









Damit Entwickler KI-/ML-Arbeitslasten auf TKGS-Clustern bereitstellen können, richten Sie als vSphere-Administrator die vSphere with Tanzu-Umgebung zur Unterstützung der NVIDIA GPU-Hardware ein.
vSphere-Administrator-Workflow für die Bereitstellung von KI-/ML-Arbeitslasten auf TKGS-Clustern
| Schritt | Aktion | Verknüpfen |
|---|---|---|
| 0 | Überprüfen der Systemanforderungen. |
Weitere Informationen finden Sie unter Schritt 0 für Administratoren: Überprüfen der Systemanforderungen. |
| 1 | Installieren des unterstützten NVIDIA GPU-Geräts auf ESXi-Hosts. |
Weitere Informationen finden Sie unter Schritt 1 für Administratoren: Installieren des unterstützten NVIDIA GPU-Geräts auf ESXi-Hosts. |
| 2 | Konfigurieren der Grafikeinstellungen des ESXi-Geräts für vGPU-Vorgänge. |
Weitere Informationen finden Sie unter Schritt 2 für Administratoren: Konfigurieren aller ESXi-Hosts für vGPU-Vorgänge. |
| 3 | Installieren des NVIDIA vGPU-Managers (VIB) auf allen ESXi-Hosts. |
Weitere Informationen finden Sie unter Schritt 3 für Administratoren: Installieren des Treibers für den NVIDIA-Hostmanager auf allen ESXi-Hosts. |
| 4 | Überprüfen des NVIDIA-Treibervorgangs und GPU-Virtualisierungsmodus. |
Weitere Informationen finden Sie unter Schritt 4 für Administratoren: Sicherstellen, dass ESXi-Hosts für NVIDIA vGPU-Vorgänge zur Verfügung stehen. |
| 5 | Aktivieren der Arbeitslastverwaltung auf dem für GPU konfigurierten Cluster. Das Ergebnis ist ein Supervisor-Cluster, der auf vGPU-fähigen ESXi-Hosts ausgeführt wird. |
Weitere Informationen finden Sie unter Schritt 5 für Administratoren: Aktivieren der Arbeitslastverwaltung auf dem für vGPU konfigurierten vCenter-Cluster. |
| 6 | Erstellen* oder Aktualisieren einer Inhaltsbibliothek für Tanzu Kubernetes-Versionen und Befüllen der Bibliothek mit der unterstützten Ubuntu-OVA, die für vGPU-Arbeitslasten erforderlich ist. |
Weitere Informationen finden Sie unter
Schritt 6 für Administratoren: Erstellen oder Aktualisieren einer Inhaltsbibliothek mit der Tanzu Kubernetes Ubuntu-Version.
Hinweis: *Falls erforderlich. Wenn Sie bereits über eine Inhaltsbibliothek für Photon-Images des TKGS-Clusters verfügen, erstellen Sie keine neue Inhaltsbibliothek für Ubuntu-Images.
|
| 7 | Erstellen einer benutzerdefinierte VM-Klasse mit einem bestimmten ausgewählten vGPU-Profil. |
Siehe Schritt 7 für Administratoren: Erstellen einer benutzerdefinierten VM-Klasse mit dem vGPU-Profil. |
| 8 | Erstellen und Konfigurieren eines vSphere-Namespace für TKGS GPU-Cluster: Hinzufügen eines Benutzers mit Bearbeitungsberechtigungen und Speicher für dauerhafte Volumes. |
|
| 9 | Verknüpfen der Inhaltsbibliothek mit der Ubuntu-OVA und der benutzerdefinierten VM-Klasse für vGPU mit dem für TGKS erstellten vSphere-Namespace. |
|
| 10 | Sicherstellen, dass der Supervisor-Cluster bereitgestellt wurde und für den Cluster-Operator zugänglich ist. |
Siehe Schritt 10 für Administratoren: Sicherstellen, dass Zugriff auf den Supervisor-Cluster besteht. |
Schritt 0 für Administratoren: Überprüfen der Systemanforderungen
| Anforderung | Beschreibung |
|---|---|
| vSphere-Infrastruktur |
vSphere 7 Update3 Monatlicher Patch 1 ESXi-Build vCenter Server-Build |
| Arbeitslastverwaltung |
Version des vSphere-Namespace
|
| Supervisor-Cluster |
Supervisor-Cluster-Version
|
| TKR Ubuntu-OVA | Tanzu Kubernetes-Version Ubuntu
|
| NVIDIA vGPU-Hosttreiber |
Laden Sie das VIB von der NGC-Website herunter. Weitere Informationen finden Sie in der Dokumentation des vGPU Software-Treibers. Beispiel:
|
| NVIDIA-Lizenzserver für vGPU |
Von Ihrer Organisation bereitgestellter FQDN |
Schritt 1 für Administratoren: Installieren des unterstützten NVIDIA GPU-Geräts auf ESXi-Hosts
Zur Bereitstellung von KI-/ML-Arbeitslasten auf TKGS installieren Sie mindestens ein unterstütztes NVIDIA GPU-Gerät auf allen ESXi-Hosts, aus denen sich der vCenter-Cluster zusammensetzt, auf dem Arbeitslastverwaltung aktiviert wird.
