 名前空間 の作成と設定を参照してください。
管理者の手順 9:コンテンツ ライブラリと仮想マシン クラスを vSphere 名前空間に関連付ける
| タスク | 説明 |
|---|---|
| vGPU 用の Ubuntu OVA が含まれているコンテンツ ライブラリを、TKGS クラスタをプロビジョニングする vSphere 名前空間に関連付けます。 | |
| vGPU プロファイルを使用するカスタム仮想マシン クラスを、TKGS クラスタをプロビジョニングする vSphere 名前空間に関連付けます。 | 仮想マシン クラスと vSphere with Tanzu の名前空間の関連付けを参照してください。 |
管理者の手順 10:スーパーバイザー クラスタにアクセスできることを確認する
最後の管理タスクでは、スーパーバイザー クラスタ がプロビジョニングされ、クラスタ オペレータが AI/ML ワークロード用の TKGS クラスタをプロビジョニングする際に使用できることを確認します。
- vSphere 向け Kubernetes CLI Tools をダウンロードしてインストールします。
- スーパーバイザー クラスタ に接続します。
vCenter Single Sign-On ユーザーとして スーパーバイザー クラスタ に接続するを参照してください。
- vSphere 向け Kubernetes CLI Tools をダウンロードするためのリンクと vSphere 名前空間の名前をクラスタ オペレータに提供します。
TKGS クラスタへの AI/ML ワークロードのデプロイに関するクラスタ オペレータのワークフローを参照してください。