Informationen zum Anzeigen kompatibler NVIDIA GPU-Geräte finden Sie im VMware-Kompatibilitätshandbuch.
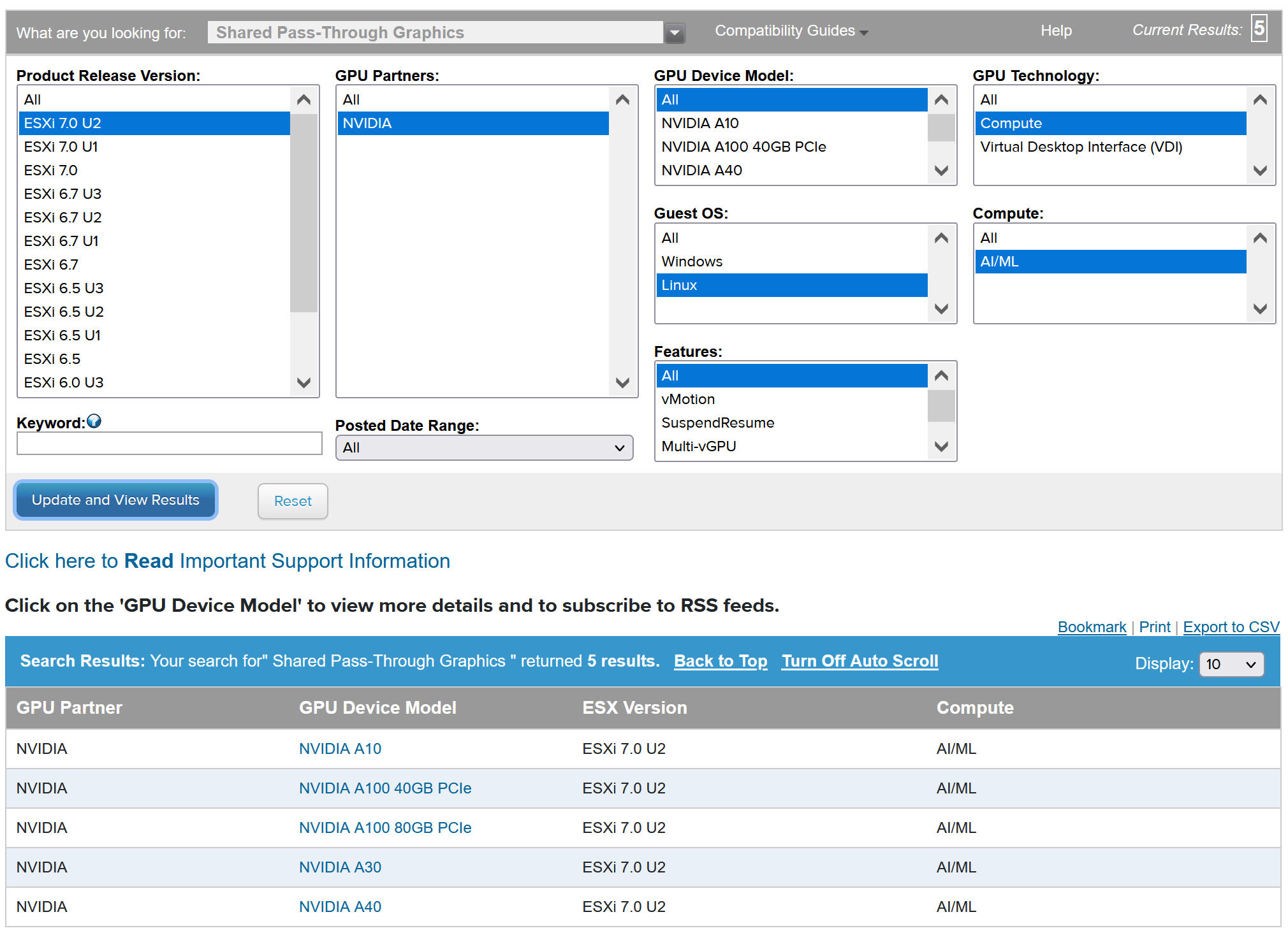
Das NVIDIA GPU-Gerät sollte die aktuellen vGPU-Profile von NVIDIA AI Enterprise (NVAIE) unterstützen. Weitere Informationen finden Sie in der Dokumentation Von der NVIDIA Virtual GPU-Software unterstützte GPUs.
Auf dem folgenden ESXi-Host sind beispielsweise zwei NVIDIA GPU A100-Geräte installiert.
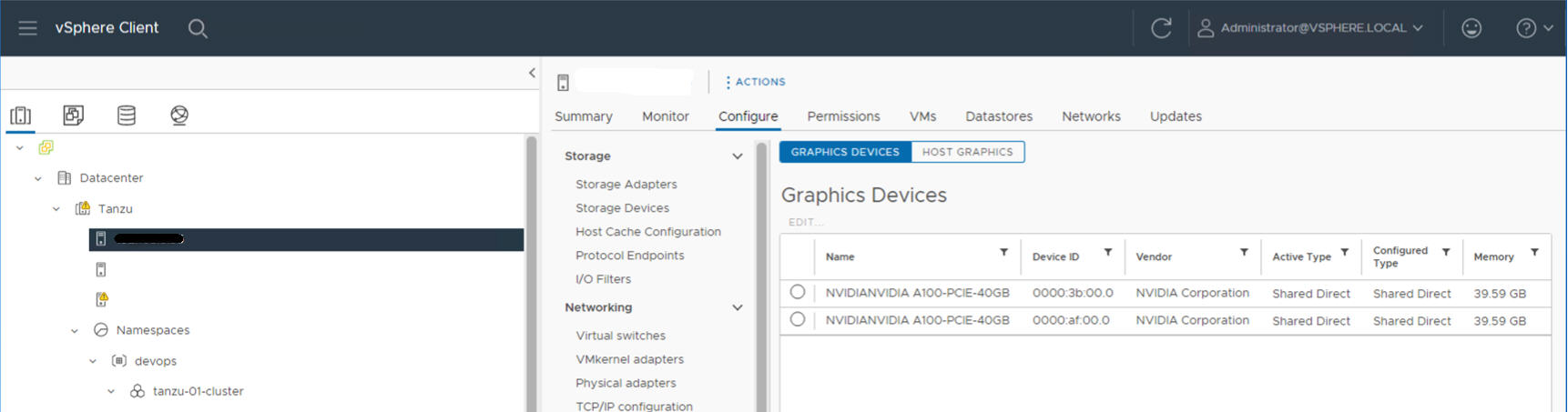
Schritt 2 für Administratoren: Konfigurieren aller ESXi-Hosts für vGPU-Vorgänge
Konfigurieren Sie alle ESXi-Hosts für vGPU, indem Sie „Direkt freigegeben“ und „SR-IOV“ aktivieren.
Aktivieren von „Direkt freigegeben“ auf allen ESXi-Hosts
Aktivieren Sie zum Entsperren der NVIDIA vGPU-Funktion den Modus Direkt freigegeben auf allen ESXi-Hosts, aus denen sich der vCenter-Cluster zusammensetzt, auf dem Arbeitslastverwaltung aktiviert wird.
- Melden Sie sich beim vCenter Server mithilfe des vSphere Client an.
- Wählen Sie einen ESXi-Host im vCenter-Cluster aus.
- Wählen Sie aus.
- Wählen Sie das Gerät für die NVIDIA GPU-Beschleunigung aus.
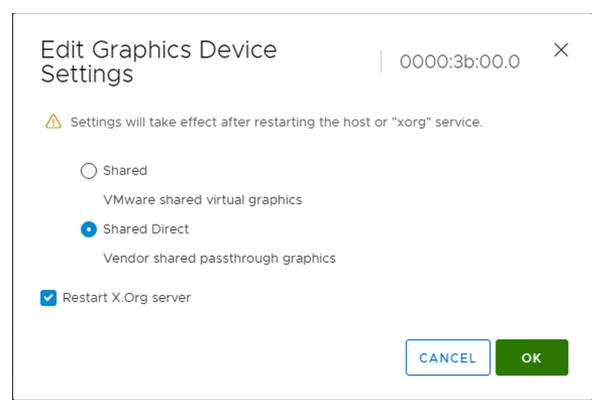
- Bearbeiten Sie die Einstellungen des Grafikgeräts.
- Wählen Sie Direkt freigegeben aus.
- Wählen Sie X.Org-Server neu starten aus.
- Klicken Sie auf OK, um die Konfiguration zu speichern.
- Klicken Sie mit der rechten Maustaste auf den ESXi-Host und versetzen Sie ihn in den Wartungsmodus.
- Starten Sie den Host neu.
- Wenn der Host erneut ausgeführt wird, beenden Sie den Wartungsmodus.
- Wiederholen Sie diesen Vorgang für alle ESXi-Hosts im vCenter-Cluster, in dem Arbeitslastverwaltung aktiviert ist.
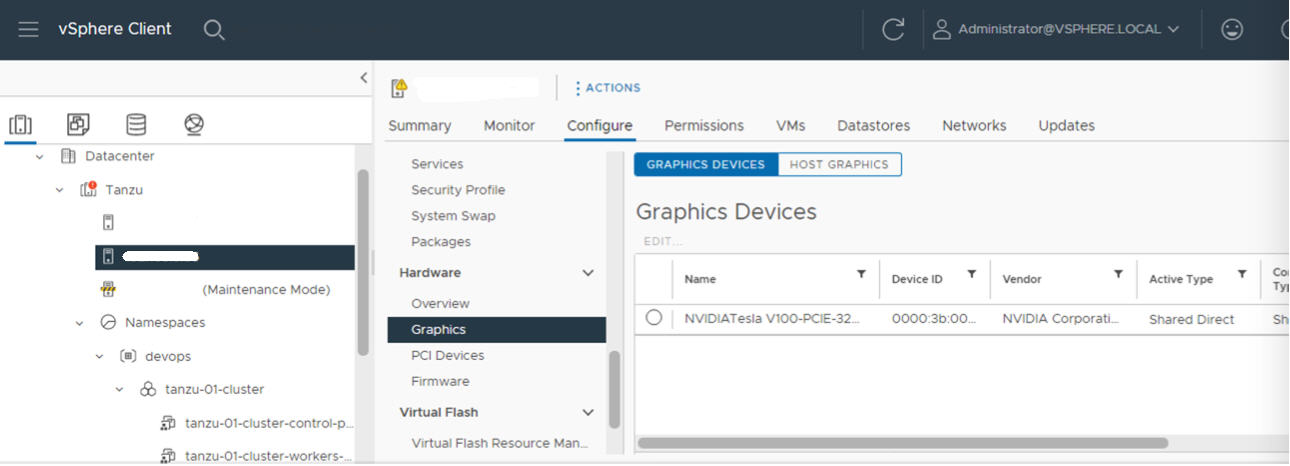
Einschalten von SR-IOV BIOS für NVIDIA GPU A30- und A100-Geräte
Wenn Sie NVIDIA A30- oder A100-GPU-Geräte verwenden, die für GPU mit mehreren Instanzen (MIG-Modus) benötigt werden, müssen Sie SR-IOV auf dem ESXi-Host aktivieren. Wenn SR-IOV nicht aktiviert ist, können Tanzu Kubernetes-Clusterknoten-VMs nicht gestartet werden. In diesem Fall wird die folgende Fehlermeldung im Bereich Aktuelle Aufgaben des vCenter Server angezeigt, für den Arbeitslastverwaltung aktiviert ist.
Could not initialize plugin libnvidia-vgx.so for vGPU nvidia_aXXX-xx. Failed to start the virtual machine. Module DevicePowerOn power on failed.
Melden Sie sich zum Aktivieren von SR-IOV über die Webkonsole beim ESXi-Host an. Wählen Sie aus. Wählen Sie das NVIDIA GPU-Gerät aus und klicken Sie auf SR-IOV konfigurieren. An dieser Stelle können Sie SR-IOV aktivieren. Weitere Informationen finden Sie unter Single Root I/O Virtualization (SR-IOV) in der vSphere-Dokumentation.
Schritt 3 für Administratoren: Installieren des Treibers für den NVIDIA-Hostmanager auf allen ESXi-Hosts
Zum Ausführen von Tanzu Kubernetes-Clusterknoten-VMs mit der NVIDIA vGPU-Grafikbeschleunigung installieren Sie den Treiber des NVIDIA-Hostmanagers auf allen ESXi-Hosts, aus denen sich der vCenter-Cluster zusammensetzt, in dem Arbeitslastverwaltung aktiviert wird.
Die Treiberkomponenten des NVIDIA vGPU-Hostmanagers sind in einem vSphere-Installationspaket (VIB) enthalten. Das NVAIE-VIB wird Ihnen von Ihrer Organisation über das NVIDIA GRID-Lizenzierungsprogramm zur Verfügung gestellt. VMware stellt NVAIE-VIBs weder bereit noch können diese heruntergeladen werden. Im Rahmen des NVIDIA-Lizenzierungsprogramms richtet Ihre Organisation einen Lizenzierungsserver ein. Weitere Informationen finden Sie in der Kurzanleitung der Virtual GPU-Software von NVIDIA.
esxcli system maintenanceMode set --enable true esxcli software vib install -v ftp://server.domain.example.com/nvidia/signed/NVIDIA_bootbank_NVIDIA-VMware_ESXi_7.0_Host_Driver_460.73.02-1OEM.700.0.0.15525992.vib esxcli system maintenanceMode set --enable false /etc/init.d/xorg restart
Schritt 4 für Administratoren: Sicherstellen, dass ESXi-Hosts für NVIDIA vGPU-Vorgänge zur Verfügung stehen
- Melden Sie sich per SSH beim ESXi-Host an, wechseln Sie in den Shell-Modus und führen Sie den Befehl
nvidia-smiaus. Bei der NVIDIA-Systemverwaltungsschnittstelle handelt es sich um ein Befehlszeilendienstprogramm, das vom NVIDIA vGPU-Hostmanager bereitgestellt wird. Wenn Sie diesen Befehl ausführen, werden die GPUs und Treiber auf dem Host zurückgegeben. - Führen Sie den folgenden Befehl aus, um sicherzustellen, dass der NVIDIA-Treiber ordnungsgemäß installiert ist:
esxcli software vib list | grep NVIDA. - Stellen Sie sicher, dass der Host mit „Direkt freigegeben“ für GPU konfiguriert und SR-IOV eingeschaltet ist (bei Verwendung von NVIDIA A30- oder A100-Geräten).
- Erstellen Sie mithilfe des vSphere Clients auf dem für GPU konfigurierten ESXi-Host eine neue virtuelle Maschine mit einem im Lieferumfang enthaltenen PCI-Gerät. Das NVIDIA vGPU-Profil sollte angezeigt werden und auswählbar sein.
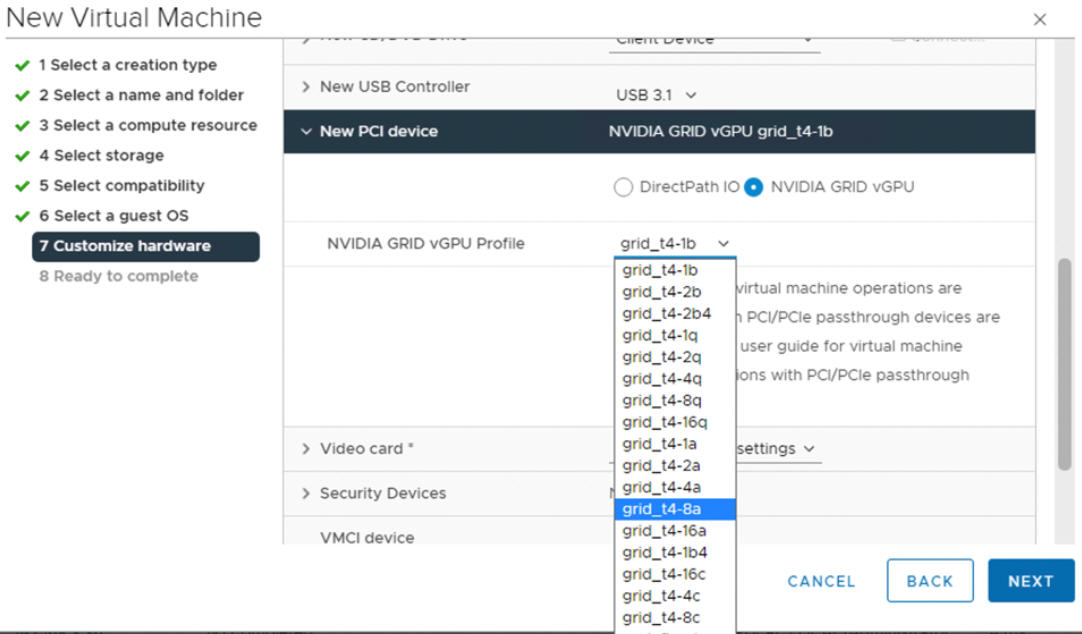
Schritt 5 für Administratoren: Aktivieren der Arbeitslastverwaltung auf dem für vGPU konfigurierten vCenter-Cluster
Da die ESXi-Hosts nun für die Unterstützung von NVIDIA vGPU konfiguriert sind, erstellen Sie einen aus diesen Hosts bestehenden vCenter-Cluster. Zur Unterstützung der Arbeitslastverwaltung muss der vCenter-Cluster bestimmte Anforderungen erfüllen, gemeinsam genutzter Speicher, Hochverfügbarkeit und vollautomatisierter DRS eingeschlossen.
Zur Aktivierung der Arbeitslastverwaltung muss auch ein Netzwerk-Stack (ein natives vSphere vDS- oder NSX-T Data Center-Netzwerk) ausgewählt werden. Bei Verwendung eines vDS-Netzwerks müssen Sie einen Lastausgleichsdienst (NSX Advanced oder HAProxy) installieren.
| Aufgabe | Anleitung |
|---|---|
| Erstellen eines vCenter-Clusters, der die Anforderungen für die Aktivierung der Arbeitslastverwaltung erfüllt | Voraussetzungen für die Konfiguration von vSphere with Tanzu in einem vSphere-Cluster |
| Konfigurieren des Netzwerks für den Supervisor-Cluster (entweder NSX-T oder vDS) mit einem Lastausgleichsdienst | Konfigurieren von NSX-T Data Center für vSphere with Tanzu. Konfigurieren des vSphere-Netzwerks und NSX Advanced Load Balancer für vSphere with Tanzu. Konfigurieren des vSphere-Netzwerks und des HAProxy-Lastausgleichsdienst für vSphere with Tanzu. |
| Aktivieren der Arbeitslastverwaltung |
Aktivieren der Arbeitslastverwaltung mit NSX-T Data Center-Netzwerk. |
Schritt 6 für Administratoren: Erstellen oder Aktualisieren einer Inhaltsbibliothek mit der Tanzu Kubernetes Ubuntu-Version
Das Ubuntu-Betriebssystem wird für NVIDIA vGPU benötigt. VMware stellt für solche Zwecke eine Ubuntu-OVA bereit. Sie können die PhotonOS Tanzu Kubernetes-Version nicht für vGPU-Cluster verwenden.
| Inhaltsbibliothektyp | Beschreibung |
|---|---|
| Erstellen Sie unter Abonnierte Inhaltsbibliothek eine Inhaltsbibliothek und synchronisieren Sie die Ubuntu-OVA automatisch mit Ihrer Umgebung. | Erstellen, Sichern und Synchronisieren einer abonnierten Inhaltsbibliothek für Tanzu Kubernetes-Versionen |
| Erstellen Sie unter Lokale Inhaltsbibliothek eine Inhaltsbibliothek und laden Sie die Ubuntu-OVA manuell in Ihre Umgebung hoch. | Erstellen, Sichern und Synchronisieren einer lokalen Inhaltsbibliothek für Tanzu Kubernetes-Versionen |

Schritt 7 für Administratoren: Erstellen einer benutzerdefinierten VM-Klasse mit dem vGPU-Profil
Im nächsten Schritt erstellen Sie eine benutzerdefinierte VM-Klasse mit einem vGPU-Profil. Das System verwendet diese Klassendefinition beim Erstellen der Tanzu Kubernetes-Clusterknoten.
- Melden Sie sich mithilfe des vSphere Clients beim vCenter Server an.
- Wählen Sie Arbeitslastverwaltung aus.
- Wählen Sie Dienste aus.
- Wählen Sie VM-Klassen aus.
- Klicken Sie auf VM-Klasse erstellen.
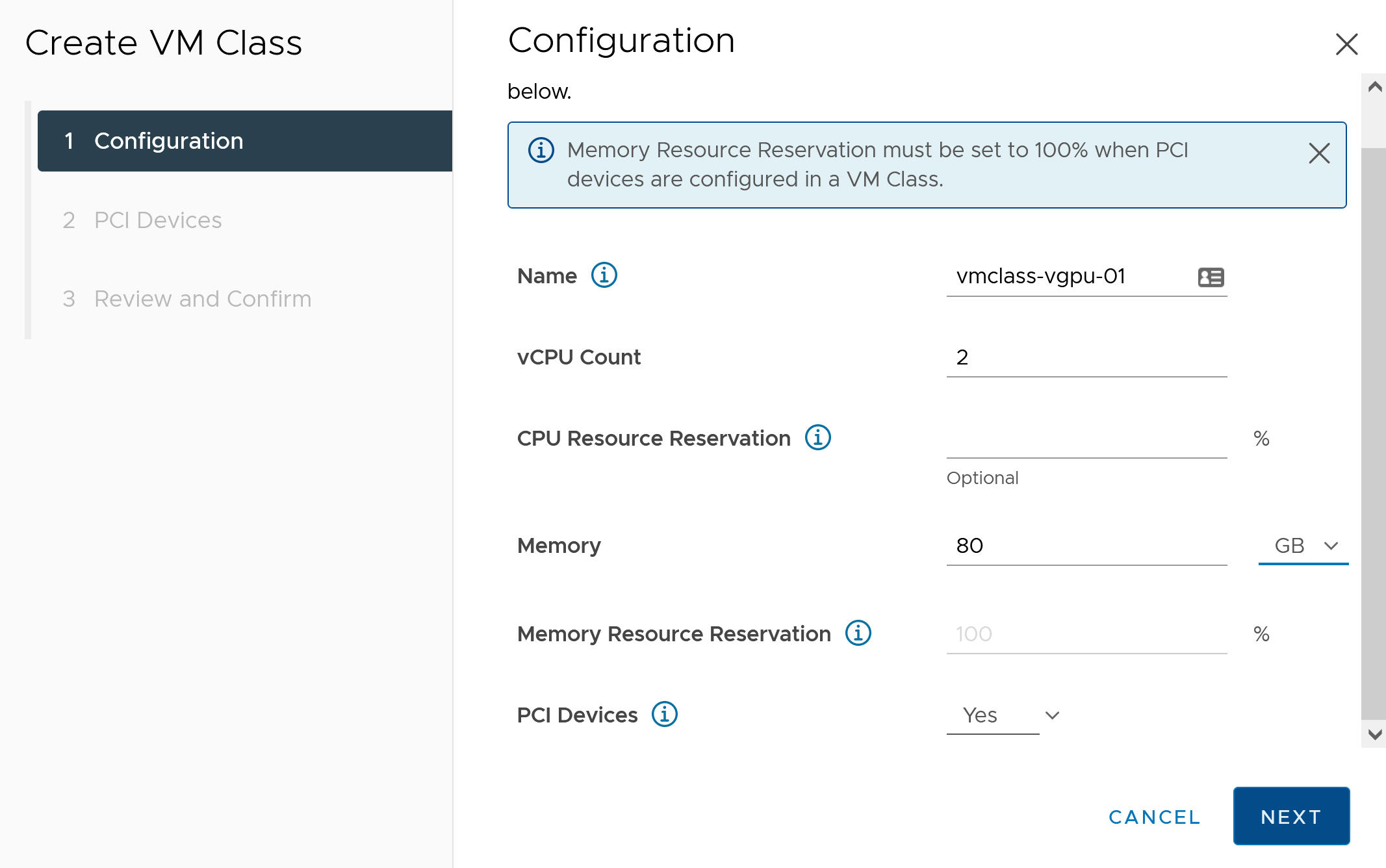
- Konfigurieren Sie auf der Registerkarte Konfiguration die benutzerdefinierte VM-Klasse.
Konfigurationsfeld Beschreibung Name Geben Sie einen selbsterklärenden Namen für die benutzerdefinierte VM-Klasse ein, wie z. B. vmclass-vgpu-1. vCPU-Anzahl 2 CPU-Ressourcenreservierung Optional, kann leer gelassen werden Arbeitsspeicher 80 GB, z. B. Arbeitsspeicher-Ressourcenreservierung 100 % (obligatorisch, wenn PCI-Geräte in einer VM-Klasse konfiguriert werden) PCI-Geräte Ja Hinweis: Bei Auswahl von „Ja“ für PCI-Geräte wird das System darüber informiert, dass Sie ein GPU-Gerät verwenden. Darüber hinaus wird die VM-Klassenkonfiguration zur Unterstützung der vGPU-Konfiguration geändert.Beispiel:
- Klicken Sie auf Weiter.
- Wählen Sie auf der Registerkarte PCI-Geräte die Option aus.
- Konfigurieren Sie das NVIDIA vGPU-Modell.
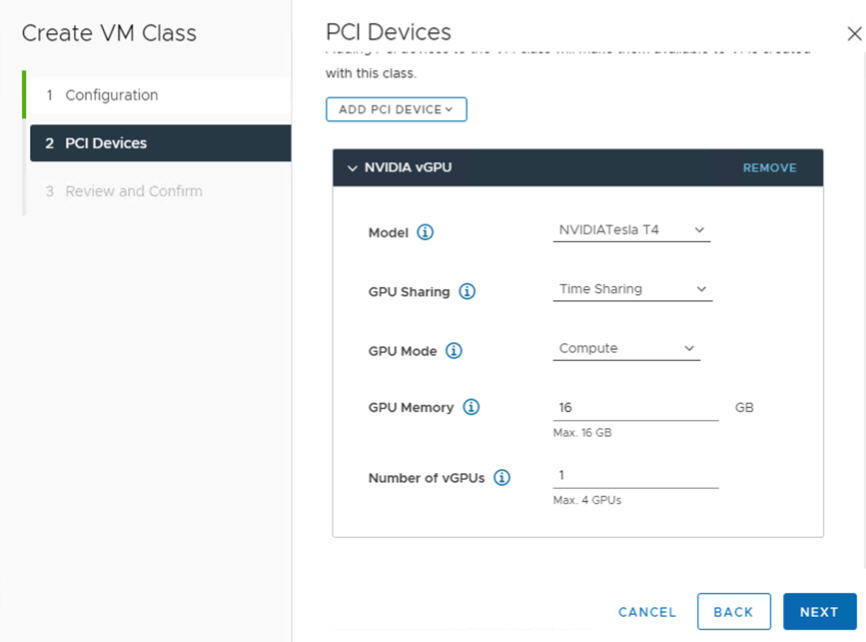
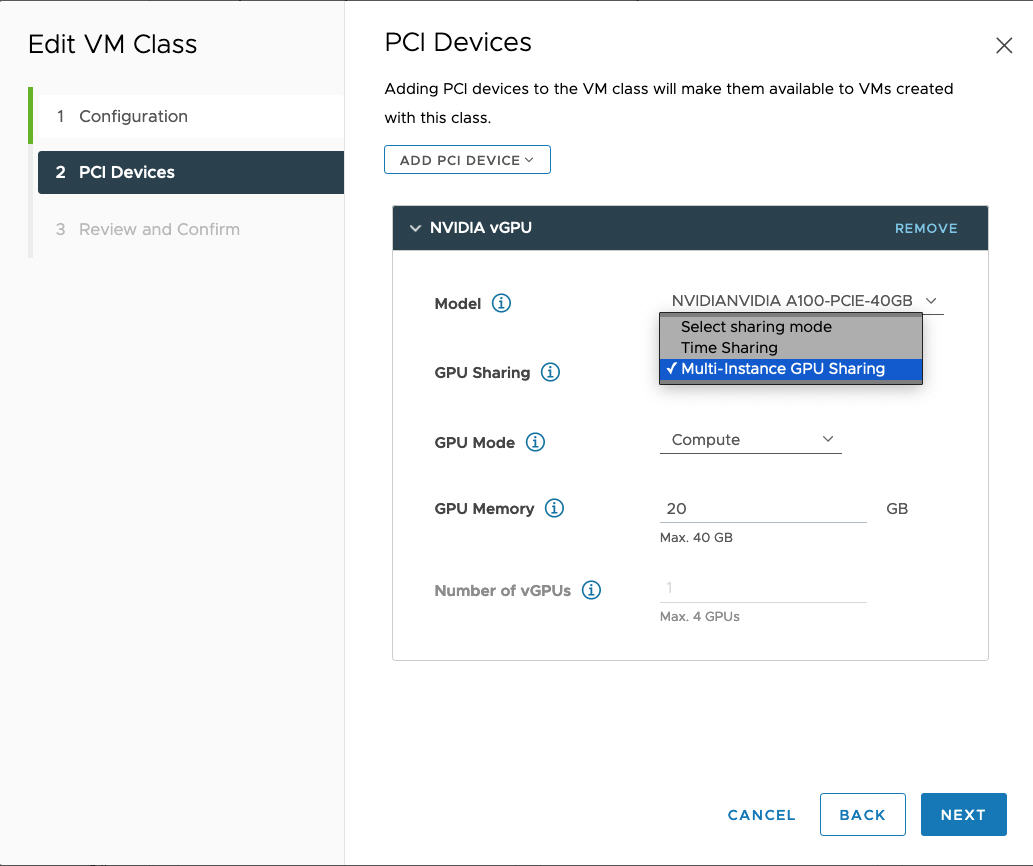
Feld „NVIDIA vGPU“ Beschreibung Modell Wählen Sie im Menü das Modell des NVIDIA GPU-Hardwaregeräts aus. Wenn im System keine Profile angezeigt werden, verfügt keiner der Hosts im Cluster über unterstützte PCI-Geräte. GPU-Freigabe Mit dieser Einstellung wird die Freigabe des GPU-Geräts für GPU-fähige VMs festgelegt. Zwei Arten von vGPU-Implementierungen stehen zur Verfügung: Timesharing und GPU-Freigabe mehrerer Instanzen.
Im Modus „Timesharing“ weist der vGPU-Scheduler die GPU an, die Arbeit für jede vGPU-fähige VM fortlaufend über einen längeren Zeitraum durchzuführen, um die Leistung bestmöglich auf die vGPUs zu verteilen.
Im MIG-Modus können mehrere vGPU-fähige VMs gleichzeitig auf einem einzelnen GPU-Gerät ausgeführt werden. Der MIG-Modus basiert auf einer neueren GPU-Architektur und wird nur auf NVIDIA A100- und A30-Geräten unterstützt. Wenn die MIG-Option nicht angezeigt wird, wird sie vom ausgewählten PCI-Gerät nicht unterstützt.
GPU-Modus Computing GPU-Arbeitsspeicher 8 GB, z. B. Anzahl der vGPUs 1, z. B. Beispiel: Hierbei handelt es sich um ein NVIDIA vGPU-Profil, das im Modus „Timesharing“ konfiguriert ist:
Beispiel: Hierbei handelt es sich um ein NVIDIA vGPU-Profil, das im MIG-Modus mit einem unterstützten GPU-Gerät konfiguriert ist:
- Klicken Sie auf Weiter.
- Überprüfen und bestätigen Sie Ihre Auswahl.
- Klicken Sie auf Beenden.
- Stellen Sie sicher, dass die neue benutzerdefinierte VM-Klasse in der Liste der VM-Klassen verfügbar ist.
Schritt 8 für Administratoren: Erstellen und Konfigurieren eines vSphere-Namespace für den TKGS GPU-Cluster
Erstellen Sie einen vSphere-Namespace für jeden bereitzustellenden TKGS GPU-Cluster. Konfigurieren Sie den Namespace, indem Sie einen vSphere SSO-Benutzer mit Bearbeitungsberechtigungen hinzufügen und eine Speicherrichtlinie für dauerhafte Volumes anhängen.
Weitere Informationen hierzu finden Sie unter Erstellen und Konfigurieren eines vSphere-Namespace
Schritt 9 für Administratoren: Verknüpfen der Inhaltsbibliothek und der VM-Klasse mit dem vSphere-Namespace
| Aufgabe | Beschreibung |
|---|---|
| Verknüpfen der Inhaltsbibliothek mit der Ubuntu-OVA für vGPU und dem vSphere-Namespace, in dem Sie den TKGS-Cluster bereitstellen. | Weitere Informationen finden Sie unter Konfigurieren eines vSphere-Namespace für Tanzu Kubernetes-Versionen. |
| Verknüpfen der benutzerdefinierten VM-Klasse mit dem vGPU-Profil und dem vSphere-Namespace, in dem Sie den TKGS-Cluster bereitstellen. | Weitere Informationen finden Sie unter Zuordnen einer VM-Klasse zu einem Namespace in vSphere with Tanzu. |
Schritt 10 für Administratoren: Sicherstellen, dass Zugriff auf den Supervisor-Cluster besteht
Mithilfe der letzten Verwaltungsaufgabe wird sichergestellt, dass der Supervisor-Cluster bereitgestellt wird und vom Cluster-Operator zur Bereitstellung eines TKGS-Clusters für KI-/ML-Arbeitslasten verwendet werden kann.
- Laden Sie die Kubernetes-CLI-Tools für vSphere herunter und installieren Sie sie.
Weitere Informationen finden Sie unter Herunterladen und Installieren von Kubernetes-CLI-Tools für vSphere.
- Stellen Sie eine Verbindung mit dem Supervisor-Cluster her.
Weitere Informationen finden Sie unter Herstellen einer Verbindung mit dem Supervisor-Cluster als vCenter Single Sign-On-Benutzer.
- Stellen Sie den Cluster-Operator mit dem Link zum Herunterladen der Kubernetes-CLI-Tools für vSphere und den Namen des vSphere-Namespace bereit.
Weitere Informationen finden Sie unter Cluster-Operator-Workflow für die Bereitstellung von KI-/ML-Arbeitslasten auf TKGS-Clustern.
